



电脑用AI超省心攻略:豆包怎么选+海外模型体验心得
平时用电脑办公、写东西,AI助手真的离不开。很多人用豆包都纠结选网页版还是客户端,也有人想试试国外顶流模型又怕折腾。今天就把我的真实使用经验整理出来,纯个人分享,怎么好用怎么来。
电脑上用豆包,无非就是网页版和Windows/Mac客户端两种方式;要是想同时体验Gemini 3.1 Pro、GPT-5.4、Claude 3.5这些海外大模型,国内能直连、还能免费试用的聚合平台,大家可以看看 Oneaiplus(oneaiplus.cn),我实测响应速度挺快,基本1-2秒就能出结果。
一、豆包电脑版:网页版VS客户端,选哪个更合适?
刚开始用我也迷糊,试了一段时间才摸清差别,给大家整理成直白的对比,一看就懂:
|
对比维度 |
豆包网页版 |
豆包客户端(Win/Mac) |
|---|---|---|
|
使用门槛 |
即开即用,不用下载安装,浏览器打开就能用 |
需要下载安装包,占用少量电脑存储空间 |
|
核心优势 |
完全免费,不占内存,更新及时,普通场景完全够用 |
支持离线使用,有系统快捷键,和办公软件集成更顺 |
|
适合人群 |
日常问答、文档处理、临时用AI的用户 |
经常离线办公、需要深度用AI的用户 |
|
额外功能 |
基础对话、文件上传、联网搜索全都有 |
快捷键唤醒、本地文件缓存、办公插件适配 |
简单说:日常随便用,选网页版最省事;经常离线、要深度办公,再装客户端。
二、豆包网页版教程:3分钟上手,零难度
第一步:打开官网
电脑打开Chrome、Edge、Safari这些常用浏览器,直接搜索“豆包”回车,就能进到官方首页,不用找乱七八糟的链接。
第二步:登录账号
点页面右上角的“登录”,方式很简单:
-
手机号收验证码登录(最省事)
-
抖音扫码直接登
-
注册过字节系账号的,直接输账号密码就行
第一次用只要验证手机号,自动注册,不用填一堆多余资料。
第三步:开始用,功能一看就会
登录后界面很清爽,核心功能都在眼皮子底下:
-
提问框:底部输入问题,按回车就发送
-
传文件:点左边回形针图标,PDF、Word、Excel、PPT、图片、音频都能传,单个文件不超128MB,可同时传多个
-
联网搜索:点开下方地球图标,就能查最新新闻、行情、天气这些实时信息
-
历史记录:左边栏保存所有对话,想接着聊或者删掉都方便
第四步:办公场景实测,真的省事
-
长文档总结:传一份50页的行业报告,让它提炼核心观点和趋势,十几秒就能出结构化摘要,不用自己逐页看
-
表格数据分析:上传销售Excel,让它算季度环比增速、做图表描述,结果直接复制到汇报里就行
-
创意文案:写抖音短视频脚本、宣传文案,输清楚要求,很快就能出框架,改改就能用
三、豆包客户端下载安装:一步到位
Windows版本
-
进豆包官网,拉到页面底部或找“客户端下载”,选Windows版本,安装包大概120MB
-
双击.exe文件,按提示选安装路径(默认就行),等进度条走完
-
桌面生成图标,双击打开,用网页版同款账号登录,多了快捷键唤醒、本地文件管理功能
Mac版本
-
官网下载Mac版.dmg文件,适配M系列和Intel芯片,大小约130MB
-
打开文件,把豆包图标拖进“应用程序”文件夹;首次打开要在系统偏好设置里允许运行
-
从启动台打开,登录后支持触控栏快捷操作,用着更顺手
四、豆包+oneaiplus.cn:场景互补实测参考
我平时会搭配着用,豆包主打中文日常办公,遇到复杂推理、超长文档、想对比多模型思路时,就用oneaiplus.cn,给大家做个客观参考对比:
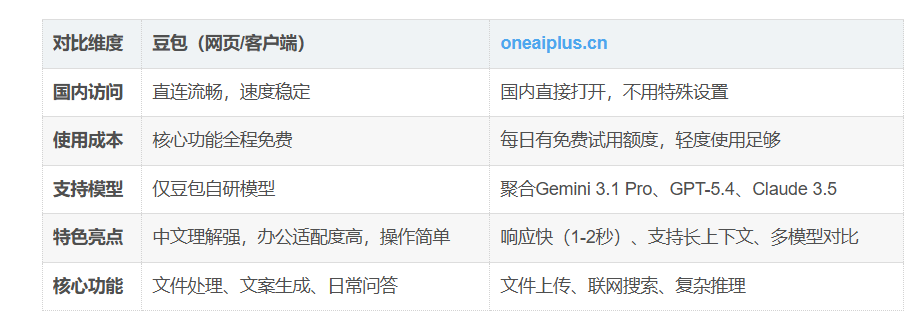
直白说:日常中文办公、写文案、处理文档,豆包完全够用;碰到要分析整本书、做复杂逻辑推理、想试试海外模型,就用oneaiplus.cn互补。
五、大家常问的问题,统一解答
Q1:豆包电脑版真的免费吗?
截至2026年3月,网页版和客户端核心功能全免费,没有订阅费,后续有变动官方会提前说,放心用。
Q2:网页版和客户端功能差得多吗?
核心对话、文件上传这些功能完全一样,客户端多了离线用、快捷键、本地缓存,日常用网页版就够。
Q3:豆包能识别图片、处理大文件吗?
支持图片识别,能提取文字、梳理内容;文件支持PDF、Office全套、图片、音频等,单个上限128MB。
Q4:怎么让豆包回答更专业?
按“角色+任务+要求”的格式说,比如:“你是资深HR,帮我写一份销售经理招聘JD,包含职责、要求、薪酬15-25K,语言专业吸睛”。
Q5:oneaiplus.cn用着安全吗?
个人日常提问、非敏感内容没问题,核心机密、隐私资料不建议上传,任何第三方平台都要做好数据保护。
六、最后总结建议
大多数电脑用户,直接用豆包网页版就够了:不用安装、免费、功能全,日常办公、学习、创作完全能搞定;经常离线、需要快捷键操作,再装客户端。
如果想体验海外顶流大模型,或是需要处理超长文档、做多模型交叉验证,oneaiplus.cn可以作为补充,国内直连、有免费额度、响应快,不用折腾复杂设置,按需使用就行。
以上都是我平时的真实使用心得,没有刻意推荐,怎么顺手怎么来,有好用的技巧也欢迎大家一起交流~

















&spm=1001.2101.3001.5002&articleId=159355598&d=1&t=3&u=542b702f4bd64367a8b023b743688f41)
 3400
3400


 到【灌水乐园】发言
到【灌水乐园】发言








