
本篇文章是 OpenAI ChatGPT 系列文章的第七篇,在上一篇文章中,我们介绍了 GPT-2 的结构和代码实现。
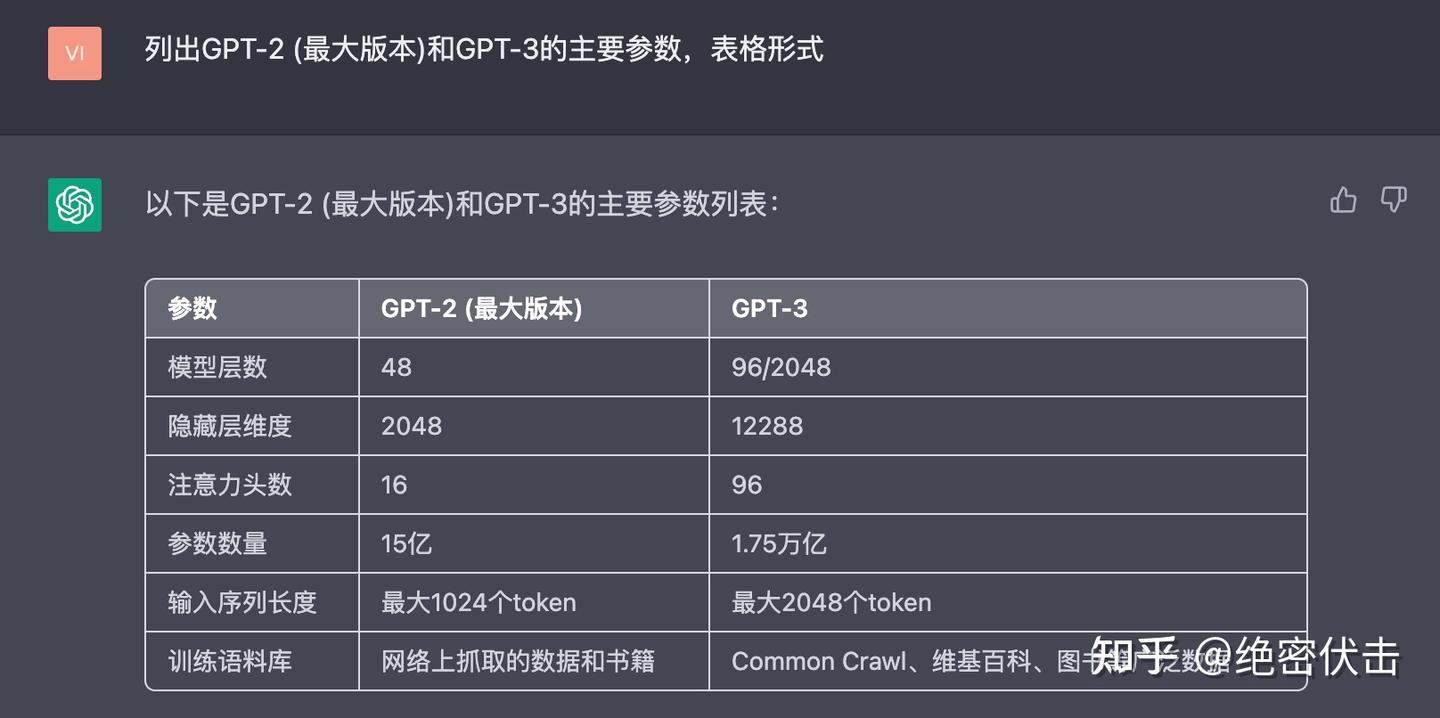
绝密伏击:OpenAI ChatGPT(三):十分钟读懂 GPT-2绝密伏击:OpenAI ChatGPT(三):Tensorflow实现GPT-2GPT-3 相比 GPT-2,模型参数变大了很多,模型参数直接干到了1.75万亿(1750B),是 GPT-2 的1000多倍,如下图所示:
之前的 GPT-1 是在子任务训练时提供少量的训练数据,GPT-2 是处理子任务时不提供任何相关的训练样本,直接使用预训练模型在子任务上面做预测。
最近的研究表明,通过对大量文本进行预训练,然后在特定任务上进行微调(Fine-tuning),可以在许多自然语言处理任务和基准测试中实现显著的提高。虽然在体系结构上通常是与任务无关的,但这种方法仍然需要数千个或数万个示例的特定任务微调数据集。相比之下,人类通常可以从只有几个例子或简单的说明中执行新的语言任务 - 这是当前自然语言处理系统仍然很难做到的。GPT-3 向我们展示了扩展语言模型可以极大地改善无关任务的少样本学习性能,有时甚至可以达到与之前最先进的微调方法相媲美的水平。具体来说,OpenAI 训练了一个自回归语言模型 GPT-3,它有1750亿个参数,是之前任何非稀疏语言模型的10倍,然后在少样本学习的环境中测试其性能。对于所有任务,GPT-3 都没有进行任何梯度更新或微调,任务和少样本演示纯粹是通过与模型的文本交互来指定的。GPT-3 在许多自然语言处理数据集上都取得了强大的表现,包括翻译、问答和填空任务,以及几个需要即时推理或领域适应的任务,例如拼字、在句子中使用新词或进行三位数算术运算。同时,OpenAI 也确定了一些数据集,GPT-3 的少样本学习仍然存在困难,GPT-3 面临着与在大型网络语料库上训练相关的问题。最后,OpenAI 发现 GPT-3 可以生成新闻文章,评估者很难区分其是否由人类编写。
1. 简介
近年来,NLP系统中出现了一种趋势,即采用预训练语言表示进行下游推断,且越来越灵活,并与任务无关。
首先,使用单层表示学习单词向量,并将其输入到特定任务的架构中,然后使用具有多层表示和上下文状态的RNN 来生成更强的表示,最近使用预先训练的 transformer 等语言模型直接进行了微调,完全消除了特定任务的架构。这种最后的范例在许多具有挑战性的 NLP 任务上取得了重大进展,例如阅读理解、问题回答、文本蕴含等。但是,这种方法的一个主要限制是,虽然架构是任务无关的,但仍需要特定任务数据集和特定任务微调:为了在所需任务上获得强大的性能,通常需要在特定任务的数千到数十万个样本的数据集上进行微调。消除这种限制将是非常重要的,原因如下。
首先,从实际的角度来看,每个新任务都需要一个大型标注数据集的需求限制了语言模型的适用性。存在着各种可能的语言任务,包括从纠正语法到生成一个抽象概念的例子,再到批判一篇短篇小说的所有内容。对于许多这些任务,很难收集大型监督训练数据集,特别是当这个过程必须针对每个新任务重复时。
第二个原因,样本没有出现在数据分布里面,大模型的泛化性不见得比小模型更好。微调效果好不能说明预训练模型泛化性好,因为可能是过拟合预训练的训练数据,这些训练数据与微调使用的数据刚好有一定的重合性。
第三个原因是,人类并不需要大量的监督数据集来学习大多数语言任务。通常只需要自然语言中的简短指令(例如“请告诉我这句话描述的是快乐的还是悲伤的事情”),或者最多几个示范(例如“这里有两个人勇敢的例子,请给出第三个勇敢的例子”),就足以使人类能够合理地完成新的任务。除了指出我们当前自然语言处理技术的概念限制外,这种适应性还具有实际优势——它使人类能够轻松地混合或切换许多任务和技能,例如在长时间的对话中进行加法计算。
解决这些问题的一个潜在途径是元学习,即在语言模型的上下文中,模型在训练时发展出广泛的技能和模式识别能力,并在推理时利用这些能力快速适应或识别所需的任务(如图1.1所示)。最近的一项工作试图通过所谓的“in-context learning”来实现这一点,使用预训练语言模型的文本输入作为任务规范的形式:模型被设定在自然语言指令和/或一些任务演示的条件下,然后预测接下来会发生什么来完成进一步的任务实例。
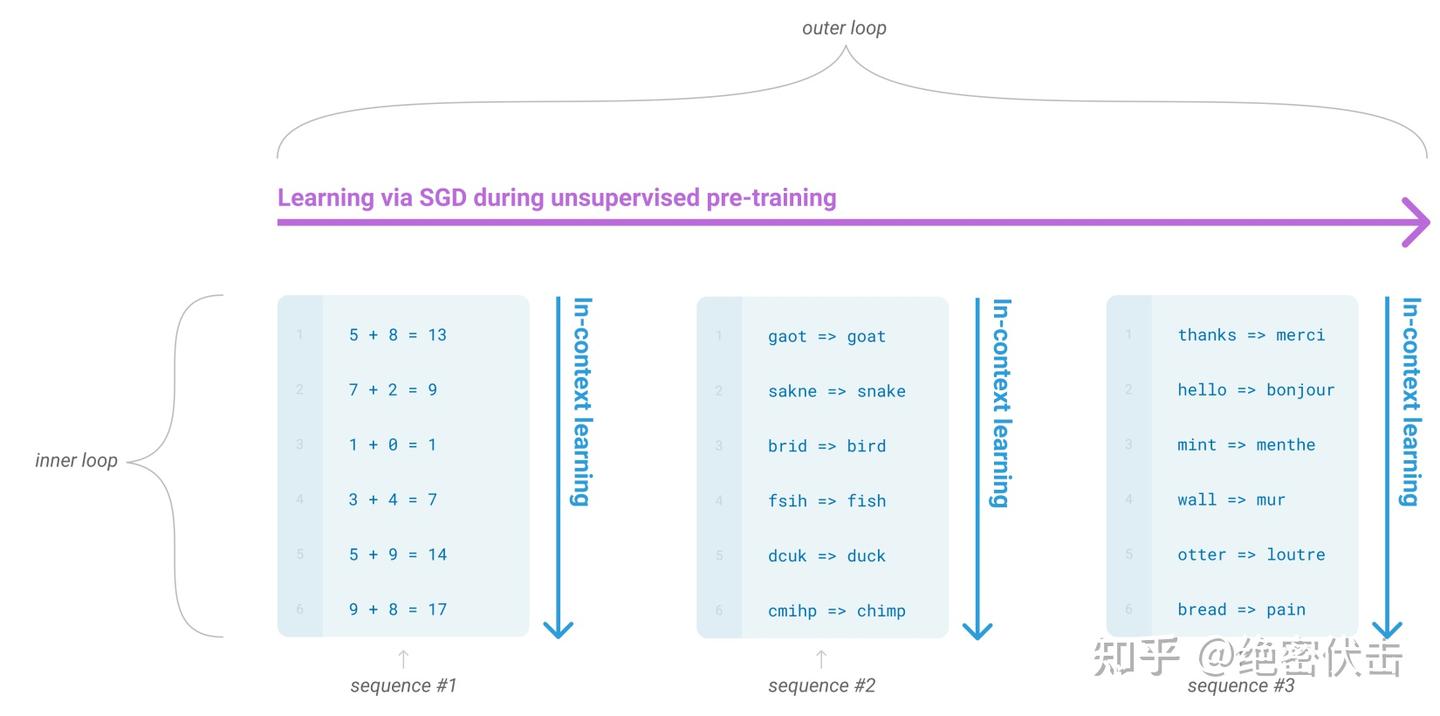
虽然元学习已经显示出一些初步的潜力,但它仍然比微调的结果差很多,例如在自然问题(Natural Questions)上只能达到4%的准确率,即使它的 CoQa F1 值为55,现在也比最先进的技术落后35个多点。显然,元学习需要实质性的改进才能作为解决语言任务的实用方法。
语言建模中的另一个最近趋势可能提供了前进的方式。近年来,Transformer 语言模型的容量大大增加,从1亿个参数,到3亿个参数,再到15亿个参数、80亿个参数、110亿个参数,最后到了170亿个参数。每次增加都带来了文本合成和下游NLP任务的改进,有证据表明,与许多下游任务相关的对数损失(Log Loss)随着规模的增加呈现出平稳的提升趋势。由于上下文学习涉及将许多技能和任务吸收到模型的参数中,因此有可能在不同规模下,上下文学习能力也会有类似的强大收益。
OpenAI 通过训练一个1750亿参数的自回归语言模型,即 GPT-3,来测试这一假设,并测量它的上下文学习能力。具体来说,在 NLP 数据集上对 GPT-3 进行了评估,以及几个旨在测试快速适应训练集中不太可能直接包含的任务的新颖任务。对于每个任务,在3种条件下评估GPT-3的性能:
- “少样本学习(few-shot learning)”,或称为上下文学习,允许尽可能多的样本(通常为10到100个)
- “一个样本学习(one-shot learning)”,只允许一个样本
- “零样本学习(zero-shot learning)”,一个样本也不提供,只给出自然语言的指令给模型。
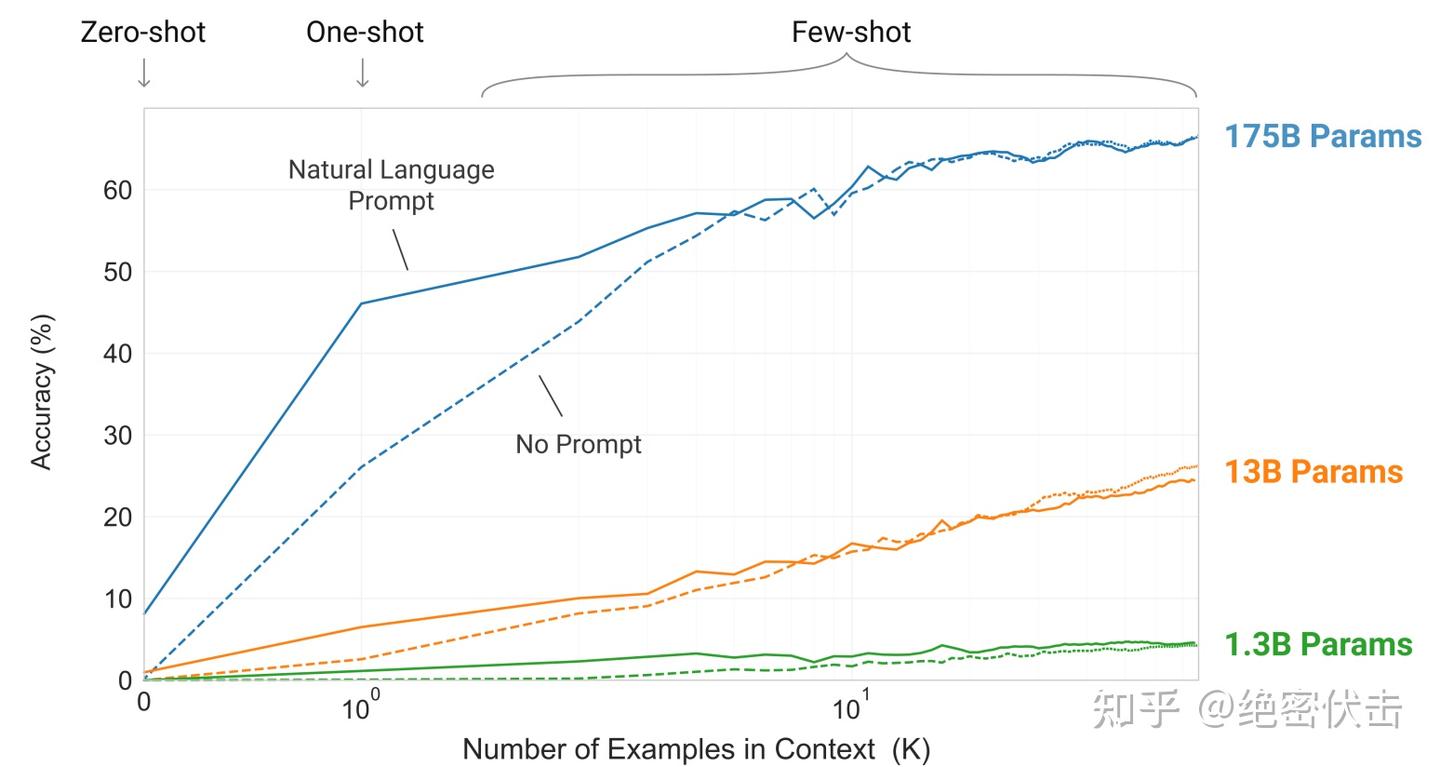
图1.2展示了一个简单任务的 few-shot 学习过程,要求模型从一个单词中去除多余的符号。模型的表现随着自然语言任务描述的添加和模型上下文中示例的数量 K 的增加而提高。few-shot 学习也随着模型规模的增大而显著提高。虽然在这种情况下的结果特别惊人,但这些学习曲线的一般趋势在大多数任务中都成立。这些“学习”曲线不涉及梯度更新或微调,只涉及作为条件的示例数量的增加。
总体而言,GPT-3 在自然语言处理任务中取得了很好的成果,其中在 zero-shot 和 one-shot 设置下表现优异,在 few-shot 设置下有时甚至可以超过最先进技术(尽管最先进技术由微调模型实现)。例如,GPT-3 在 CoQA 的zero-shot 设置下达到了81.5 F1,在 one-shot 设置下达到了84.0 F1,在 few-shot 设置下达到了85.0 F1。类似地,GPT-3 在 TriviaQA 的 zero-shot 设置下达到了64.3%的准确率,在 one-shot 设置下达到了68.0%,在 few-shot 设置下达到了71.2%。
GPT-3还在设计用于测试快速适应或即兴推理的任务中表现出了不错的能力,其中包括打乱单词、进行算术运算以及在仅看到一次定义后在句子中使用新词。在 few-shot 设置中,GPT-3 可以生成新闻文章,人类很难区分它们与人类生成的文章。
同时,在某些任务上,即使在 GPT-3 这个规模上,few-shot 的表现也存在困难。这包括像 ANLI 数据集这样的自然语言推断任务,以及一些阅读理解数据集,如 RACE 或 QuAC。
通过对“数据污染”进行分析,当在像 Common Crawl 这样的数据集上训练高容量模型时,这成为了一个越来越严重的问题,因为这些数据集可能会包含来自测试数据集的内容,因为这些内容通常存在于网络上。通过测量数据污染并量化其扭曲效应,可以发现数据污染对大多数数据集的 GPT-3 性能影响很小,但也确定了一些数据集可能会扩大影响。
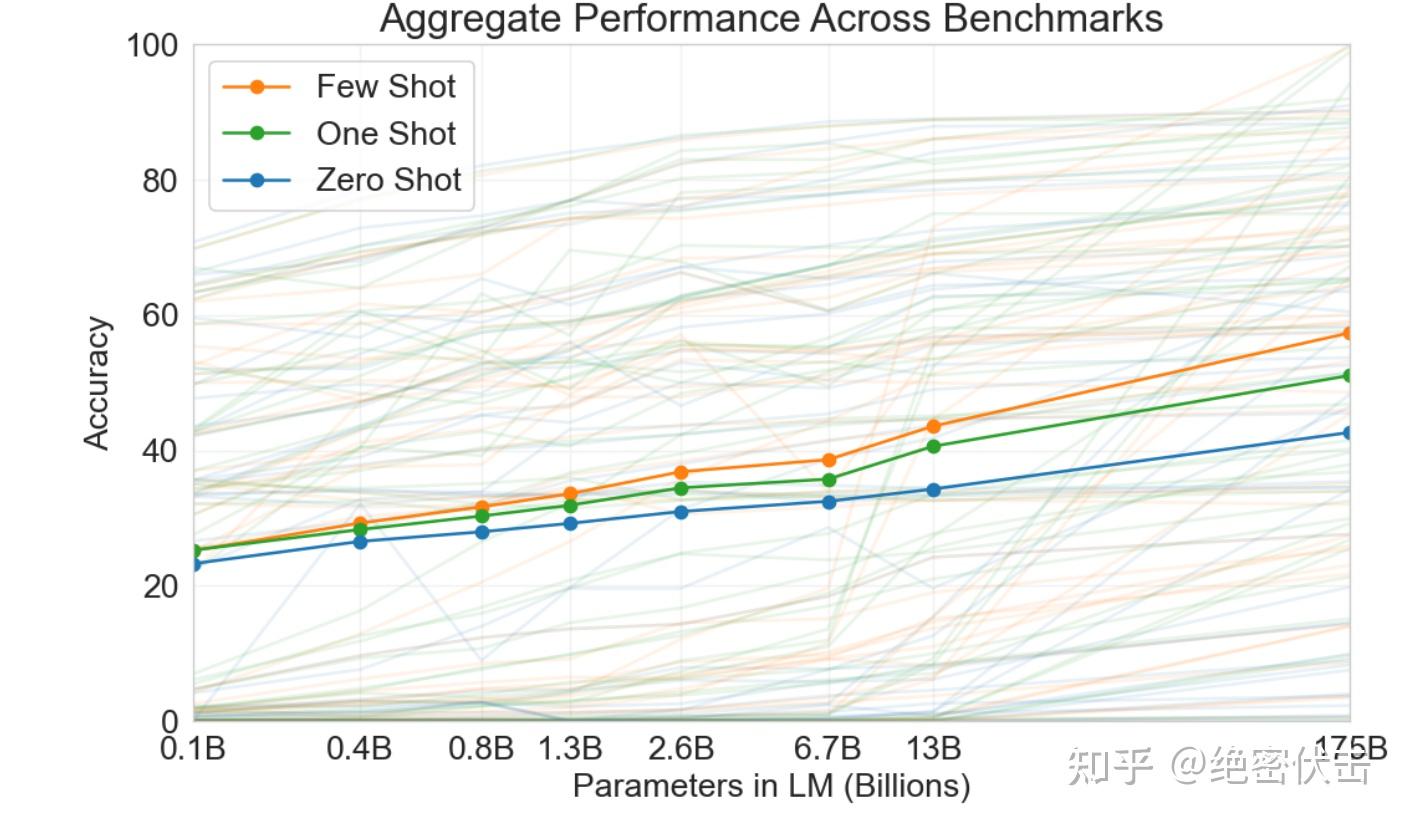
此外,OpenAI 还训练了一系列规模较小的模型(参数从1.25亿到130亿),以便比较它们在 zero-shot、one-shot、few-shot 样本中和 GPT-3 差异。总的来说,在大多数任务中,所有三种设置的模型容量都有相对平滑的扩展;一个值得注意的模式是,zero-shot、one-shot、few-shot 性能之间的差距通常随着模型容量的增加而增加,这可能表明更大的模型更善于元学习。
本篇文章的其余部分组织如下:
- 在第2节中,介绍训练 GPT-3 和评估其性能的方法
- 第3节中介绍在 zero-shot、one-shot、few-shot 样本设置下完成各种任务的结果
- 第4节介绍数据污染(训练-测试重叠)的问题
- 第5节介绍 GPT-3 的限制
- 第6节介绍更广泛的影响
- 第7节回顾 GPT-3 的相关工作
- 第8节总结 GPT-3 内容
2. 训练GPT-3方法

OpenAI 使用的预训练方法,包括模型、数据和训练。具体而言,在四个方面进行评测(见图2.1):
- 微调(Fine-Tuning,FT)是近年来最常见的方法,它通过在特定任务的监督数据集上训练来更新预训练模型的权重。通常使用数千到数十万个标记样本。微调的主要优点是在许多基准测试中表现出强大的性能。其主要缺点是需要为每个任务提供一个新的大型数据集,可能在分布范围外出现泛化能力差的情况。GPT-3 没有选择微调,但从原则上讲,GPT-3 是可以被微调的。
- Few-Shot(FS)是指模型在推理时给予少量样本,但不允许进行权重更新。如图2.1所示,对于一个典型数据集,Few-shot 有上下文和样例(例如英语句子和它的法语翻译)。Few-shot 的工作方式是提供K个样本,然后期望模型生成对应的结果。通常将K设置在10到100的范围内,因为这是可以适应模型上下文窗口的示例数量(nctx = 2048)。Few-shot 的主要优点是大幅度降低了对特定任务数据的需求,并减少了从微调数据集中学习过度狭窄分布。主要缺点是该方法的结果迄今为止远不如最先进的微调模型。此外,仍需要一小部分特定任务的数据。
- One-Shot(1S)与 Few-Shot 类似,只允许一个样本(除了任务的自然语言描述外),如图2.1所示。将 One-Shot 与 Few-Shot、Zero-Shot 区分开的原因是它最接近某些任务与人类沟通的方式。相比之下,如果没有示例,有时很难传达任务的内容或格式。
- Zero-Shot(0S)和one-shot类似,但不允许提供样本,只给出描述任务的自然语言指令。该方法提供了最大的方便性、稳健性以及避免虚假相关的可能性,但也是最具挑战性的设置。在某些情况下,即使是人类,在没有例子的情况下,也可能难以理解任务的格式。例如,如果要求某人“制作一张关于200米冲刺世界纪录的表格”,这个请求可能是模棱两可的,因为可能不清楚表格应该具有什么格式或包含什么内容。然而,至少在某些情况下,zero-shot 是最接近人类执行任务的方法,例如图2.1中的翻译示例,人类可能仅凭文本指令就知道该做什么。
图2.1展示了使用将 “英语翻译成法语” 的例子来说明上面的四种方法。OpenAI 特别强调了 few-shot 的结果,因为它们中的许多仅略逊于最先进的微调模型。然而,one-shot,甚至有时是 zero-shot,似乎才是与人类表现最公平的比较。
2.1 模型架构
GPT-3 使用与 GPT-2 相同的模型和架构,包括模型初始化、归一化和输入编码,但是在 Transformer 中使用交替的密集和局部稀疏注意力模式,类似于 Sparse Transformer。为了研究 ML 性能对模型大小的依赖,OpenAI 训练了8种不同大小的模型,范围从1.25亿个参数到1750亿个参数,最后一个1750参数的模型称为 GPT-3 模型。之前的研究表明,有足够的训练数据,验证集 loss 可以近似表示为幂律分布;训练许多不同大小的模型可以用来测试此假设,包括验证集损失和下游语言任务。
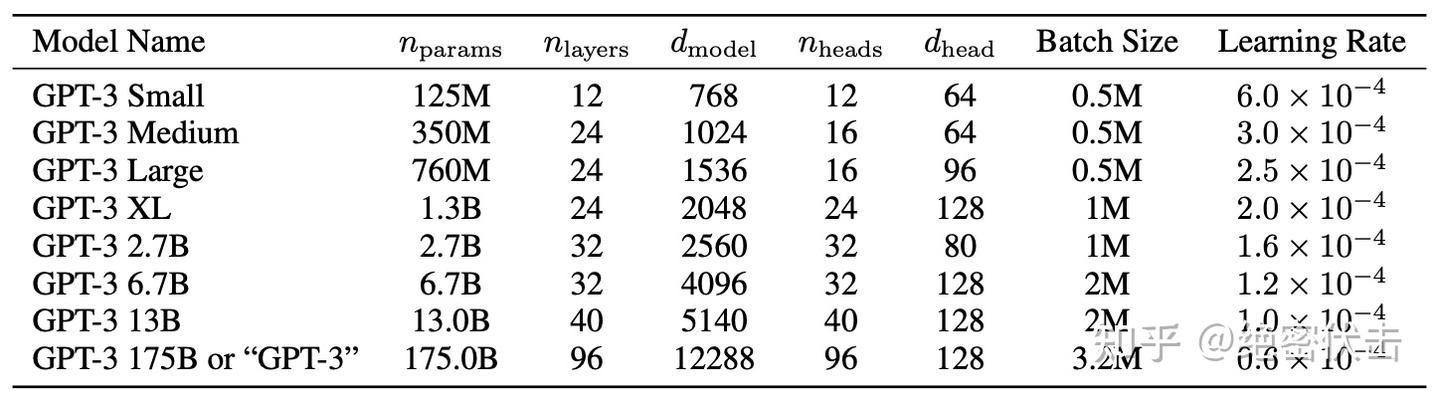
表2.1展示了8个模型的大小和架构。这里,nparams 是可训练参数的总数,nlayers 是总层数,dmodel 是 block 输出维度大小(一般feedforward设置为dmodel的四倍大小,dff = 4 * dmodel),而 dhead 是每个注意头的维度。所有模型都使用 nctx = 2048 个 token。
2.2 训练数据
随着语言模型数据集的迅速扩大,最终形成了 Common Crawl 数据集,包含近万亿个单词。这样的数据集大小足以训练 GPT-3 这样的模型。然而,未经过滤的 Common Crawl 版本往往比经过精心筛选的数据集质量低。OpenAI 使用了三个步骤过滤数据集:
- 下载并根据与一系列高质量参考语料库的相似性对 Common Crawl 版本进行过滤
- 对文档进行模糊去重,包括数据集内部和跨数据集,以防止冗余数据
- 添加已知的高质量参考语料库到训练混合中,以增强 Common Crawl 的多样性
第一和第二点(对 Common Crawl 的处理)的细节在后面描述。对于第三点,添加几个经过筛选的高质量数据集,包括一个扩展版本的 WebText 数据集,该数据集是通过在较长时间内收集链接进行抓取而获得的,两个基于互联网的书籍语料库(Books1 和 Books2)以及英语维基百科。
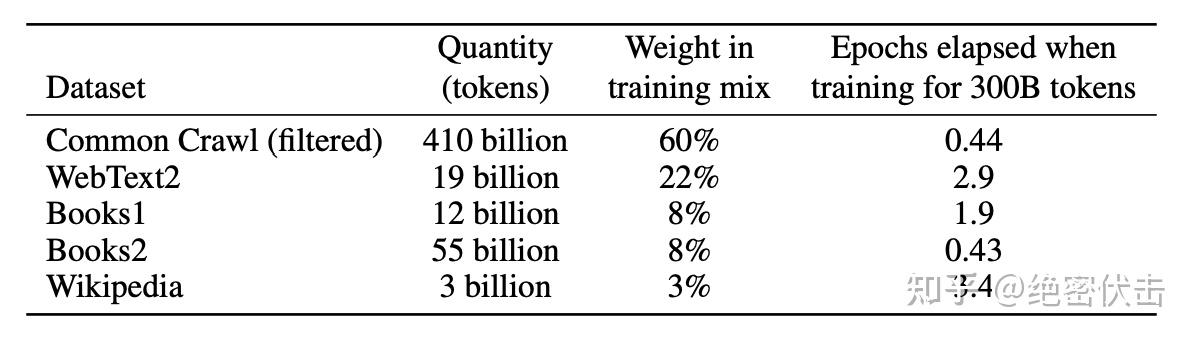
表2.2显示了在训练中使用的最终混合数据集。CommonCrawl 是从2016年到2019年的数据,压缩后的纯文本数据大小为45TB,过滤后为570GB。在训练过程中,CommonCrawl 和 Books2 数据集只会使用一次(1个 epoch),而其他数据集则被采样2-3次(多个epoch)。
对于在互联网数据上预训练的语言模型,尤其是具有大量内容记忆能力的大型模型,一个主要的方法论问题是,它们在预训练期间无意中会看到下游任务的数据,从而导致可能出现数据污染。为了减少这种污染,尝试删除训练集和测试集重叠的部分。但是由于过滤器的漏洞会导致忽略一些重叠部分,由于训练成本高昂,重新训练模型是不可行的。
2.3 训练过程
一般大模型可以使用更大的 batch size,但需要更小的学习率,表2.1显示了参数设置。有关训练过程和超参数设置的详细信息,如下所示:
- 使用 Adam 优化器,
- 将梯度归一化到1.0
- 使用 cosin 衰减,将学习率衰减为原来的10%,在训练完2600亿个 token 后,将学习率设置为原来的10%,然后继续训练。前375亿 token 使用线性的 LR warmup
- 动态调整 batch size,在前40~120亿 token 之前逐渐增加 batch size
- 在训练期间对数据进行无重复采样,以最小化过拟合
- 对模型权重使用0.1的正则化
2.4 模型评估
对于 few-shot 学习,通过从该任务的训练集中随机抽取 K 个示例作为条件,以此评估验证集中的每个示例,根据任务用 1 或 2 个换行符分隔。 对于 LAMBADA 和 Storycloze,由于没有可用的监督训练集,因此从开发集中抽取条件示例并在测试集上进行评估。 对于 Winograd(原始版本,而非 SuperGLUE 版本)只有一个数据集,因此直接从中提取条件示例。
K 可以是从 0 到模型上下文窗口的任何值,对于 nctx = 2048,通常取 10 到 100。 较大的 K 值不一定更好,因此当单独的开发和测试集可用时,在开发集上试验几个 K 值,然后在测试集上运行最佳值。
对于涉及从多个选项中选择一个正确选项的任务(多项选择题),提供K个上下文加正确完成的示例,然后提供一个仅包含上下文的示例,并比较每个完成的LM似然。 对于大多数任务,比较每个 token 的似然(以便对长度进行归一化),但在少量数据集(ARC,OpenBookQA和RACE)上,通过计算 对每个完成的无条件概率进行归一化,在开发集上衡量,可以获得额外的益处,其中是字符串“Answer:”或“A:”,用于提示完成应该是一个答案,但是除此之外是通用的。
对于二分类任务,给选项命名更具语义意义的名称(例如,“True”或“False”而不是0或1),然后将任务视为多项选择题。
对于自由形式完成的任务,使用 beam 搜索:beam 宽度为4,长度惩罚为 。根据数据集的标准,使用F1相似度分数、BLEU 或完全匹配来评分模型。
当测试集公开时,将针对每种模型大小和学习设置(zero-one-and few-shot)在测试集上生成最终结果。当测试集是私有时,模型通常太大而无法适应测试服务器,因此会在开发集上生成结果。在少量数据集(SuperGLUE、TriviaQA、PiQa)上提交到测试服务器,并且只提交200B的 few-shot 结果,对于其他所有结果都会在开发集上进行测试。
3. 结论
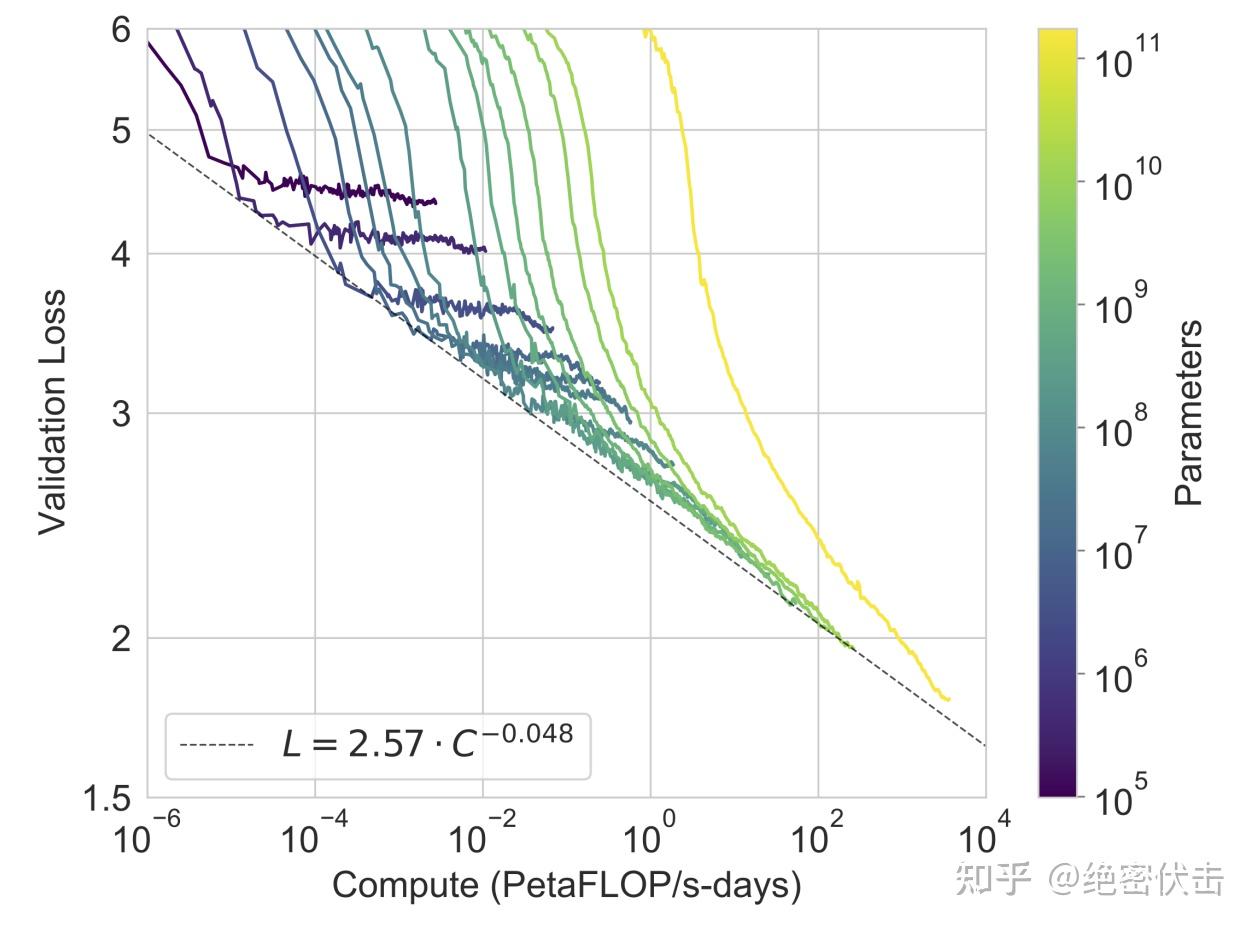
在图3.1中,展示了第2节中描述的8个模型的训练曲线。对于这个图表,还包括了6个额外的超小型模型,其中最少只有100,000个参数。当有效利用训练计算资源时,语言模型的性能遵循幂律。在将这种趋势扩展了两个数量级之后,观察到只有轻微偏离幂律的情况。有人可能会担心,这些交叉熵损失的改进仅来自于对训练语料库的琐碎细节进行建模。然而,在接下来的章节中,将会看到交叉熵损失的改进导致在广泛的自然语言任务中实现了一致的性能提升。
- 在第3.1节中,将会评估传统的语言建模任务和语言建模类似的任务,例如 Cloze 任务和句子/段落完成任务。
- 在第3.2节中,将评估“闭卷”问答任务:需要使用模型参数中存储的信息来回答通用知识问题的任务。
- 在第3.3节中,将会评估模型在翻译语言(特别是 one-shot 和 few-shot)方面的能力。
- 在第3.4节中,将评估模型在类 Winograd Schema 任务上的表现。
- 在第3.5节中,将评估涉及常识推理或问答的数据集。
- 在第3.6节中,将评估阅读理解任务。
- 在第3.7节中,将评估 SuperGLUE 基准套件。
- 在3.8中,将简要探讨NLI。
- 在第3.9节中,设计了一些特别用于探究上下文学习能力的附加任务,这些任务侧重于即时推理,适应技能或开放式文本合成。将会在 few-shot,one-shot 以及 zero-shot 设置中评估所有任务。
3.1 语言建模,Cloze任务和填空任务
本节中,将测试 GPT-3 在传统的语言建模任务上的表现,以及涉及到预测单词、完成一个句子或段落、或在多个文本选项中进行选择的相关任务。
3.1.1 语言模型
在 Penn Tree Bank(PTB)数据集上计算 zero-shot perplexity。评估时省略了 4 个与维基百科相关的任务,因为它们完全包含在训练数据中,同时还省略了十亿词基准测试,因为该数据集的大部分数据都包含在训练集中。PTB由于早于现代互联网而避免了这些问题。测试结果显示最大模型在 PTB 上以相当大的优势创造了新的 SOTA 记录,将 perplexity 降至20.50。请注意,由于 PTB 是一个传统的语言建模数据集,它没有明确的示例分离来定义 one-shot 或 zero-shot 样本评估,因此只测量 zero-shot。
备注:Perplexity 是用于评估语言模型性能的指标。它是对给定测试集中每个单词预测概率的连乘积求取几何平均数的倒数。因此,perplexity 的值越小,表示模型在预测下一个单词时的不确定性越小,其性能越好。通常情况下,较好的语言模型在测试集上的 perplexity 值会接近于单词的个数,例如,一个预测英文句子的语言模型,在测试集上的 perplexity 值大概率在20-200之间。
3.1.2 LAMBDA数据
LAMBADA 数据集是一个用于语言模型评估的基准数据集,由德国莱比锡大学的研究人员开发。LAMBADA 的名称代表“语言模型百战不殆”的缩写。该数据集包含了超过10万个英文句子,每个句子都是从小说中选取的,并以一种独特的方式构建。在每个句子的末尾,会留下一个单词,并要求模型预测这个单词是什么。这个单词是整个句子的关键词,只有对上下文有完全理解的模型才能正确地预测出这个单词。LAMBADA 数据集旨在评估语言模型的上下文感知能力,即模型能否理解上下文并根据上下文来进行推理和预测。这使得 LAMBADA 数据集成为评估语言模型真正能力的一个强有力的工具。
最近有人提出,持续扩大语言模型的规模正在导致在这个难度极高的基准测试上收益递减。最近两个最先进结果之间加倍模型大小仅实现了1.5%的小改进,因此认为“继续按数量级扩展硬件和数据大小不是前进的道路”。然而,OpenAI 发现这条道路仍然有前途。在 zero-shot 设置下,GPT-3 在 LAMBADA 数据集上取得了76%的准确率,比之前最先进技术高出8%。
LAMBADA 还展示了 few-shot 学习的灵活性,因为它提供了一种解决这个数据集经典问题的方法。尽管LAMBADA 中的填空总是在句子的最后一个单词,但标准语言模型无法知道这个细节。因此,它不仅为正确的结尾分配概率,还为段落的其他有效延续分配概率。过去已经部分解决了这个问题,使用停用词过滤器(禁止“延续”单词)。相比之下,few-shot 设置允许我们将任务“框架化”为填空测试,并允许语言模型从例子中推断出只需要完成一个单词。使用以下填空格式:
Alice was friends with Bob. Alice went to visit her friend ___ .→ Bob
George bought some baseball equipmenta balla gloveand a __. →
当以这种方式格式化的示例呈现给 GPT-3 时,在 few-shot 设置下,它的准确率达到86.4%,比先前的最新技术水平提高了超过18%。模型尺寸越大,few-shot 性能的提高就越明显。虽然这种设置将最小模型的性能降低了近20%,但对于 GPT-3,它提高了10%的准确率。最后,填空方法在一次性训练中不是有效的,它总是比 zero-shot 设置表现更差。这可能是因为所有模型仍然需要多个示例才能识别模式。
3.1.3 HellaSwag数据集
HellaSwag 数据集是由斯坦福大学的研究人员开发的,用于评估通用语言理解的基准数据集。它的名称“HellaSwag”代表“当上下文知识远超常识时,会发生什么”的俚语表达。
该数据集包含10万个问题-回答对,其中每个回答都是一个需要对上下文进行深入理解的反常或不寻常的答案。这使得 HellaSwag 成为评估模型的上下文感知能力和常识推理能力的强有力工具。
与其他数据集不同,HellaSwag 的问题和答案都是由众包工人创造的,而不是来自现有的文本数据。这种方法的优点在于它能够创造出具有挑战性的数据,但缺点在于可能会出现人工偏差。
HellaSwag 数据集的独特之处在于它需要模型根据上下文进行复杂的推理,而不仅仅是简单地匹配单词或短语。因此,它能够提供对模型的更全面的评估,使得 HellaSwag 成为测试通用语言理解能力的重要数据集之一。
在该数据集上,在一次性训练中,GPT-3 的准确率为78.1%,在 few-shot 训练中为79.3%,优于经过微调的1.5B参数语言模型的75.4%准确率,但仍比经过微调的多任务模型 ALUM 的85.6%总体 SOTA 低得多。
3.1.4 StoryCloze数据集
StoryCloze 数据集是用于测试模型对于连续事件的理解和推断能力的基准数据集。它由卡内基梅隆大学的研究人员开发,包含50,000个四句话的故事,每个故事有一个上下文和两个结局。目标是判断哪个结局是最符合上下文的。
与其他基准数据集不同,StoryCloze 数据集专注于评估模型对于连续事件的推断能力,而不是独立的语言理解任务。因此,它需要模型能够理解上下文,并从中推断出适当的结局。这使得 StoryCloze 成为评估模型对于故事理解的重要工具。
StoryCloze 数据集的独特之处在于它要求模型对于上下文的深入理解,并且需要进行复杂的推理。与传统的文本分类数据集不同,它需要模型能够理解情节,感知情感和推断事件之间的关系。这使得 StoryCloze 成为评估模型通用语言理解能力的重要数据集之一。
对 GPT-3 在 StoryCloze 2016 数据集上进行评估。在这里,GPT-3在 zero-shot 设置下实现了83.2%的准确率,在 few-shot 设置下(K = 70)实现了87.7%的准确率。这仍然比使用基于 BERT 的模型进行微调的 SOTA 低4.1%,但相对于以前的 zero-shot 结果有了大约10%的提高。
3.2 Closed Book问答
Closed Book 问答是指在没有外部参考材料的情况下回答问题的任务。在这个任务中,模型必须依靠其内部存储的先前知识和推理能力来回答问题。与Open Book 问答不同,Closed Book 问答不允许模型查询外部信息源,如互联网或参考文献。
这个任务对于评估语言模型的表现非常重要,因为它测试了模型对于推理、常识和上下文的理解能力。该任务也是一个具有挑战性的任务,因为模型必须在没有外部信息的情况下,独立地回答各种类型的问题,例如事实型问题、计算型问题和推理型问题等。
尽管这个任务具有挑战性,但它在实际应用中具有广泛的用途。例如,在智能客服系统中,用户的问题可能是多种多样的,而且并不总是涉及到特定领域的知识,因此,使用 Closed Book 问答可以确保系统能够在各种情况下都能给出准确的答案。
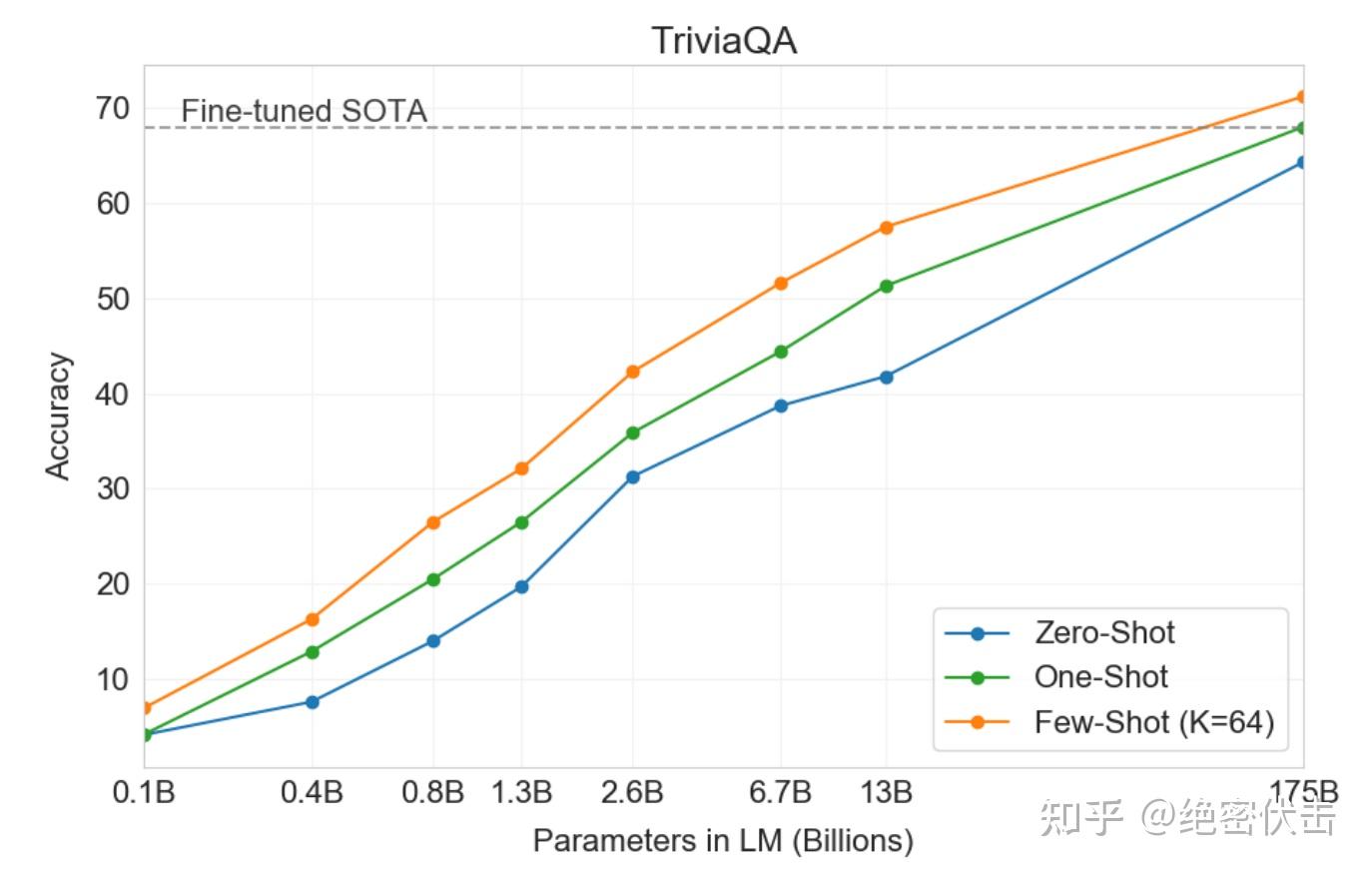
本节中,将评估 GPT-3 回答有关广泛事实知识的问题的能力。由于可能的查询量巨大,因此通常使用信息检索系统结合一个模型来学习如何给出问题和检索到的文本来生成答案。由于此设置允许系统搜索并依赖可能包含答案的文本,因此被称为“open-book”。最近证明了一个大型语言模型可以直接回答问题而不依赖辅助信息。他们将这种更严格的评估设置称为“closed-book”。他们的工作表明,即使容量更大的模型也可以表现得更好,使用 GPT-3 测试了这个假设。使用三个数据集(自然问题、网络问题、和 TriviaQA)评估 GPT-3。除了所有结果都在 closed-book 的设置中,使用的 few-shot、one-shot 和 zero-shot 评估表示比以前的 closed-book QA工作更加严格:除了不允许使用外部内容外,还不允许在问答数据集本身上进行微调。
GPT-3 在 TriviaQA 数据集上的结果如表3.3所示。在 zero-shot 情况下,GPT-3 取得了64.3%的准确率,在 one-shot 情况下为68.0%,在 few-shot 情况下为71.2%。zero-shot 结果已经比经过微调的 T5-11B 模型高出14.2%,也比在预训练期间使用了 Q&A 定制跨度预测的模型高出3.8%。在 one-shot 情况下,结果提高了3.7%,并匹配了一个开放领域 QA 系统的 SOTA,该系统不仅进行了微调,还利用了对2100万个文档的153亿参数的稠密向量索引进行了学习检索机制。GPT-3 的少量样本结果进一步将性能提高了3.2%。
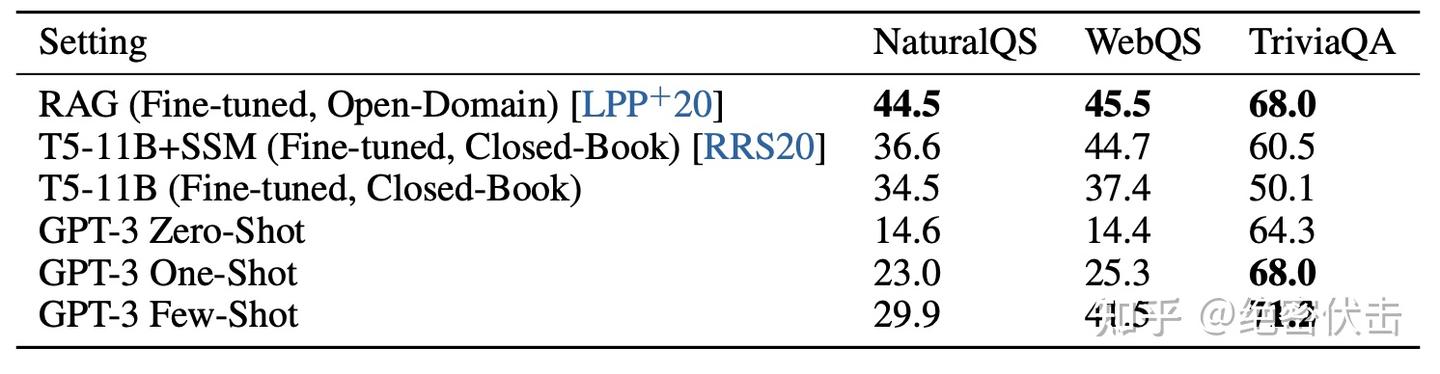
在 WebQuestions(WebQs)数据集上,GPT-3 在zero-shot、one-shot 和 few-shot 设置下分别达到14.4%、25.3%和41.5%的准确率。与经过微调的 T5-11B(37.4%)和 T5-11B+SSM(44.7%)相比较。其中,T5-11B+SSM 使用了一种特定的问答预训练过程。在 few-shot 设置下,GPT-3 接近最先进的经过微调模型的性能。值得注意的是,与 TriviaQA 相比,WebQS 从 zero-shot 到 few-shot 的提升更大,这可能表明 WebQs 的问题和/或答案风格对于 GPT-3 而言是一种分布外的情况。尽管如此,GPT-3 似乎能够适应这种分布,恢复出强大的 few-shot 设置性能。
在自然问答(NQs)中,GPT-3 在 zero-shot、one-shot 和 few-shot 设置下分别达到14.6%、23.0%和29.9%,而 fine-tuned T5 11B+SSM 的成绩为36.6%。与 WebQS 类似,从 zero-shot 到 few-shot 的巨大增益可能表明存在分布偏移,并且可能也可以解释相对于 TriviaQA 和 WebQS 的表现较差。特别是,NQs 中的问题倾向于对维基百科上的非常细粒度的知识进行测试,这可能在测试 GPT-3 的容量和预训练分布的极限。
总体而言,GPT-3 在三个数据集中的一个数据集的 one-shot 表现与open book 上 fine-tuning 的最佳结果相匹配。在另外两个数据集上,尽管没有使用 fine-tuning,但它也接近于 closed-book SOTA 的表现。在这三个数据集上,性能随着模型规模的增加而平稳增长(图3.3),这可能反映了模型容量直接转化为模型参数中吸收的更多“知识”的想法。
3.3 翻译
由于容量限制,GPT-2 使用了多语言文档的过滤器来生成仅包含英语的数据集。尽管只训练了10兆字节的法语文本,但 GPT-2 表现出了一定的多语言能力,并在法语和英语之间进行翻译时表现非常好。由于 GPT-3 的容量从GPT-2 增加了两个数量级,因此扩大了训练数据集的范围,以包括更多其他语言的代表性内容,尽管这仍然是需要进一步改进的领域。正如2.2节中所讨论的,大部分数据是从原始的 Common Crawl 中获取的,仅进行了基于质量的过滤。尽管 GPT-3 的训练数据仍然主要是英语(按词数占93%),但它还包括其他语言
现有的无监督机器翻译方法通常结合对成对单语数据集的预训练和回译,以一种可控的方式桥接两种语言。相比之下,GPT-3 从混合许多语言的训练数据中自然地学习,从单词、句子和文档层面进行组合。GPT-3 还使用单一的训练目标,该目标不是为任何特定任务定制或设计的。然而,one/few-shot 设置与先前的无监督工作并不严格可比,因为它们利用了少量的成对示例(1或64)。
结果显示在表3.4中。zero-shot GPT-3 仅接收任务的自然语言描述,仍然表现不如最近的无监督 NMT 结果。然而,每个翻译任务仅提供一个示例演示可以提高7个BLEU以上的性能。在完整的 few-shot 设置中,GPT-3 进一步提高了4个BLEU,导致与先前的无监督 NMT 工作的类似性能。GPT-3 在性能方面有明显的偏差,取决于语言方向。对于所研究的三种输入语言,GPT-3 在将文本翻译成英语时显著优于先前的无监督 NMT 工作,但在另一个方向上表现不佳。在 En-Ro 上的表现是一个显著的异常值,比先前的无监督 NMT 工作差10个BLEU以上。这可能是由于 GPT-2 的字节级BPE分词器被重复使用,而该分词器是针对几乎完全是英语的训练数据集开发的。对于 Fr-En 和 De-En,few-shot 的 GPT-3 优于我们能找到的最佳监督结果。对于 Ro-En,few-shot 的 GPT-3 的表现与总体 SOTA 相差不到0.5 BLEU,而总体 SOTA 是通过无监督预训练、在608K个标记示例上进行监督微调实现的。
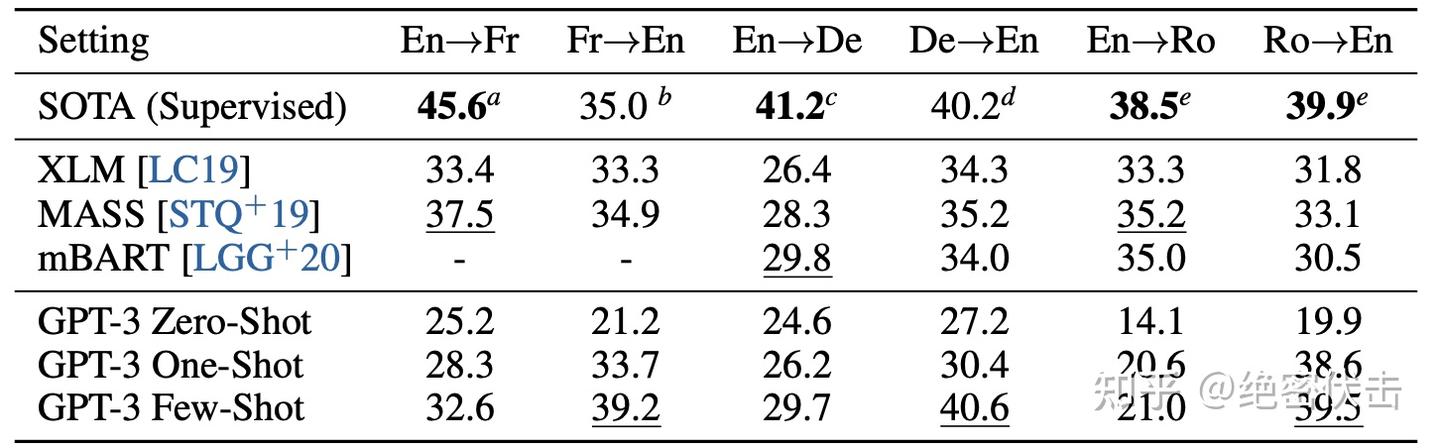
最后,在所有语言对和所有三种设置(zero、one、few-shot)中,模型容量都呈现出平滑的改善趋势。
3.4 Winograd-Style任务
Winograd-Style 任务是一类自然语言理解任务,旨在测试机器在理解自然语言文本中所隐含的逻辑关系和推理过程方面的能力。这些任务要求机器根据上下文和推理逻辑来解决文本中的指代消解或逻辑关系的问题。
Winograd-Style 任务通常采用句子级别的逻辑推理问题,这些问题要求理解者推理文本中的指代消解或逻辑关系,以回答问题。这些任务的一个重要特点是需要对文本进行深入的理解,因为推理过程通常涉及文本中多个句子之间的关系和逻辑推断。
Winograd-Style 任务的名字来自于一个经典的例子,Winograd Schema Challenge,这个例子用来测试机器理解自然语言中的逻辑关系和推理。一个经典的 Winograd Schema 问题是:
"The city council refused the demonstrators a permit because they feared violence. Who feared violence?"
这个问题中,“they” 是一个代词,它的指代关系不清晰。读者需要仔细分析整个句子的上下文和语境,以确定“they” 是指城市委员会还是抗议者。
Winograd-Style 任务是评估自然语言处理技术的重要基准测试之一,因为它能够有效地评估计算机在真实世界中处理自然语言时的推理和推断能力。
最近,经过 Fine-tune 的语言模型已经在原始的 Winograd 数据集上实现了接近于人类的性能,但是更难的版本仍然明显落后于人类表现。以zero、one、few-shot的方式测试 GPT-3 在 Winograd 和 Winogrande 上的表现。
在 Winograd上,GPT-3 在 zero、one和 few-shot 情况下的表现分别为88.3%、89.7%和88.6%,显示出无明显的差别,但在所有情况下都取得了强大的结果,只比最先进的结果略差几个百分点,并且估计接近人类表现。
在更困难的 Winogrande 数据集上,在上下文中学习可以带来一些收益:在 zero-shot 训练模式下,GPT-3 的得分为70.2%,在 one-shot 训练模式下为73.2%,在 few-shot 训练模式下为77.7%。相比之下,一种经过微调的RoBERTA 模型的得分为79%,最先进的方法是使用一个高容量的 T5 模型进行微调,其得分为84.6%,而该任务的人类表现为94.0%。
3.5 Common Sense Reasoning
Common Sense Reasoning 是指机器具备基于常识推理的能力,即通过对世界常识的理解和应用来进行推理和决策,类似于人类的思考方式。常识推理在自然语言处理、人工智能等领域中都有广泛的应用,例如问答系统、智能对话、机器翻译、文本分类等。然而,由于常识的广泛性和复杂性,常识推理一直是人工智能研究的难点和热点问题之一。
接下来考虑三个旨在捕捉物理或科学推理的数据集,与句子完成、阅读理解或广泛知识问答不同。第一个数据集是PhysicalQA (PIQA) ,它提出了关于物理世界如何工作的常识问题,旨在探究对世界的基本理解。GPT-3 在 zero、one 和 few-shot 上的准确率分别为81.0%、80.5%和82.8%(最后一个在 PIQA 的测试服务器上测量)。P结果仍然比人类表现差10%以上,但是 GPT-3 的 few-shot 甚至是 zero-shot 结果均优于当前的最优结果。
ARC 是一个数据集,其中包含从三年级到九年级科学考试中收集的多项选择题。在“挑战”版的数据集中,这些问题经过过滤,使用简单的统计或信息检索方法无法正确回答。在 zero-shot 情况下,GPT-3 在该数据集上的准确率为51.4%,在 one-shot 情况下为53.2%,在 few-shot 情况下为51.5%。这接近于 UnifiedQA 中精调的 RoBERTa 基准(55.9%)的表现。在“简单”版的数据集中,GPT-3 分别达到了68.8%、71.2%和70.1%的准确率,略高于精调的 RoBERTa 基准。然而,这两个结果仍然远远不及 UnifiedQA 取得的整体最优结果,在挑战集上比GPT-3 的 few-shot 结果高27%,在简单集上高22%。
在 OpenBookQA 数据集上,GPT-3 在 zero-shot 到 few-shot 情况下的表现有了显著的提高,但仍然比整体最优结果低20多分。GPT-3 在 few-shot 情况下的表现与排行榜上精调的 BERT Large 基准相似。
总体而言,在上下文中使用 GPT-3 进行常识推理任务的学习表现是复杂的,仅在 PIQA 和 ARC 的one-shot和few-shot学习设置中观察到了一些小的增益,但在 OpenBookQA 上观察到了显著的改进。在所有评估设置中,GPT-3在新的 PIQA 数据集上取得了SOTA。
3.6 阅读理解
接下来评估 GPT-3 在阅读理解任务中的表现。使用了一组包括抽象、多项选择和基于跨度的回答格式的数据集,这些数据集涵盖了对话和单个问题的设置。观察到 GPT-3 在这些数据集上的表现差异很大,这表明它在不同的回答格式上具有不同的能力。总体而言,观察到 GPT-3 与每个数据集上的初始基线和使用上下文表示训练的早期结果表现相当。
在 CoQA 这个自由形式的对话数据集中,GPT-3 的表现最好(与人类基准相差不到3分),而在 QuAC 这个需要对教师-学生互动的结构化对话行为和回答进行建模的数据集中,表现最差(比 ELMo 基准低13个F1分)。在DROP 这个测试离散推理和阅读理解的数据集中,GPT-3 在 few-shot 情况下的表现超过了原始论文中精调 BERT基准,但仍远远低于人类表现。在 SQuAD 2.0 上,GPT-3 展示了其 few-shot 学习能力,相比 zero-shot 情况,F1分数提高了近10分(达到69.8)。在 RACE 这个包含中学和高中英语考试多项选择题的数据集中,GPT-3 的表现相对较弱。
3.7 SuperGLUE
SuperGLUE 是自然语言理解任务评测的一个基准数据集,由十个具有挑战性的任务组成,是 GLUE(General Language Understanding Evaluation)的扩展版本。这些任务包括自然语言推理、多项选择问答、句子关系判断、核心论元识别等。SuperGLUE 旨在提高自然语言理解模型的能力,同时为研究人员提供更具挑战性的任务,以推动自然语言处理的发展。
与 GLUE 不同,SuperGLUE 的任务更加复杂和多样化,难度更高,也更具挑战性。此外,SuperGLUE 还提供了更严格的评估方法,包括更多的性能指标和更严格的 zero-shot 评估。SuperGLUE 数据集中的任务和标准化评估方法已经被广泛应用于自然语言理解研究和开发中,并成为了评估最新自然语言理解技术的标准基准之一。
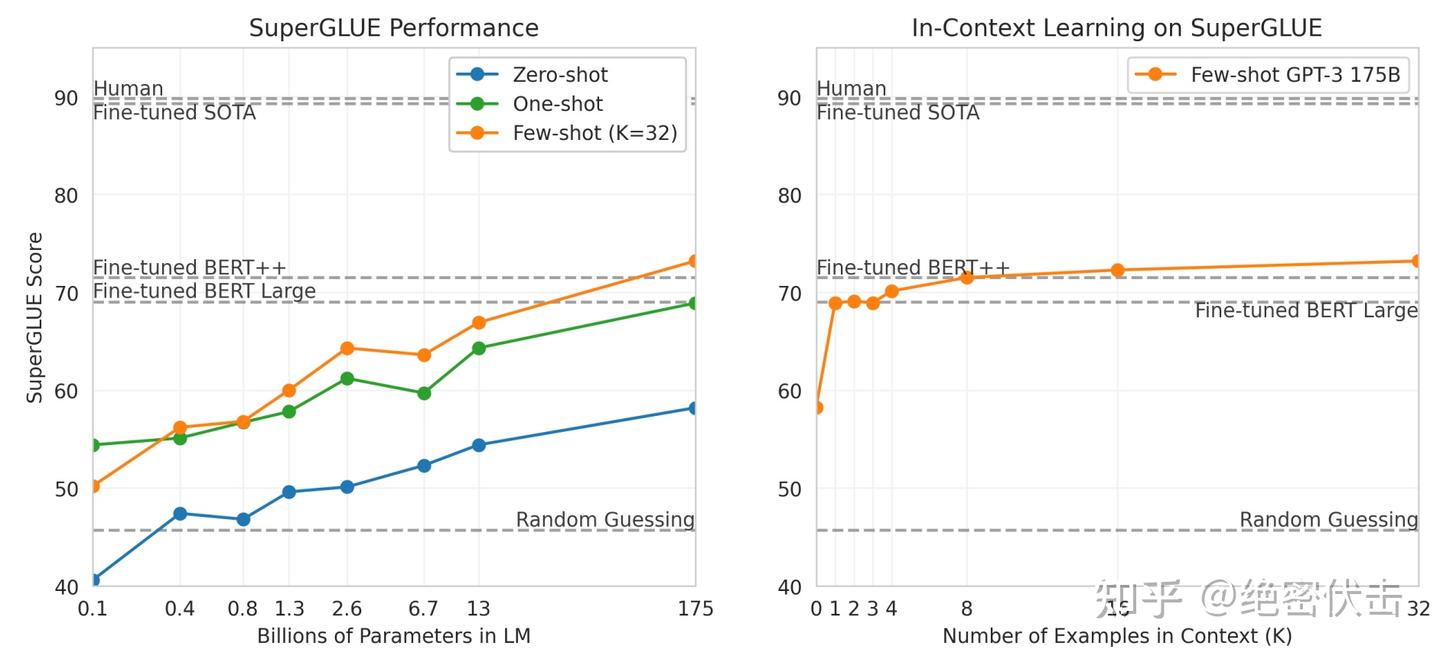
GPT-3 在 SuperGLUE 数据集的测试集上的表现如表3.8所示。在 few-shot 设置中,为所有任务使用了32个样例,随机从训练集中抽样。对于除 WSC 和 MultiRC 之外的所有任务,为每个问题抽取了一组新的样例作为上下文。对于 WSC 和 MultiRC,使用了同一组从训练集中随机抽取的样例作为评估问题的上下文。
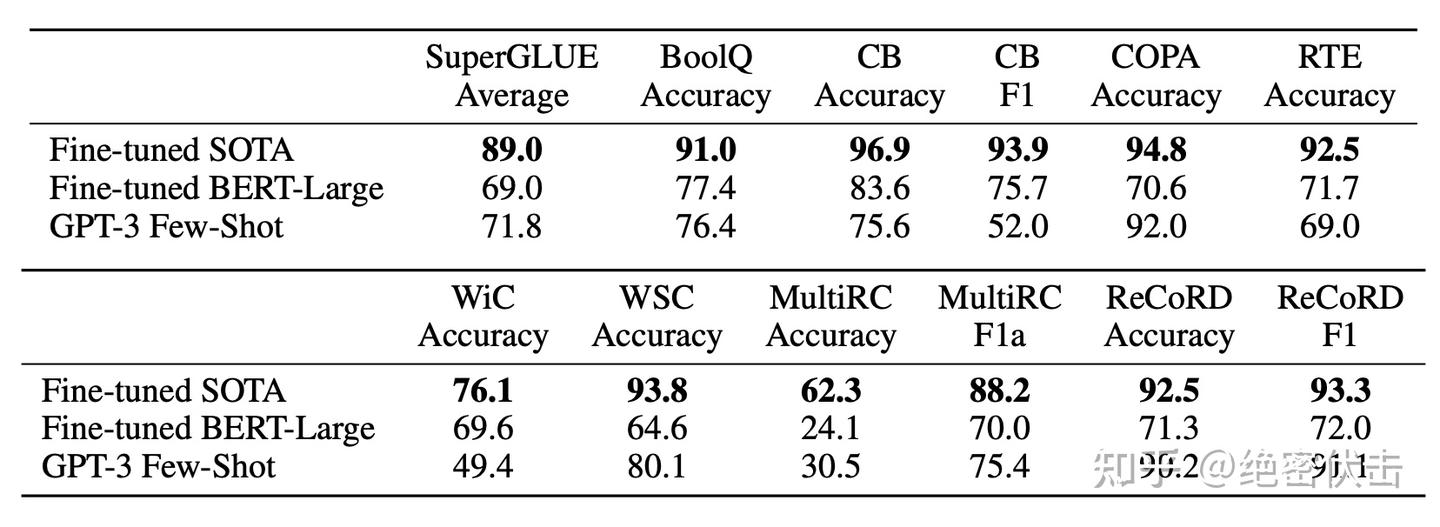
GPT-3 在不同任务上的表现差异很大。在 COPA 和 ReCoRD 任务中,GPT-3 在 one-shot 和 few-shot 设置下均取得了接近 SOTA 的表现,其中 COPA 的表现只落后了几个点,并在排行榜上获得第二名,第一名由一个经过微调的110亿参数模型(T5)获得。在 WSC 任务中,性能仍然相对强劲,在 few-shot 设置下达到了80.1%的准确率。在 BoolQ、MultiRC 和 RTE 任务中,性能合理,大致与经过微调的 BERT-Large 相当。在 CB 任务中,我们看到 few-shot 设置下的准确率为75.6%。
在 WiC 任务上,GPT-3 的表现相对较弱,few-shot 的表现仅有49.4%(与随机选择差不多)。尝试了许多不同的短语和句子表述方法(WiC 任务要求确定单词在两个句子中是否具有相同的含义),但是没有一种方法能够达到良好的表现。这暗示了一个现象,即在某些涉及比较两个句子或片段的任务中,GPT-3 在 few-shot 或 one-shot 环境下表现较弱,例如判断单词在两个句子中是否使用相同的方式,一个句子是否是另一个句子的释义或暗示等等。这也可以解释 RTE 和 CB 的相对较低分数,因为它们也遵循这种格式。尽管存在这些弱点,但 GPT-3 仍然在8项任务中优于经过 fine-tune 的 BERT-large 模型的4项,并且在两项任务中,GPT-3 接近由 fine-tune 的110亿参数模型。
最后,在上下文学习的情况下,随着模型大小和上下文中的示例数量增加,few-shot 的 SuperGLUE 得分稳步提高(图3.8)。将每个任务的K值扩展到32个示例。在扫描K值时,发现 GPT-3 在每个任务中不到8个示例就能超过fine-tuned BERT-Large的整体 SuperGLUE 得分。
3.8 NLI(自然语言推理)
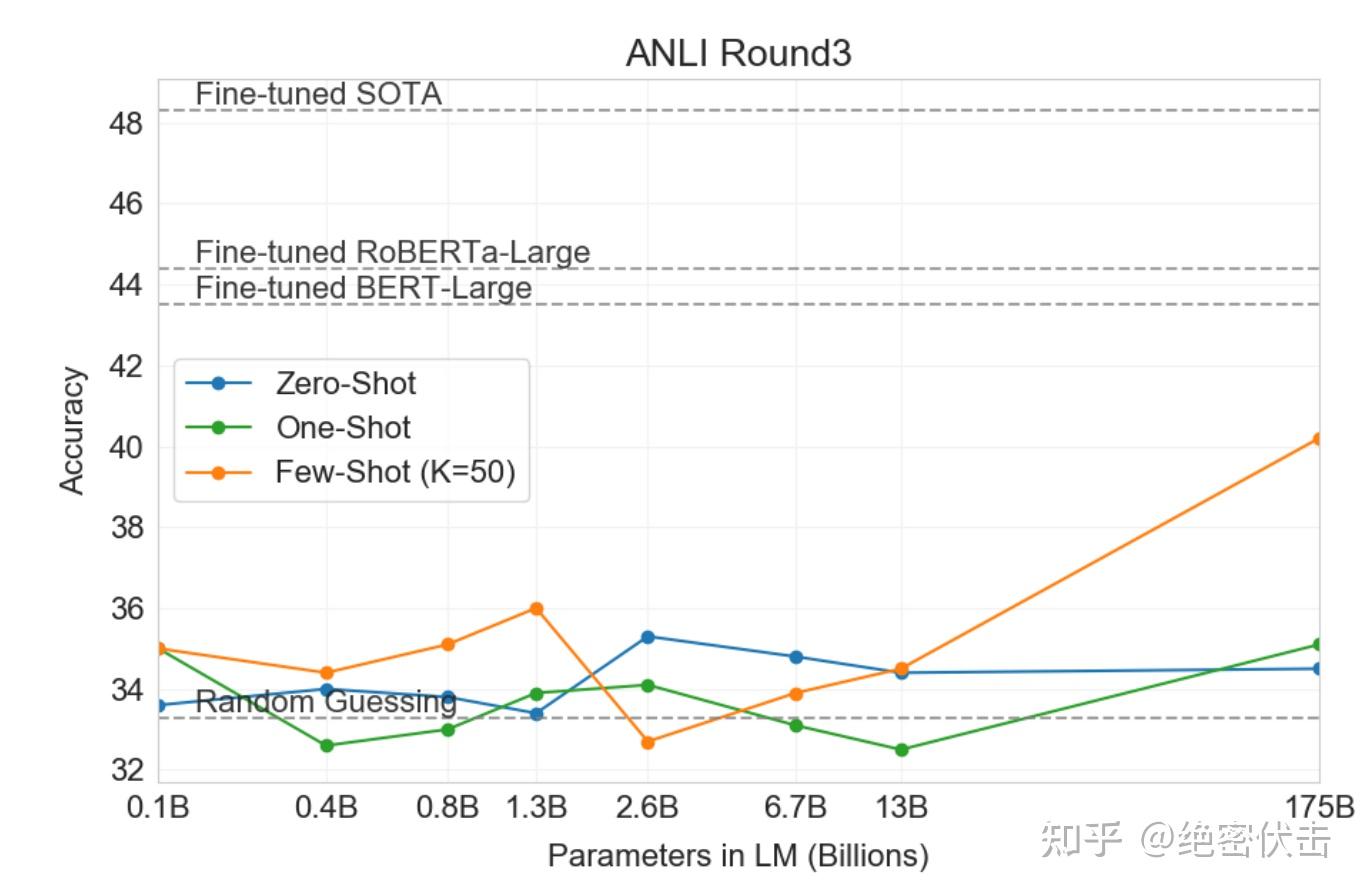
自然语言推理(NLI)是指理解两个句子之间的关系的能力。在实践中,这个任务通常被构建成一个两类或三类分类问题,模型需要判断第二个句子是否从第一个句子逻辑上推出、是否与第一个句子相矛盾,或者是可能为真的情况。SuperGLUE 包括一个 NLI 数据集 RTE,评估二分类版本的任务。在 RTE 上,只有最大的 GPT-3 版本在任何评估设置下表现得比随机好(56%),但在 few-shot 设置下,GPT-3 的表现与单任务 fine-tuned 的 BERT Large相似。同时考虑在最近推出的对抗性自然语言推理(ANLI)数据集上进行评估。ANLI 是一个难度很大的数据集,采用了一系列经过对抗挖掘的自然语言推理问题,分为三轮(R1、R2和R3)。与 RTE 类似,所有比 GPT-3 小的模型在 ANLI 上的表现几乎等同于随机猜测,即使是在 few-shot 设置下也是如此(约33%),而 GPT-3 本身在第三轮中展现出了生命迹象。ANLI R3 的结果在图3.9中进行了突出显示。这些结果在 RTE 和 ANLI 上表明,NLI 对于语言模型仍然是一个非常困难的任务。
3.9 Synthetic和Qualitative任务
为了测试 GPT-3在 few-shot(zero-shot 和 one-shot)情况下的能力范围,一种方法是给它一些需要进行简单即时计算推理、识别不太可能在训练中出现的新颖模式或快速适应不寻常任务的任务。OpenAI 设计了几个任务来测试这一类能力。首先,测试了 GPT-3 执行算术的能力。其次,创建了几个涉及重新排列或拼写单词的任务,这些任务在训练过程中不太可能完全出现。第三,测试 GPT-3 在 few-shot 情况下解决 SAT 式类比问题的能力。最后,对 GPT-3 进行了几个定性任务的测试,包括在句子中使用新单词、纠正英语语法和新闻文章生成。
3.9.1 算数任务
为了测试 GPT-3 在没有特定任务训练的情况下执行简单算术操作的能力,OpenAI 开发了一个包含10个测试的小型测试集,这些测试涉及以自然语言形式向 GPT-3 提出简单的算术问题:
- 2 digit addition (2D+):模型被要求回答一个自然语言描述的简单的两位数加法问题,其中加数和被加数随机抽取于[0,100)的范围内。例如,“Q: What is 48 plus 76? A: 124.”
- 2 digit subtraction (2D-):模型被要求减去两个均匀采样自[0100)的整数;答案可能为负数。例如:“Q:34减去53是多少?A:-19”
- One-digit composite (1DC):这个测试要求模型在三个一位数上执行一个复合运算,其中最后两个数字用括号括起来。例如,“Q: What is 6+(48)? A: 38”
在所有10个任务中,模型必须精确地生成正确的答案。对于每个任务,生成了一个包含2,000个随机实例的数据集,并在这些实例上评估所有模型的性能。
首先,在 few-shot 的情况下评估 GPT-3,结果显示在图3.10中。对于加法和减法,在数字位数较小时,GPT-3表现出强大的熟练度,2位数加法达到100%的准确率,2位数减法为98.9%,3位数加法为80.2%,3位数减法为94.2%。随着数字位数的增加,性能会下降,但是GPT-3仍然可以在四位数操作上实现25-26%的准确率,在五位数操作上实现9-10%的准确率,这表明至少有一定的通用性能力。GPT-3在2位数乘法上也达到了29.2%的准确率,这是一项特别需要计算能力的操作。最后,GPT-3在单个数字的复合运算上实现了21.3%的准确率(例如,9 *(7 + 5)),表明它具有一定的稳健性,不仅仅是单一运算。
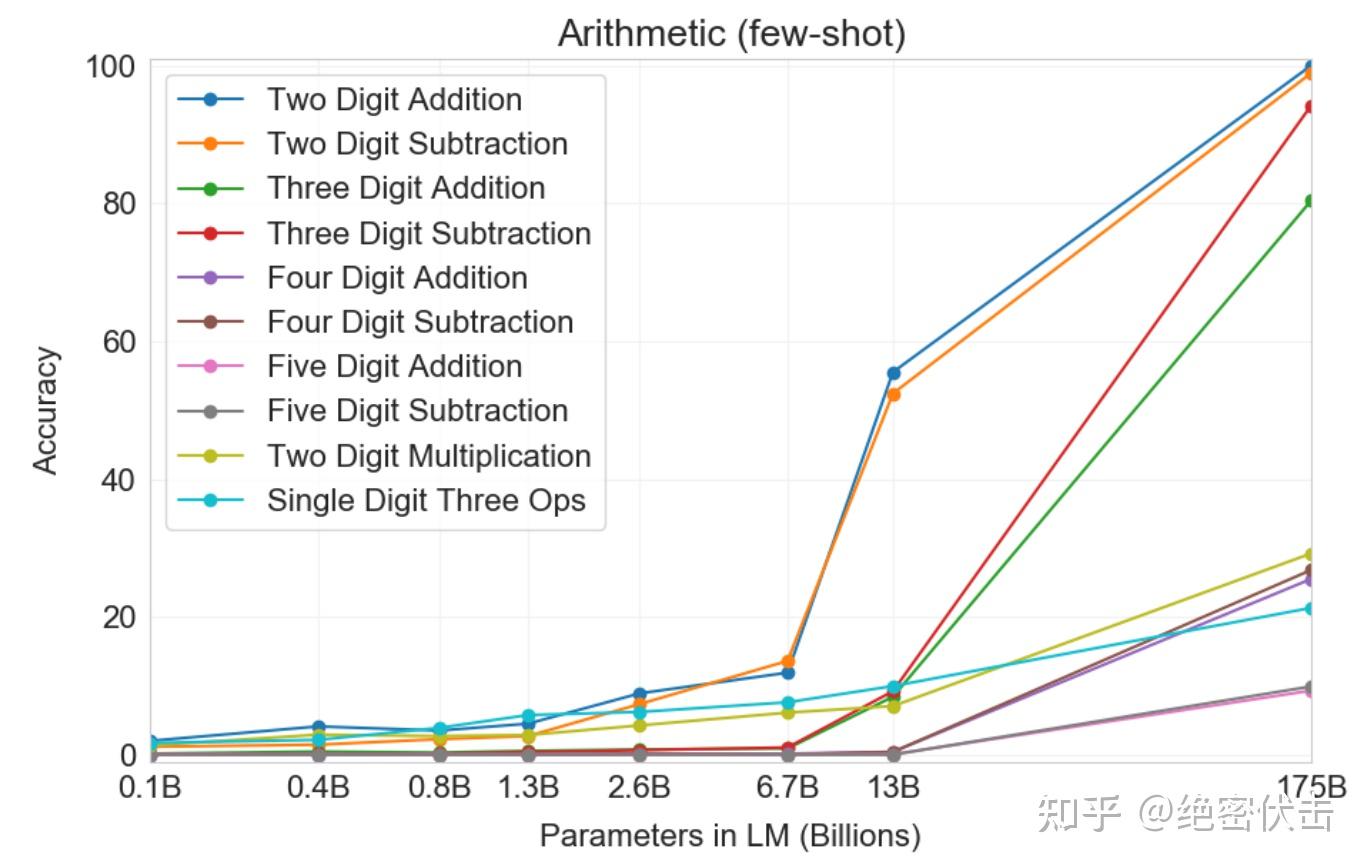
如图3.10所示,小模型在所有这些任务上表现都很差 ,即使是130亿参数的模型,也只能一半的时间解决两位数的加减法,以及其他所有操作不到10%的时间。
one-shot 和 zero-shot 性能相对于 few-shot 的表现略有下降,这表明适应任务(或者至少是任务的识别)对于正确执行这些计算是很重要的。尽管如此,一次性表现仍然非常强大,甚至全面的 GPT-3 的 zero-shot 性能在所有较小的模型中都优于 few-shot 学习。所有三种 GPT-3 设置的性能都显示在表3.9中。

为了检查模型是否仅仅是记忆了特定的算术问题,在测试集中选取了3位数字的算术问题,并在训练数据中搜索了形式为"<NUM1> + <NUM2> ="和"<NUM1> plus <NUM2>"的问题。在2,000个加法问题中,只发现了17个匹配项(0.8%),在2,000个减法问题中,只发现了2个匹配项(0.1%),这表明只有极小一部分正确答案可能已经被记忆。此外,检查错误答案显示,模型经常犯错,例如没有进位“1”,这表明它实际上正在尝试执行相关的计算,而不是记忆表格。
总的来说,GPT-3在few-shot、one-shot,甚至zero-shot情况下都表现出了合理的计算能力。
3.9.2 Word Scrambling and Manipulation Tasks
为了测试 GPT-3 从少量示例中学习新的符号操作的能力,设计了一个小的“字符操作”测试集,包含5个任务。每个任务都涉及到给定一个被扭曲的单词,通过某些字符的混淆、添加或删除,要求模型恢复原始单词。这5个任务包括:
- Cycle letters in word(CL): 模型获得一个字母顺序循环的单词,后跟“=”符号,需要生成原始单词。例如,给定“lyinevitab”,然后输出“inevitably”。
- Anagrams of all but first and last characters (A1) :模型会得到一个单词,其中除了第一个和最后一个字母以外的每个字母都被随机重新排列,必须输出原始单词。例如:criroptuon = corruption
- Anagrams of all but first and last 2 characters (A2):给定一个单词,除第一个和最后两个字母外,其余字母均被随机排列,模型需要恢复原始单词。例如,给定单词 "opponent",则应输出 "opponent"。
- Random insertion in word (RI) :在一个单词中每个字母之间插入随机的标点符号或空格,模型必须输出原始单词。例如:s.u!c/c!e.s s i/o/n = succession.
- Reversed words (RW):给定一个单词的倒序拼写,模型必须输出原始单词。例如:stcejbo → objects.
针对每个任务,生成了 10,000 个示例,这些示例是由长度大于 4 个字符且小于 15 个字符的最常见的 10,000 个单词组成。few-shot 的结果如图 3.11 所示。任务表现通常会随着模型规模的增加而平滑增长,完整的 GPT-3 模型在 RI 任务的表现达到了 66.9%,在 CL 上达到了 38.6%,在更容易的 A1 任务上达到了 40.2%,在更难的 A2 任务上达到了 15.1%。没有一个模型能完成 RW 任务。
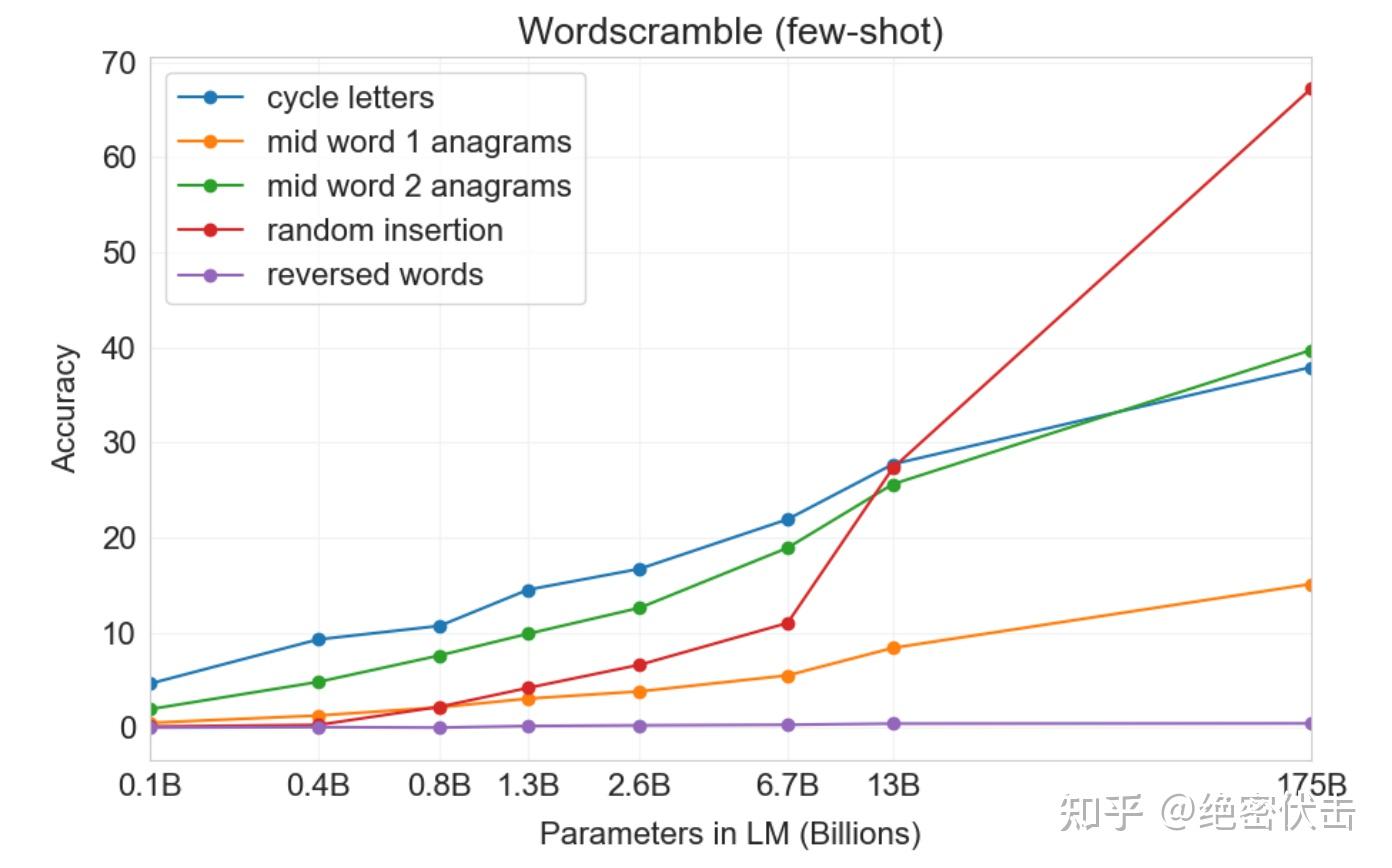
在 one-shot 设置中,性能显着较弱(下降一半或更多),在 zero-shot 设置中,模型几乎无法执行任何任务(表3.10)。这表明,模型似乎确实在测试时间学习这些任务,因为模型无法进行 zero-shot,并且它们的人工性质使得它们不太可能出现在预训练数据中。
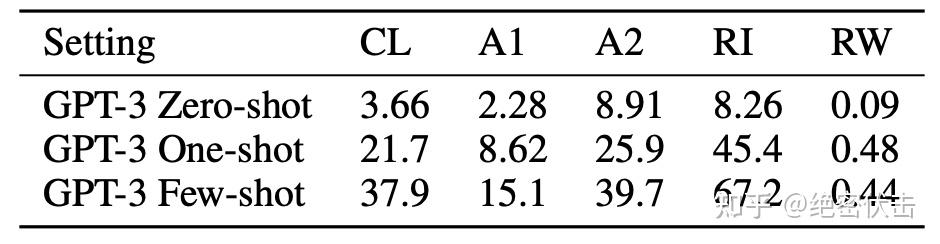
最后值得一提的是,解决这些任务需要进行字符级别的操作,而 BPE 编码是对单词的重要部分进行操作的(平均每个token操作的单词部分约为0.7),因此从语言模型的角度来看,成功地完成这些任务不仅需要对 BPE token 进行操作,还需要理解并分解其子结构。
3.9.3 SAT Analogies
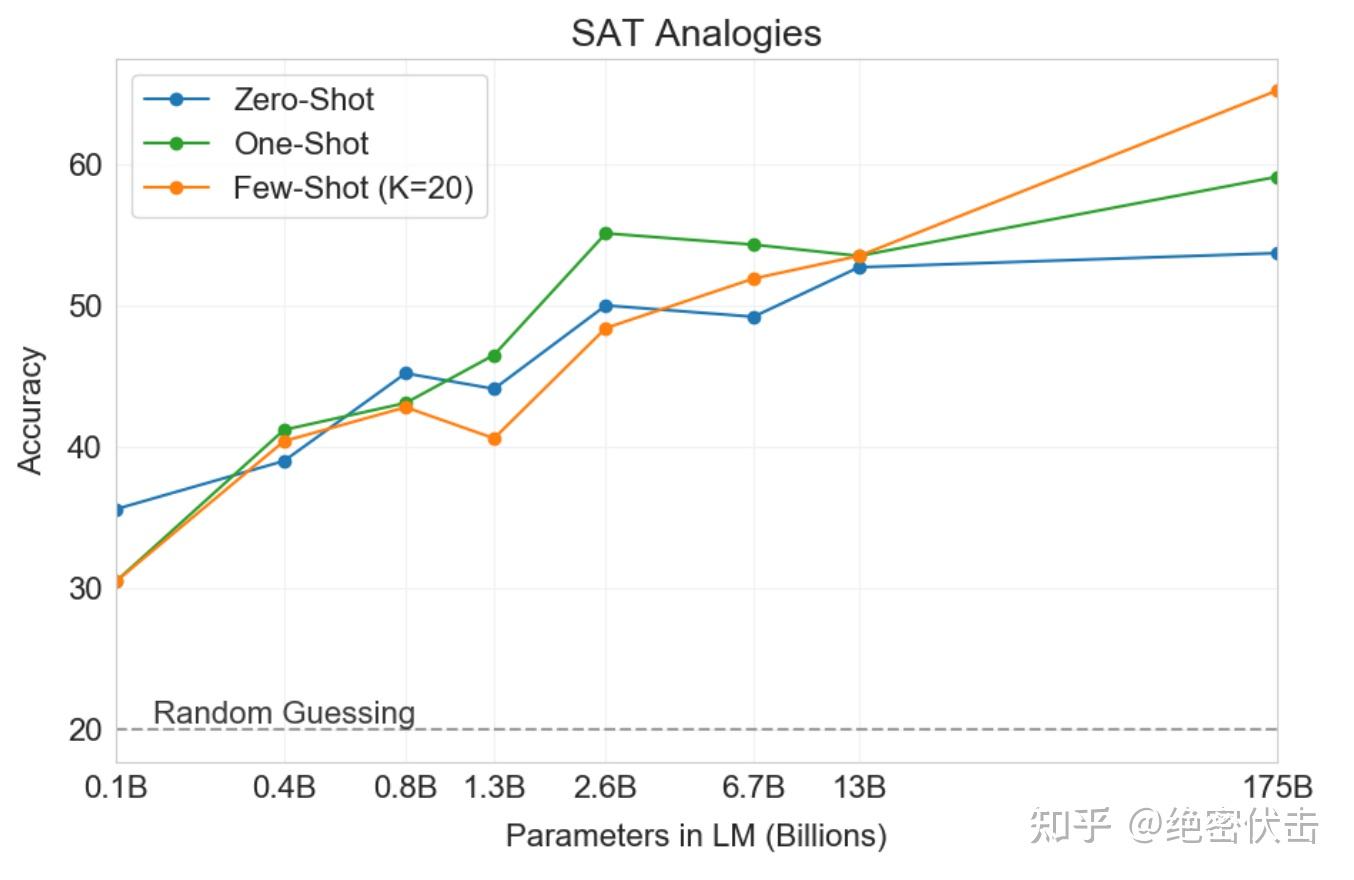
为了测试 GPT-3 在与典型文本分布有所不同的任务上的表现,研究人员收集了374个SAT Analogies。Analogies是一种多项选择题,曾在2005年之前的 SAT 大学入学考试中占据一部分。一个典型的例子是“audacious是boldness,sanctimonious是什么?(a)hypocrisy,(b)identity,(c)misdeed,(d)result,(e)temptation”。学生应该选择哪个与原始单词对具有相同关系的五个单词对中的单词对;在这个例子中,答案是“sanctimonious是hypocrisy”。在这个任务中,GPT-3 在 few-shot 设置下达到了65.2%的准确率,在 one-shot 设置下为59.1%,在 zero-shot 设置下为53.7%,而在大学申请者中的平均分数为57%(随机猜测得分为20%)。如图3.12所示,随着规模的增加,结果得到了提高,完整的1750亿模型相比于130亿参数的模型提高了10%以上。
3.9.4 新闻文章生成
之前的生成语言模型的研究通过给定一个合理的新闻故事的首句人工提示,从模型中进行条件抽样,从而定性地测试其生成合成“新闻文章”的能力。相比较而言,用于训练 GPT-3 的数据集在新闻文章方面的权重要少得多,因此通过原始无条件样本生成新闻文章的效果较差。例如,GPT-3 经常会将“新闻文章”的建议首句解释为推文,然后发布合成回复或跟进推文。为了解决这个问题,OpenAI 利用了 GPT-3 的 few-shot 学习能力,通过提供模型上下文中的三篇以前的新闻文章来进行条件学习。给定下一篇文章的标题和副标题,模型能够可靠地生成“新闻”类型的短文章。
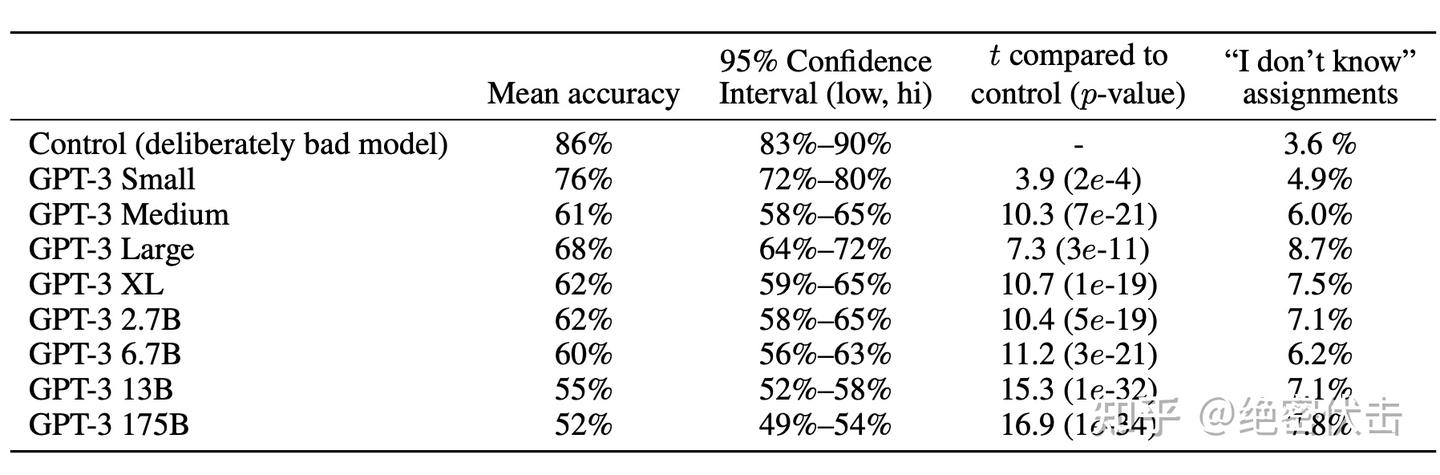
为了看人类能否很好地检测模型生成的文本,随机选择了25个文章标题和副标题,这些标题和副标题来自于http://newser.com网站(平均长度:215个单词)。然后,从四个不同大小的语言模型中(参数从125M到175B(GPT-3)不等,平均长度为200个单词)生成这些标题和副标题的文本。对于每个模型,向约80名美国参与者呈现了这些真实的标题和副标题,随后是人类撰写的文章或由模型生成的文章。参与者需要选择文章是“非常可能由人编写的”、“更可能由人编写的”、“我不知道”、“更可能由机器编写的”还是“非常可能由机器编写的”。
在检测人工生成的有意的差文章时,人类的平均准确率约为86%。相比之下,检测由175B参数模型生成的文章时,人类平均准确率仅略高于偶然水平,约为52%(见表3.11)。人类检测模型生成文本的能力似乎随着模型大小的增加而减弱:似乎存在一种趋势,即随着模型大小的增加,人类检测模型的准确率接近于偶然水平。
在图3.14和图3.15中给出了 GPT-3 合成文章的示例。正如评估所示,其中很多文本对人类难以与真实的人类内容区分开来。事实上不准确可能表明文章是由模型生成的,因为与人类作者不同,模型无法获得文章标题所指的具体事实或文章的撰写时间。其他指标包括重复、不连贯和不寻常的措辞,尽管这些指标通常足够微妙,以至于人们往往没有注意到。
为了初步探究人类在检测由 GPT-3 175B 生成的较长新闻文章方面的能力,从路透社中选择了12篇全球新闻文章,平均长度为569个单词,GPT-3 生成了这些文章的完整版本,平均长度为498个单词。按照上述方法,进行了两项实验,每项实验约有80名美国参与者,以比较人类检测 GPT-3 生成文章能力。
实验表明由 GPT-3 175B 生成的长篇文章,人类识别准确率仍然只略高于52%。这表明,对于长度约为500个单词的新闻文章,GPT-3 仍然会生成人类很难区分是否为人类写作的文章。
3.9.5 学习和使用新词汇
发展性语言学研究中探讨的一项任务是学习和使用新单词的能力,例如在仅看过一次定义后在句子中使用单词,或者从仅有的一次使用中推断出单词的含义。OpenAI 定性地测试了 GPT-3 在前者方面的能力。具体来说,给 GPT-3 一个不存在单词的定义,例如 “Gigamuru”,然后要求它在句子中使用该单词。提供了一到五个先前例子,这些例子是关于另一个不存在单词的定义和使用,因此在广义任务的先前例子方面,这个任务是 few-shot,而在特定单词方面是 one-shot。图3.16显示了生成的6个示例;所有定义都是人为生成的,第一个答案是人为生成的用于条件限定,而后续答案则由 GPT-3 生成。这些示例在一次会议中持续生成,没有省略或反复尝试任何提示。在所有情况下,生成的句子似乎都是单词的正确使用。在最后一个句子中,模型为单词“screeg”生成了一个合理的变形(即“screeghed”)。总的来说,GPT-3 似乎至少在使用新单词的任务上表现得很好。

3.9.6 矫正英语语法
另一个非常适合 few-shot 学习的任务是矫正英语语法。在 few-shot 学习环境中使用 GPT-3 进行测试,通过给出形式为“错误的英语输入:<句子>\n 正确的英语输出:<句子>”的提示来完成这项任务。给 GPT-3 一个人类生成的纠正,然后要求它纠正5个以上的错误(同样没有省略或重复)。结果如图3.17所示。

4. 评估、防止测试数据出现在训练样本
由于训练数据集来自于互联网,因此模型可能在一些基准测试集上进行了训练。准确检测互联网数据集中的测试污染是一个新的研究领域,目前尚未建立最佳实践。虽然通常在训练大型模型时不会检查污染情况,但考虑到预训练数据集的不断增加,因此这个问题变得越来越重要,需要采取措施来衡量和防止基准测试的记忆化。
这种担忧不仅仅是理论上的。在最早的一篇使用 Common Crawl 数据训练语言模型的论文中,作者发现并移除了一个与他们的评估数据集重叠的训练文档。其他一些工作,例如 GPT-2 也进行了事后的重叠分析。他们的研究相对令人鼓舞,发现尽管模型在训练和测试数据集之间有一定的重叠,但由于受到污染的数据仅占一小部分(通常仅有几个百分点),这并没有对结果产生显著影响。
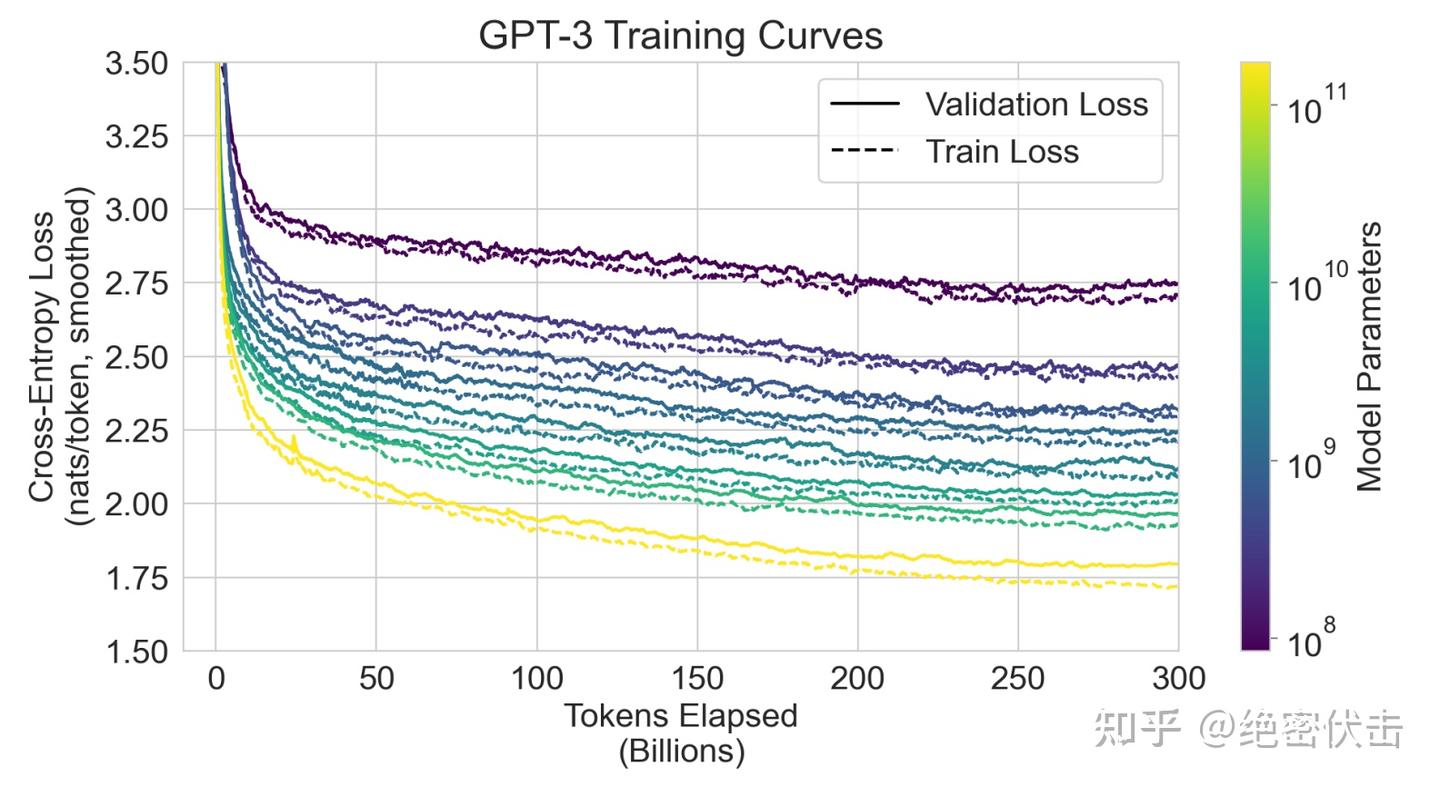
GPT-3 处于一种略微不同的运行模式。一方面,数据集和模型大小比 GPT-2 大两个数量级,并且包含大量的Common Crawl,从而增加了污染和记忆化的潜在风险。另一方面,正是由于数据量巨大,即使对于 GPT-3 175B,相对于用于去重的保留验证集而言,它的训练集过度拟合程度并不显著(见图4.1)。因此,预计污染可能会经常发生,但其影响可能不会像人们担心的那样大。
OpenAI 最初尝试解决污染问题,通过主动搜索并尝试删除训练数据与所有基准测试集的开发和测试集之间的任何重叠。不幸的是,由于一个漏洞,OpenAI 只能从训练数据中部分删除所有检测到的重叠部分。由于训练成本的原因,重新训练模型是不可行的。
对于每个基准测试,生成一个“干净”的版本,删除所有可能泄露的示例,大致定义为与预训练集中的任何内容具有13-gram 重叠(或者当它的长度小于13-gram 时与整个示例具有重叠)。目标是非常谨慎地标记任何可能存在污染的内容,以产生一个自信度很高的不受污染的子集。
然后,在这些干净的基准测试上评估 GPT-3,并将其与原始分数进行比较。如果干净子集上的得分类似于整个数据集上的得分,则表明即使存在污染,也不会对结果产生显著影响。如果干净子集上的得分较低,则表明污染可能会夸大结果。结果总结在图4.2中。尽管潜在污染通常很高(四分之一的基准测试得分超过50%),但在大多数情况下,性能变化仅微不足道,看不到污染水平和性能差异之间存在相关性的证据。可以得出结论,保守方法要么大大高估了污染,要么污染对性能的影响很小。
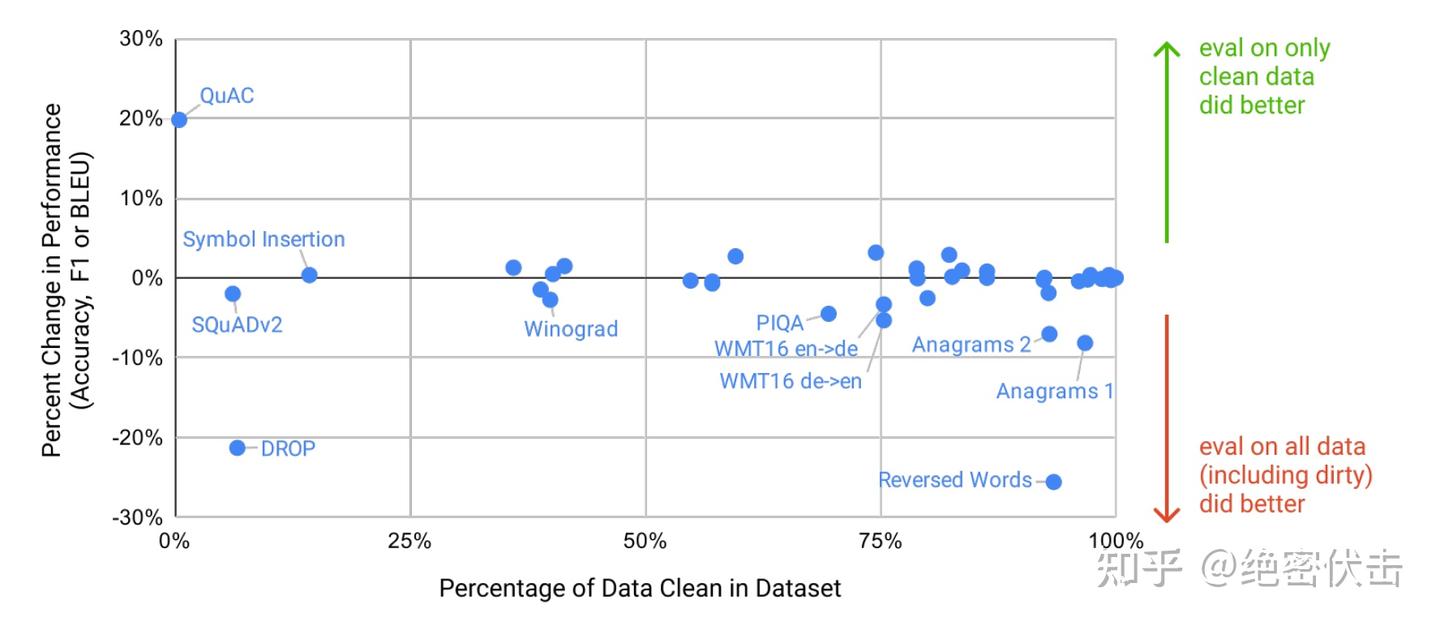
后面将更详细地审查几种特定情况,其中要么(1)模型在清理版本上表现明显更差,要么(2)潜在污染非常高,这使得测量性能差异变得困难。
分析标记了六个基准测试组以进行进一步调查:单词混淆、阅读理解(QuAC,SQuAD2,DROP)、PIQA、Winograd、语言建模任务(Wikitext任务,1BW)和德语到英语翻译。下面总结每个任务组的结果:
- 阅读理解:QuAC、SQuAD2和DROP超过90%的任务示例可能存在污染,以至于即使在一个干净的子集上测量差异也很困难。检查发现每一个重叠部分的源文本都存在于训练数据中,但问题/答案对不在其中,这意味着模型只能获取背景信息,无法记住特定问题的答案。
- 德语翻译:WMT16 德英测试集中25%的示例被标记为可能受到污染。经过检查,被标记的示例中没有一个包含与 NMT 训练数据相似的配对句子,冲突主要是单语段落,大多数是新闻中讨论的事件片段。
- 反转单词:重叠的数量很少,但是删除微不足道的任务会导致难度增加,从而产生错误的信号。与此相关的是,符号插入任务显示高重叠但对性能没有影响,这是因为该任务涉及从单词中删除非字母字符。
污染分析的一个重要限制是,无法确定干净的子集是否来自与原始数据集相同的分布。
5. 限制
GPT-3的分析具有一定限制。下面例举一些:
首先,尽管 GPT-3 在文本合成方面的整体质量很高,特别是与其直接前身 GPT-2 相比,但它仍然存在显著的弱点,在文本合成和一些 NLP 任务上都有所体现。就文本合成而言,虽然总体质量很高,但 GPT-3 有时仍会在语义上重复自己,在足够长的段落中开始失去连贯性,自相矛盾,并偶尔包含不相关的句子或段落。在离散语言任务的领域内,GPT-3 似乎在“物理常识”方面有特殊的困难,尽管在一些测试这个领域的数据集(如PIQA)上表现良好。具体来说,GPT-3 在“If I put cheese into the fridgewill it melt?”这类问题上有困难。从定量上来看,GPT-3的上下文学习表现在一系列基准测试中存在一些明显的缺陷,如第3节所述。特别是当在某些“比较”任务上进行一次甚至几次测试时(如确定两个单词在一个句子中的使用方式是否相同,或者一个句子是否暗示另一个句子(WIC和ANLI)),GPT-3 的表现几乎不比随机猜测更好,以及在阅读理解任务的子集上。这一点特别引人注目,因为GPT-3 在许多其他任务上表现出色,尤其是在几次测试中。
GPT-3 存在几个结构和算法上的局限性,这些局限性可能解释了上述一些问题。GPT-3 专注于自回归语言模型中的上下文学习行为,因为这种模型类别的采样和计算似然函数都很简单。因此,实验中并没有包括任何双向架构或其他训练目标。这与最近的大部分文献有显著差异,在这些文献中,使用这些方法比标准语言模型表现更好。因此,这种设计可能导致在需要双向性的任务上表现更差。这可能包括填空任务,涉及查看并比较两个内容的任务,或需要重新阅读或仔细考虑长篇文章然后生成非常简短答案的任务。这可能是 GPT-3 在一些任务上落后的原因之一,例如 WIC(涉及比较两个句子中单词的用法)、ANLI(涉及比较两个句子以查看一个是否蕴含另一个)以及几个阅读理解任务(例如 QuAC 和 RACE)。有一种猜测,一个大型的双向模型在微调上会比 GPT-3 更强。在GPT-3 规模下构建一个双向模型,尝试使双向模型在few-shot或one-shot学习方面发挥作用,是未来研究的一个有前途的方向,并且可以帮助实现“最佳状态”。
扩展任何类似语言模型(无论是自回归还是双向)的LM模型,最终可能会遇到预训练目标的限制。当前的目标是平衡每个 token 的权重,并缺乏最重要的预测和次重要的预测的概念。此外,对于自监督的目标,任务规范依赖于将期望的任务强制变成预测问题,而最终,有用的语言系统(例如虚拟助手)可能更适合考虑为采取目标导向的行动,而不仅仅是进行预测。最后,大型预训练语言模型没有在其他领域的体验中建立基础,比如视频或现实世界的物理交互,因此缺乏关于世界的大量背景信息。因此,扩展纯自监督的预测可能会达到极限,并且需要使用不同的方法进行增强。在这方面有希望的未来方向可能包括从人类学习目标函数,使用强化学习进行微调,或添加其他模态(如图像)。
此外,语言模型普遍存在的另一个限制是在预训练过程中的样本效率较差。虽然 GPT-3 在测试时的样本效率迈向了更接近于人类的方向(one-shot或zero-shot),但它在预训练期间看到的文本仍远远多于一个人一生中所看到的文本。改进预训练样本效率是未来工作的一个重要方向,可能会来自于在物理世界中提供额外信息的基础,或来自于算法的改进。
GPT-3 中 few-shot 学习的一个局限,就是不确定 few-shot 学习是否实际上会在推理时“从零开始”学习新任务,或者它是否只是识别在训练过程中学习过的任务。这些可能性对于从训练集中提取的样本,其分布与测试时完全相同,到识别不同格式的相同任务,到适应通用任务的特定风格,例如问答,到完全学习新技能。例如,合成任务,如单词乱序或定义无意义的单词,似乎特别可能是从零开始学习的,而翻译明显必须在预训练期间学习。即使在预训练期间组织多样化的演示并在测试时识别它们也将是语言模型的一个进步,但精确理解 few-shot 学习的工作原理仍然是未来研究的一个重要未探索方向。
GPT-3 规模的模型存在一个限制,昂贵且难以进行推理,这可能对当前形式下这些规模的模型的实际适用性构成挑战。解决这个问题的一个可能的未来方向是将大型模型蒸馏为特定任务的小模型。像 GPT-3 这样的大型模型包含非常广泛的技能,其中大多数技能对于特定任务来说都不需要,这表明原则上可能进行激进的蒸馏。蒸馏已经在一般情况下得到了很好的探索,但尚未尝试在数千亿参数的规模上使用它,因此可能会面临新的挑战和机会。
最后,GPT-3 也存在一些深度学习系统普遍存在的限制,它的决策不容易解释,对新输入的预测不一定良好,其性能的变化比人类在标准基准测试中的变化要高得多,并且它会保留所训练数据的偏见。还有就是数据中的偏见可能导致模型生成一些带有刻板印象或偏见的内容,从社会的角度来看尤为令人担忧。
6. 更广泛的影响
语言模型在社会上有许多有益的应用,包括代码和写作自动完成、语法辅助、游戏叙述生成、改进搜索引擎响应以及回答问题。但是,它们也可能有潜在的有害应用。GPT-3 提高了文本生成的质量和适应性,超过了小模型,增加了区分机器写作和人写作的难度。
7. 相关工作
一些工作侧重于增加语言模型的参数数量和计算量,以提高生成任务性能。早期的一项工作将基于 LSTM 的语言模型扩展到了超过10亿个参数。一种方法是直接增加 Transformer 模型的大小,将参数和每个 toekn 的FLOPS按比例扩展。这个方向的工作已经逐步增加了模型的大小:在原始论文中有2.13亿个参数,300亿个参数,15亿个参数,80亿个参数,110亿个参数,最近是170亿个参数。第二种方法侧重于增加参数数量而不是计算量,以增加模型存储信息的能力而没有增加计算成本。这些方法依赖于条件计算框架,特别是混合专家方法已经用于生产1000亿参数的模型,最近是50亿参数的翻译模型,但每次前向传递中只使用了一小部分参数。第三种方法增加计算量而不增加参数;这种方法的例子包括自适应计算和通用Transformer。OpenAI 的工作侧重于第一种方法(通过简单地扩大神经网络参数和计算量),并将模型大小增加了10倍,超过了以前任何模型。
一些研究也系统地研究了规模对语言模型性能的影响。有作者发现,随着自回归语言模型的扩大,损失呈现出平滑的幂律趋势。这项工作表明,随着模型的不断扩大,这种趋势在很大程度上仍在持续(尽管在图3.1中可以看到曲线略有弯曲),并且还发现,在三个数量级的扩大中,许多下游任务也呈现出相对平滑的增长。
另一方面,还有一些研究致力于与扩展模型方向相反,试图在尽可能小的语言模型中保持强大的性能。这种方法包括 ALBERT 以及语言模型蒸馏方法。这些架构和技术可以应用于减少巨型模型的延迟和内存占用。
随着 fine-tuned 语言模型在许多标准基准任务上接近于人类表现,大量的工作已经投入到构建更困难或更开放的任务中,其中包括问答、阅读理解,以及旨在对现有语言模型构成挑战的数据集。
对于使用预训练语言模型进行 few-shot 学习的方法,尽管机制不同,但之前的研究也已经探索了将预训练语言模型与梯度下降相结合进行 few-shot 学习的方式。半监督学习是另一个具有类似目标的子领域,在这个领域中,例如 UDA 等方法也探索了当只有很少标记数据可用时的微调方法。
过去两年中语言模型的算法创新是巨大的,其中包括基于去噪的双向性,前缀 LM 和编码器-解码器架构,训练期间的随机排列,提高采样效率的架构,数据和训练程序的改进。这些技术中的许多都为下游任务提供了显着的收益。OpenAI 继续专注于纯自回归语言模型,既为了专注于上下文学习性能,也为了减少大型模型实现的复杂性。然而,后面很可能将这些算法进步纳入到 GPT-3 中,特别是在微调设置中,可以提高其在下游任务中的性能,并且将 GPT-3 的规模与这些算法技术相结合是未来工作的一个有前途的方向。
8. 总结
前面主要介绍了 GPT-3 模型的训练方法以及评测方法,它在许多NLP任务和基准测试中表现出强大的性能,包括zero-shot、one-shopt和few-shot等多种设置,在某些情况下几乎可以匹配最先进的微调模型,同时生成高质量的样本,并在实时定义的任务上表现出强大的性能。尽管存在许多限制和弱点,但这些结果表明,非常大的语言模型可能是开发适应性强、通用性好的语言系统的重要因素。
附录
A:Common Crawl数据集的过滤
正如第2.2节所述,OpenAI 采用了两种技术来提高 Common Crawl 数据集的质量:(1) 过滤Common Crawl (2)模糊去重:
- 为了提高 Common Crawl 数据集的质量,OpenAI 开发了一种自动过滤方法来删除低质量文档。使用原始的WebText 作为高质量文档的正例,训练了一个分类器来区分这些文档和原始的 Common Crawl。然后,使用这个分类器通过优先选择被预测为高质量的文档来重新采样 Common Crawl。该分类器使用 Spark 标准分词器和HashingTF 10 特征来训练逻辑回归分类器。对于正面例子,使用一个经过筛选的数据集,例如 WebText、维基百科和网络图书语料库作为正面例子,对于负面例子,使用未经过滤的 Common Crawl。使用这个分类器来对Common Crawl 文档进行评分。只保留得分高于一定阈值的文档。
选择
,以便主要选择分类器评分高的文档,但仍包括一些分布不一致的文档。选择
的目的是为了匹配分类器在 WebText 上的得分分布。这种重新加权可以提高样本质量。
- 为了进一步提高模型质量并防止过拟合(随着模型容量的增加变得越来越重要),使用 Spark 的 MinHashLSH实现(使用10个哈希函数,并使用与上面分类器相同的特征)对每个数据集中的文档进行模糊去重(即删除与其他文档高度重叠的文档)。同时模糊地从 Common Crawl 中删除了 WebText。总体而言,这将数据集大小平均减少了10%。
在过滤了重复项和低质量后,还部分地删除了出现在基准数据集中的文本。
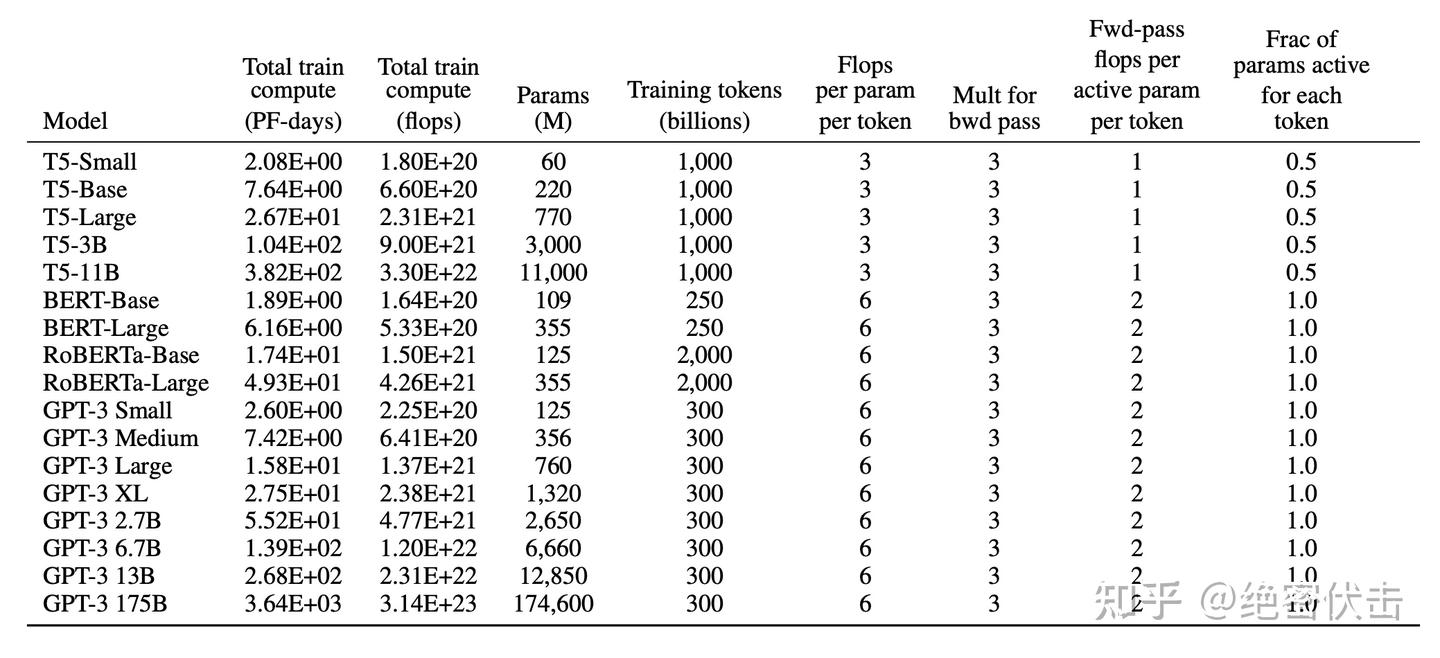
D:训练GPT-3的计算开销
表D.1是模型的计算开销:
E:评估机器生成文章
这部分主要介绍人类区分 GPT-3 生成的合成新闻文章和真实新闻文章的实验细节。首先对200字新闻文章的实验,然后是对由 GPT-3 生成的约500字新闻文章的实验。
参与者:招募了718位参与者参加了6个实验。其中97名参与者因未通过检测而被排除在外,最终留下621名参与者:343名男性,271名女性和7名其他性别。参与者的平均年龄约为38岁。所有参与者都是美国人,但没有其他人口统计限制。参与者的参与费为12美元,任务时间估计为60分钟。为确保每个实验的参与者样本是唯一的,参与者不被允许参加超过一次实验。
程序和设计:随机选择了在2020年初出现在 newser.com 上的25篇新闻文章。使用文章的标题和副标题来产生125M、350M、760M、1.3B、2.7B、6.7B、13.0B和200B(GPT-3)参数语言模型的输出。每个模型生成了五个问题的输出,选择最接近人类写作文章字数的生成结果。这是为了最小化完成长度可能对参与者判断的影响。每个模型的输出过程相同。
在每个实验中,一半的参与者被随机分配到测验A,另一半被随机分配到测验B。每个测验包含25篇文章:一半(12-13篇)是人类写作的,另一半(12-13篇)是模型生成的。
最后统计结果发现,随着模型变得更大,人类参与者区分模型生成的新闻文章和人类生成的新闻文章的能力会下降。同时,随着模型大小的增加,针对一组给定问题花费的平均时间增加。
参考
https://arxiv.org/pdf/2005.14165.pdf
AlexGoAlex:超大型人工智能:从GPT->GPT2->GPT3的发展历程+大规模预训练神经网络模型原理详解
书籍推荐
最后,打个小广告。近期,由我和电子科技大学江维教授共同合作的新书:《揭秘大模型:从原理到实战》已经在京东上线。书中重点介绍了 GPT 系列模型、Llama 系列模型的架构和训练优化,感兴趣的可以去京东购买。
感谢各位知友!