



Dify Workflow
因其用户友好的设置和强大的功能而被广泛使用。然而,之前的版本以串行方式执行步骤,必须等待每个节点完成后才能进入下一个节点。虽然这种方式提供了清晰的结构,但在处理复杂任务时会减慢处理速度,增加了延迟和响应时间。
Dify v0.8.0 通过引入并行处理能力解决了这些限制。现在,Workflow 可以同时执行多个分支,从而实现不同任务的并行处理。这显著提高了执行效率,使大语言模型(LLM)应用能够更快、更灵活地处理复杂工作负载。
创建并行分支
要在 Workflow 中定义并行分支,请按照以下步骤操作:
- 将鼠标悬停在某个节点上。
- 点击出现的“+”图标。
- 添加不同类型的节点。
分支将并行执行,并将其输出合并。更多详细说明请参考文档。
Workflow 包含多种并行场景。尝试这些场景以加速流程。如果您之前在早期版本中构建过 Workflow,可以考虑通过并行模式重新设计它们以提升性能。
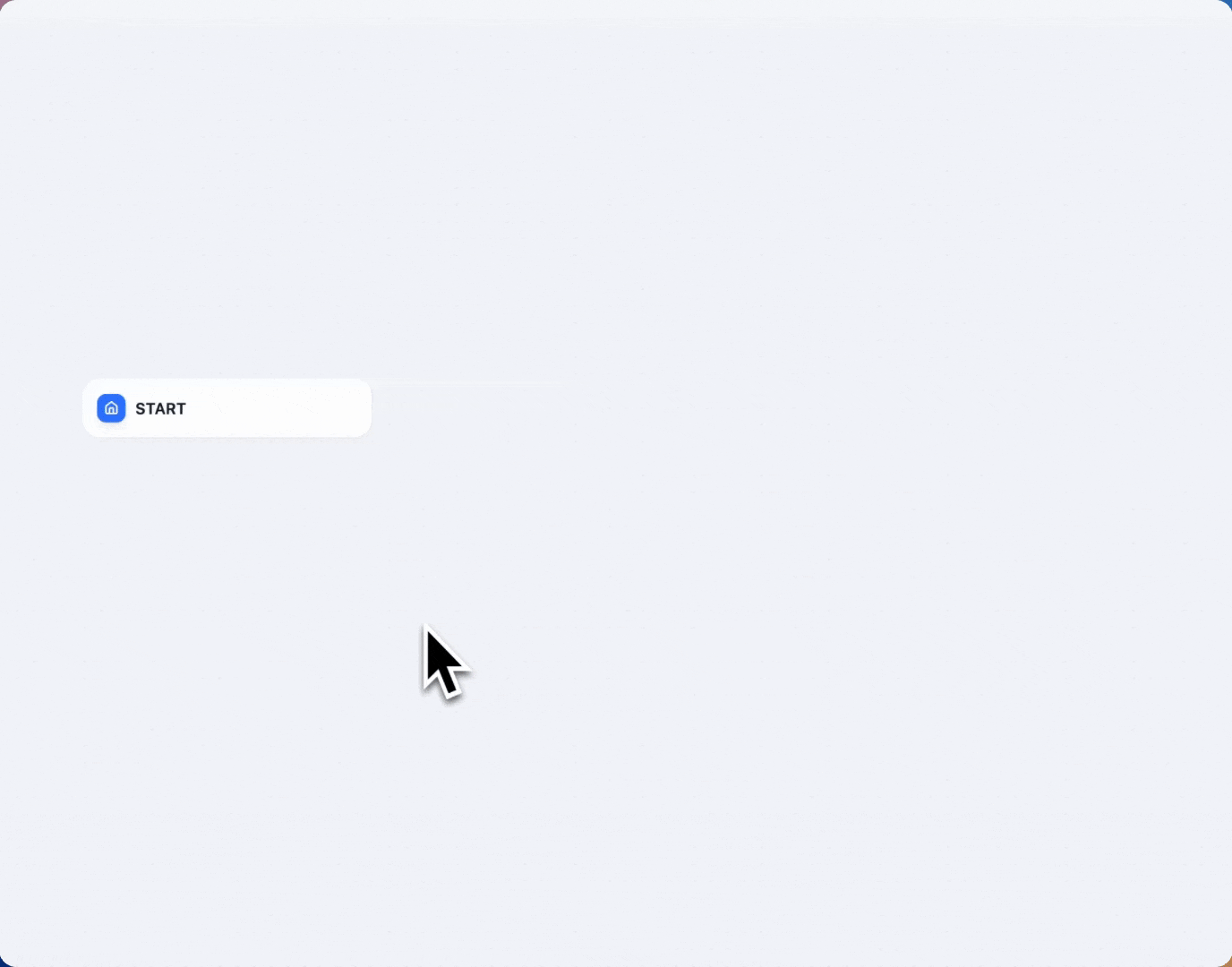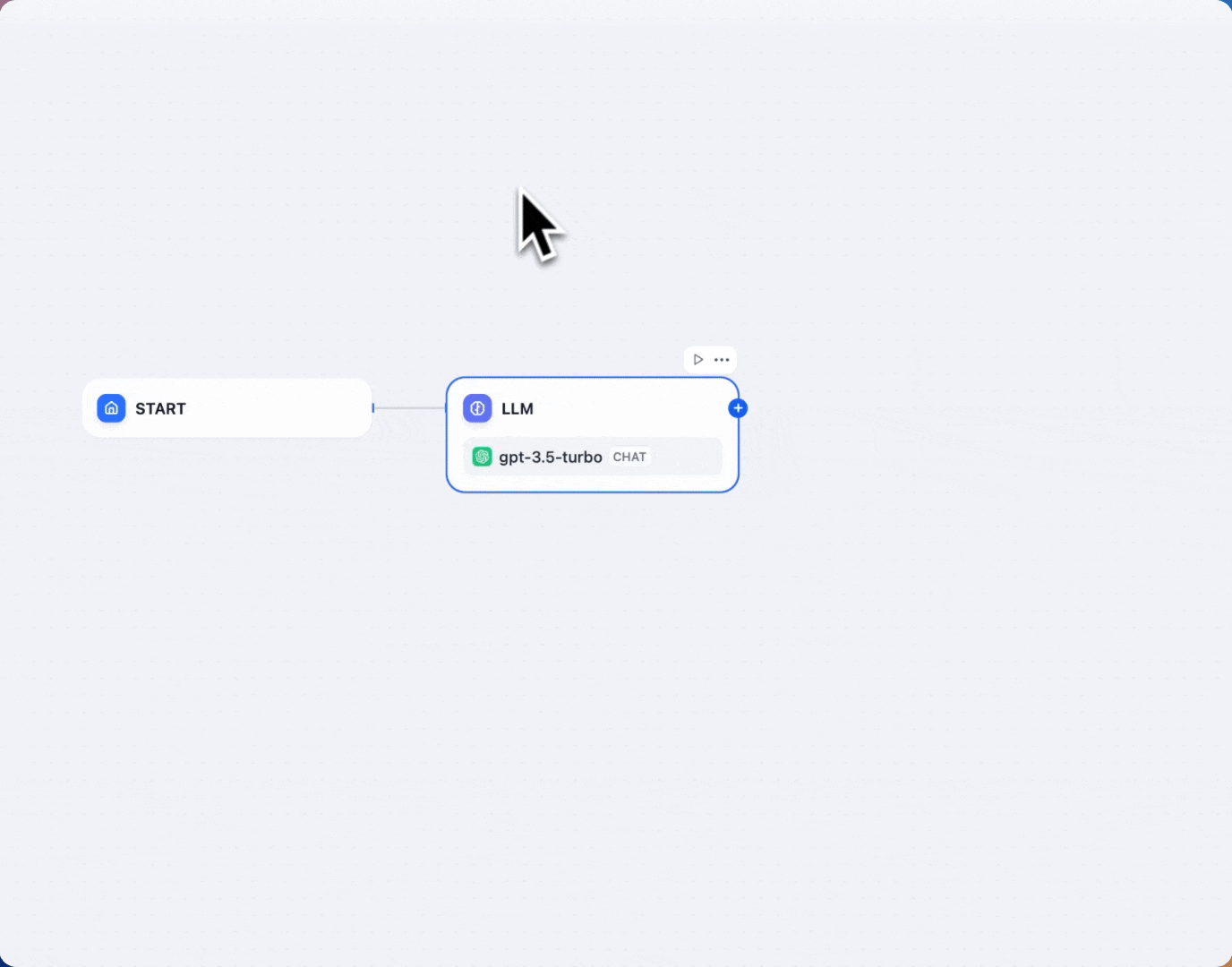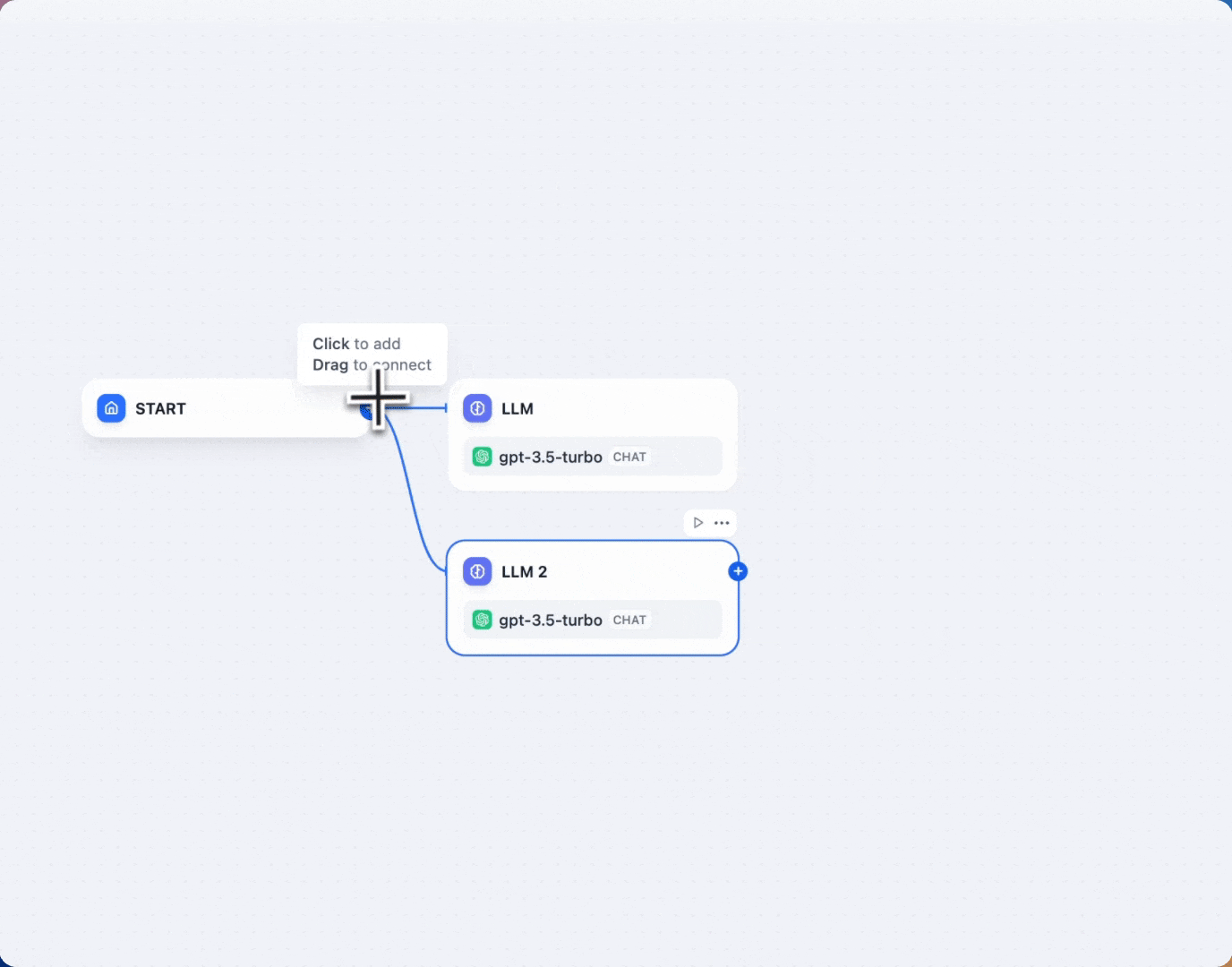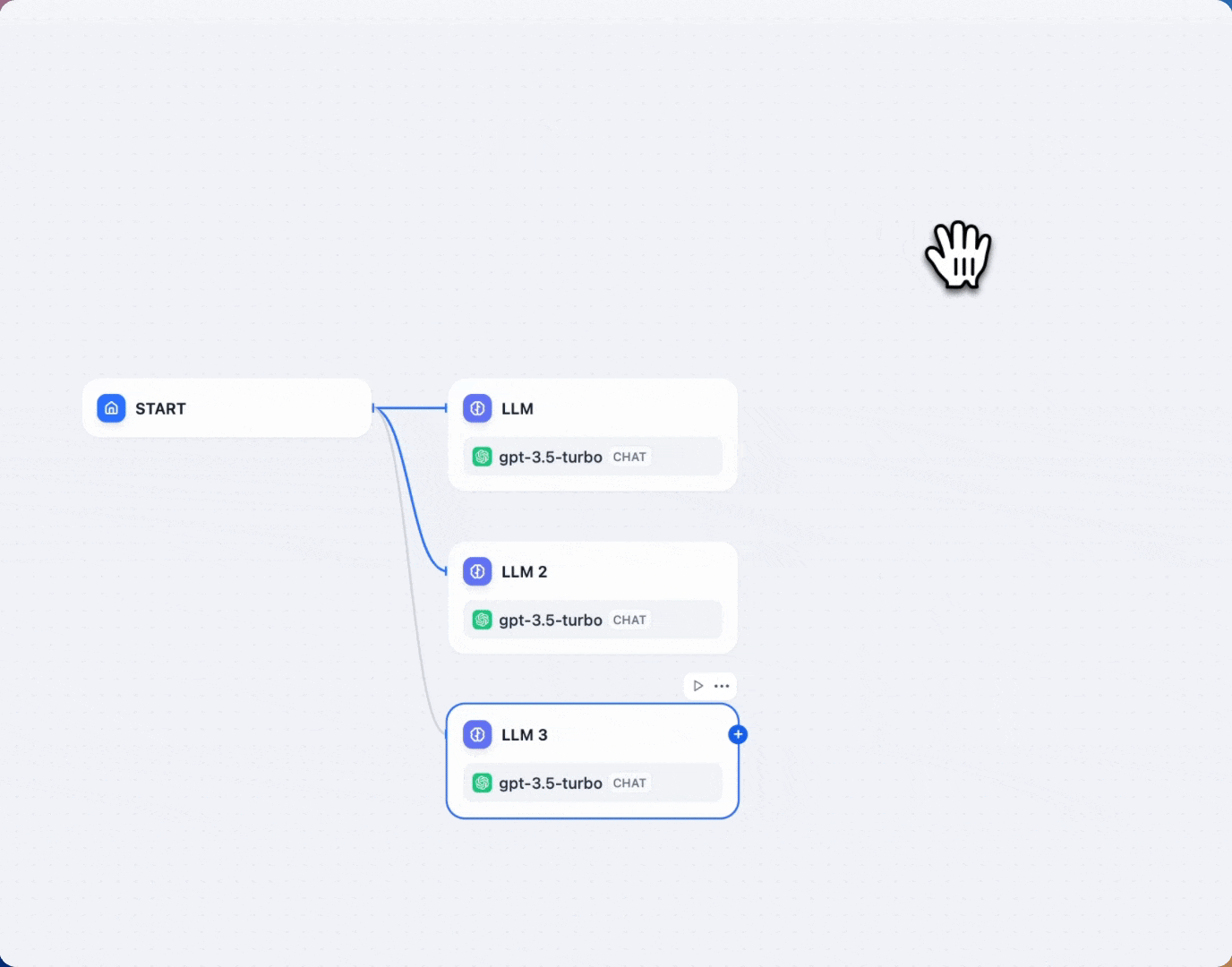
简单并行
对于基本场景,从一个固定节点(例如起始节点)创建多个并行分支。这种设置可以同时处理类似的子任务,例如翻译或模型对比。以下视频展示了简单并行在模型对比 Workflow 中的应用:
嵌套并行
嵌套并行允许在 Workflow 中构建多层次的并行结构。从初始节点开始,它会分支为多个并行路径,每条路径本身又包含自己的并行处理过程。“科学写作助手”示例展示了两层嵌套并行:
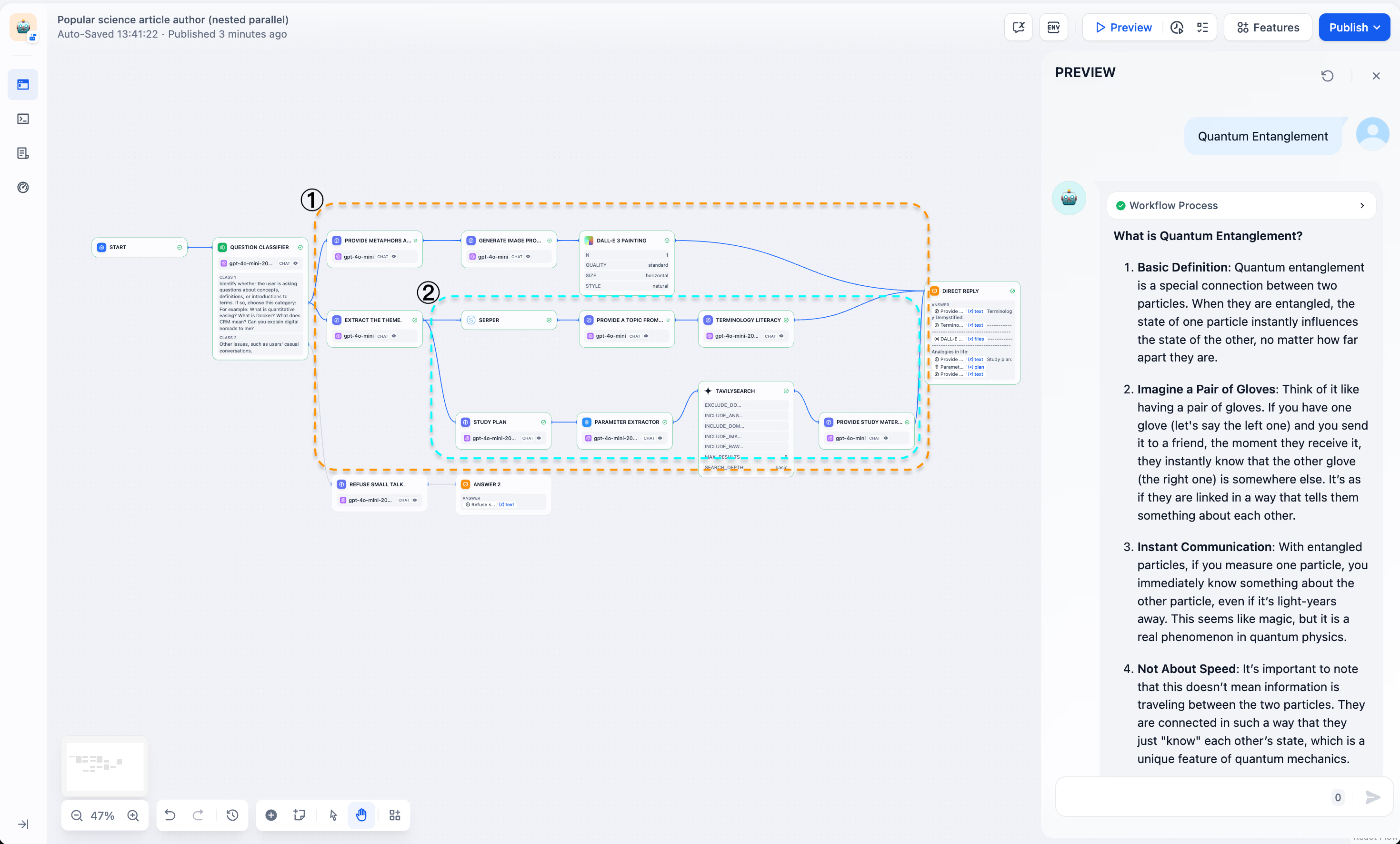
第一层(框1):从问题分类器开始,分出两个主要分支:
a. 概念解释(框1)
b. 处理离题对话(“拒绝闲聊”分支)
概念解释分支(框1)包括:
● 使用隐喻和类比的分支以增强对概念的理解
● 主题提取 | 第二层嵌套(框2),用于详细的概念分析和内容生成
第二层(框2):主题提取分支进行两项并行任务:
a. 提取主题并搜索(提取主题 -> Serper),获取背景信息
b. 提取主题并生成学习计划(学习计划 -> 参数提取器 -> TavilySearch)
这种多层次嵌套的并行结构非常适合复杂的多阶段任务,例如深入的概念分析和科学传播内容的创建。它同时处理不同方面的概念,包括基本解释、类比、背景研究和学习计划,从而提高处理效率和输出质量。
迭代并行
迭代并行涉及在循环结构内的并行处理。“股票新闻情感分析”的例子展示了这种方法:
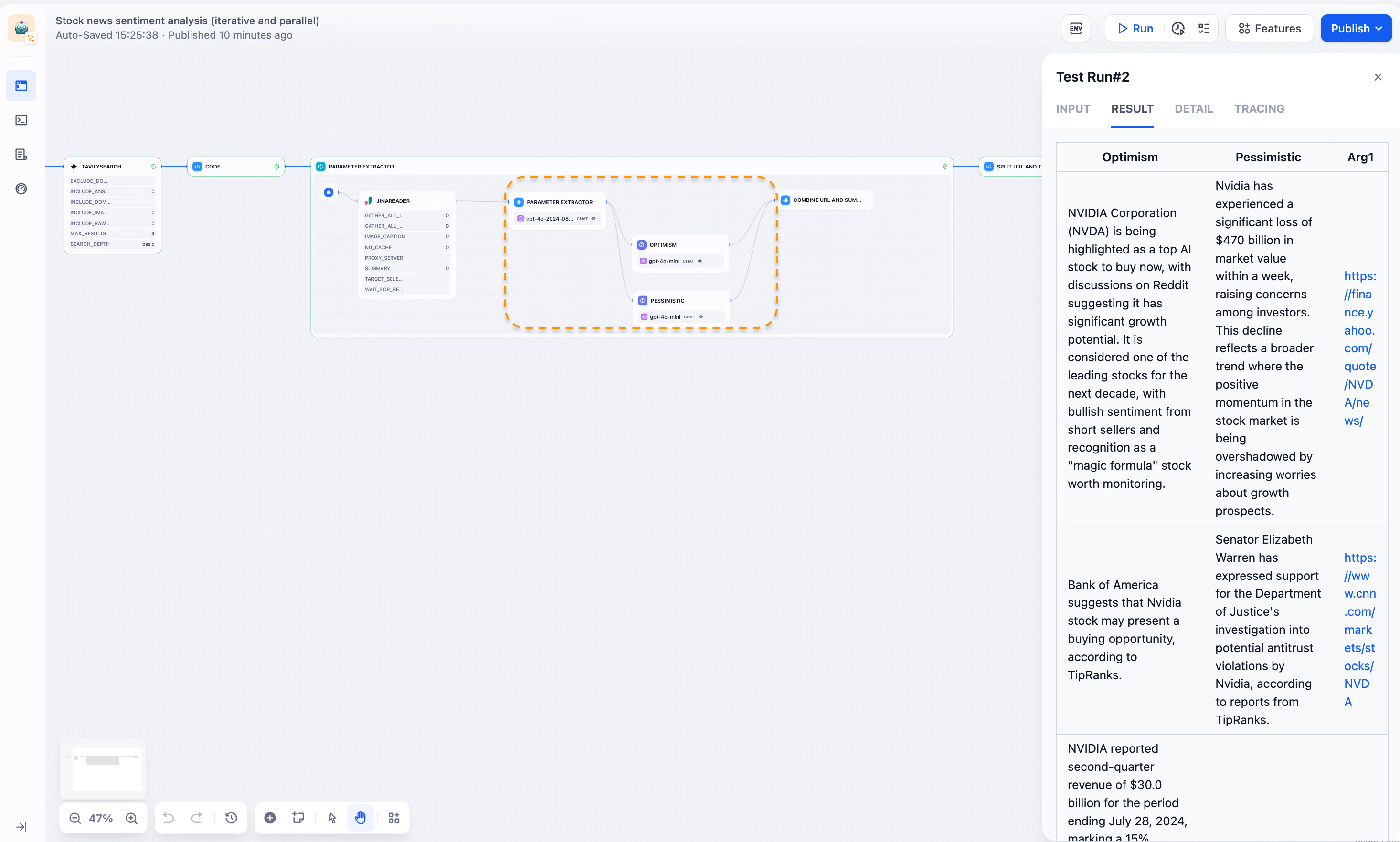
设置:为特定股票搜索并提取多个新闻URL。
迭代处理:对每个URL,并行执行以下任务:
a. 内容检索:使用JinaReader抓取并解析网页内容。
b. 观点提取:使用参数提取器识别乐观和悲观观点。
c. 观点总结:使用两个独立的LLM模型并行总结乐观和悲观观点。
结果整合:将所有发现汇总到一个表格中。
这种方法可以高效处理大量新闻文章,从多个角度分析情感,帮助投资者做出明智决策。迭代内的并行处理加速了具有相似数据结构的任务,节省时间并提高性能。
条件并行
条件分支并行基于条件运行不同的并行任务分支。“面试准备助手”的例子展示了这种设置:
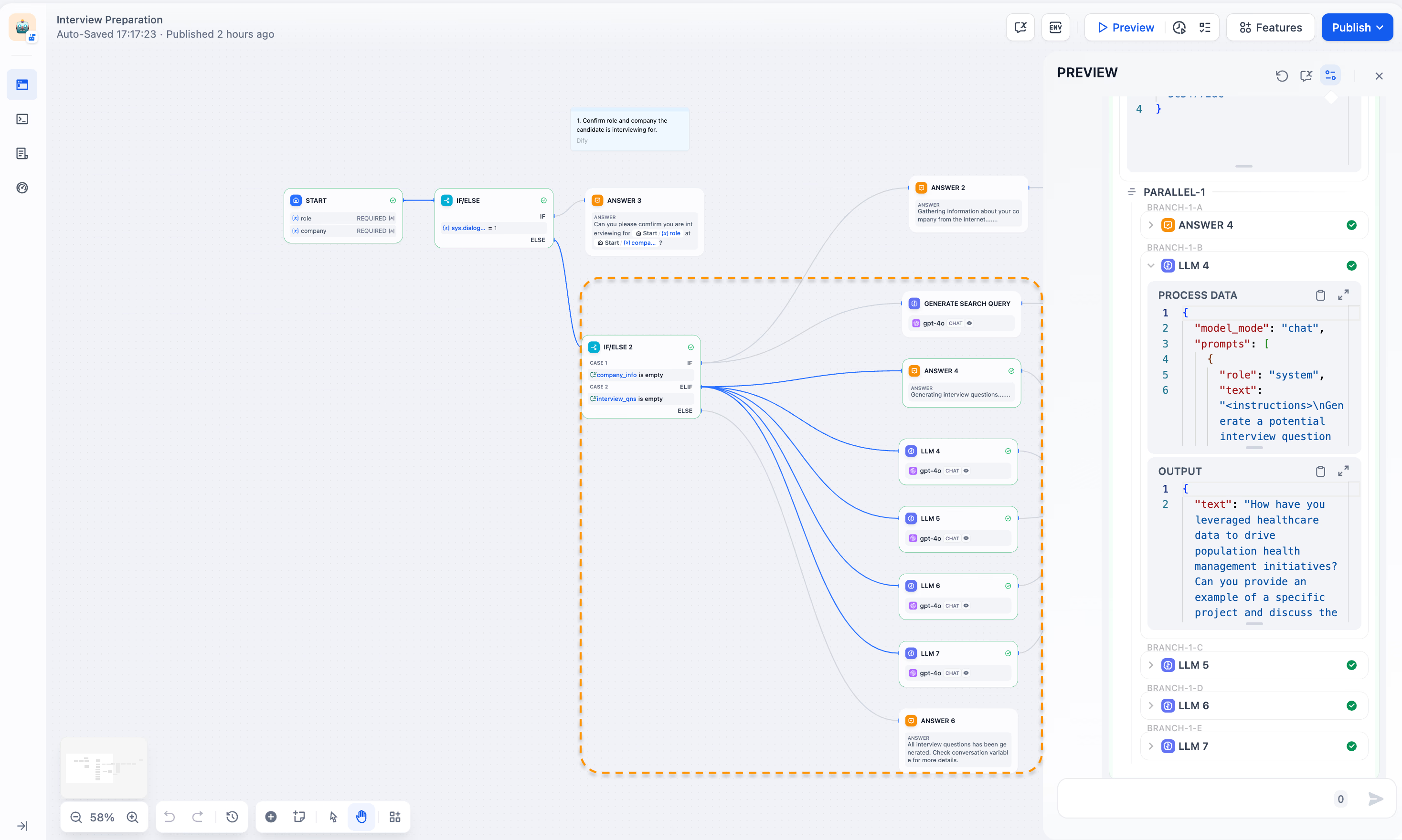
主条件(IF/ELSE节点):根据dialogue_count拆分流程:
a. 第一次对话:确认面试角色和公司
b. 后续对话:进入更深层次的处理
次级条件(IF/ELSE 2节点):在后续对话中,根据现有公司信息和面试问题进行分支:
a. 缺少公司信息:并行执行任务以搜索公司、抓取网页、总结公司信息
b. 缺少面试问题:并行生成多个问题
并行任务执行:对于问题生成,多个LLM节点同时启动,每个节点生成不同的问题。
这种IF/ELSE结构使工作流能够根据当前状态和需求灵活运行不同的并行任务。(问题分类节点也可以起到类似的作用。)这提高了效率,同时保持了条理性。它适用于需要基于各种条件同时处理复杂任务的情况,比如这个面试准备过程。
从工作流并行性中受益
这四种并行方法(简单、嵌套、迭代和条件)提升了Dify工作流的性能。它们支持多模型协作,简化困难任务,并动态调整执行路径。这些升级提高了效率并拓宽了应用范围,更好地应对棘手的工作场景。你可以在探索页面的匹配模板中快速尝试这些新功能。


















 1437
1437




 到【灌水乐园】发言
到【灌水乐园】发言







