



2026年3月第一周,中国AI圈期待已久的DeepSeek V4正式发布,与此前两周谷歌推出的Gemini 3.1 Pro形成正面交锋。这不仅是两款旗舰模型的同期竞技,更是中国开源力量与美国闭源巅峰的技术路线对决:DeepSeek V4以“原生多模态+国产芯片深度适配+极致成本控制”杀入战场,而Gemini 3.1 Pro则以“ARC-AGI-2 77.1%推理断层领先+三层思考模式+幻觉抗性跃升”巩固护城河。本文从基准测试、核心架构、多模态能力、成本策略四大维度进行深度技术拆解,为开发者和AI爱好者提供硬核参考。
国内用户可通过聚合镜像平台RskAi(ai.rsk.cn)直接体验Gemini 3.1 Pro,同时等待DeepSeek V4的镜像接入,形成双模型布局——一个应对深度复杂推理,一个满足高性价比国产需求。
一、发布动态:时间线与战略意图
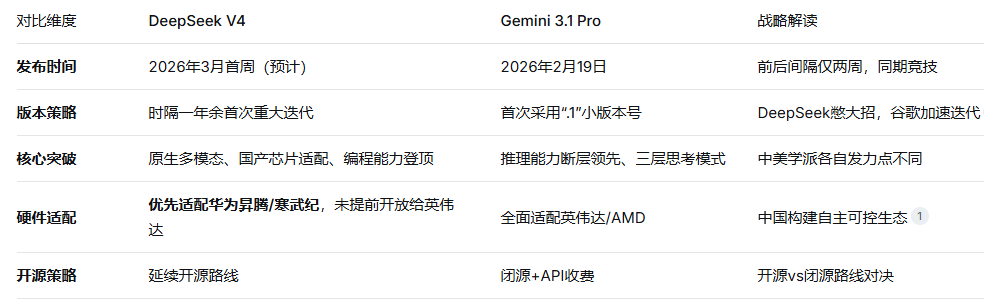
关键信号:DeepSeek V4打破了AI行业长期惯例——首次未向英伟达、AMD提供早期访问权限,而是给予华为、寒武纪等国产芯片商数周优先期。这一战略转向标志着“中国芯片+中国模型”的自主生态正式起航。
2.1 核心数据解读
Gemini 3.1 Pro的统治区:抽象推理
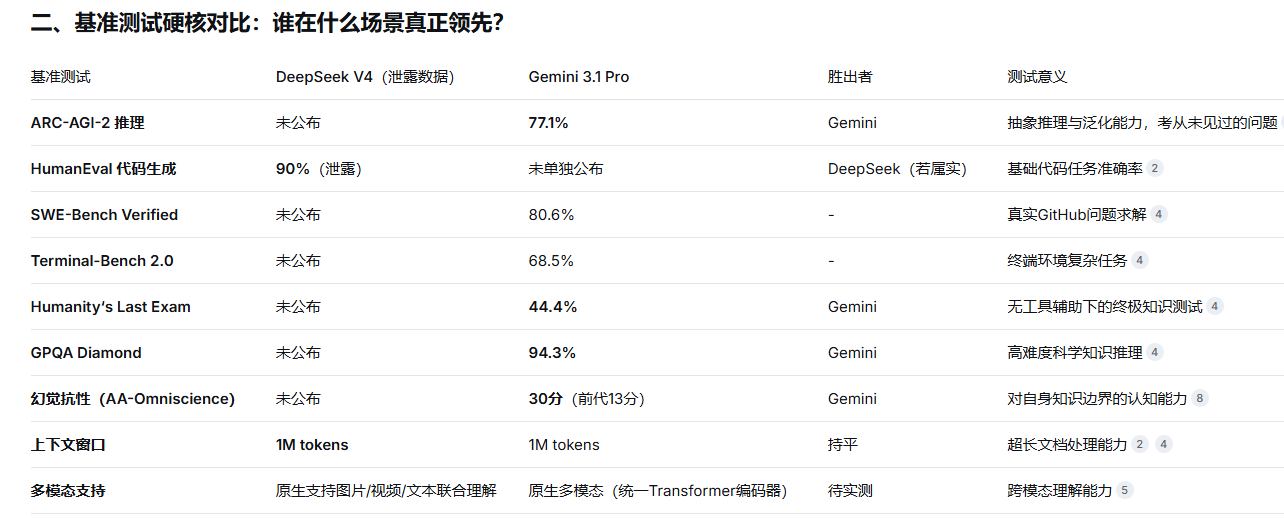
ARC-AGI-2测试中,Gemini 3.1 Pro拿下77.1% 的惊人成绩,而前代Gemini 3 Pro仅31.1%,Claude Opus 4.6为68.8%,GPT-5.2仅52.9%。这一测试不依赖知识记忆,而是考察面对陌生逻辑谜题时的多步推演能力,被视作衡量AI“流体智力”的核心指标。这意味着Gemini在处理从未见过的问题模式时,能力已发生本质性跃迁。
DeepSeek V4的杀手锏:编程能力
据泄露的内部基准测试,DeepSeek V4在HumanEval代码任务上得分高达90%,超越所有现有模型。在当前“Vibe Coding”(AI辅助编程)成为行业新趋势的背景下,这一突破可能直接推动AI Agent在软件开发领域的商业化落地。
幻觉控制:Gemini的反向领先
AA-Omniscience Index衡量的是模型“知道不知道什么”的能力——这比知道“知道什么”更难。Gemini 3.1 Pro从13分跃升至30分,远超Claude Opus 4.6的11分。这意味着当你问它不知道的问题时,它更可能说“不知道”而非胡编乱造。
三、核心技术拆解:工程创新 vs 推理突破
3.1 DeepSeek V4:mHC新架构 + DualPath推理框架
mHC架构革新
DeepSeek V4预计采用2025年底论文中提出的mHC(流形约束超连接)架构,这一全新神经网络层间连接方式解决了大模型规模扩大时的信号增益和“灾难性遗忘”问题。在参数量大幅提升的同时,保持训练稳定性和推理效率。
DualPath推理框架:打破I/O瓶颈
更值得关注的是,DeepSeek与北大、清华联合发布的DualPath推理框架,极有可能被V4采用。其核心创新在于:
问题发现:在长文本推理场景中,KV-Cache命中率高达95%以上,性能瓶颈从“计算”转移到“搬运”
双路径加载:打破传统的“存储→预填充引擎”单路径,引入“存储→解码引擎→预填充引擎”第二条路径
实测数据:离线推理吞吐量提升1.87倍,在线服务吞吐量平均提升1.96倍
这意味着在不增加硬件成本的前提下,DeepSeek V4的推理效率将实现翻倍式提升——这对成本控制至关重要。
3.2 Gemini 3.1 Pro:三层思考模式 + Deep Think技术下放
三层思考模式(Low/Medium/High)
Gemini 3.1 Pro引入了对“计算-质量-成本”三角关系的显式化管理:
Low模式:追求响应速度,适合高并发场景
Medium模式:填补空白,为日常任务提供经济选项
High模式:调用完整推理能力,处理复杂问题可能需要数分钟
这种设计让用户能够根据任务难度主动权衡成本,而非被动接受统一计价。
Deep Think技术整合
此前Gemini 3 Deep Think在ARC-AGI-2测试中取得84.6% 成绩所依赖的“并行思考技术”,已被整合进基础模型。模型能够同时探索多条解题路径,再通过内部评估筛选最优解——这是推理能力跃升的核心原因。
幻觉抗性提升的技术路径
AA-Omniscience Index从13分跃升至30分,得益于将原本用于Flash模型的强化学习技术迁移至Pro版本。这种技术栈的横向打通,比单纯的参数堆叠更有价值。
四、多模态能力:补齐短板 vs 原生优势
4.1 DeepSeek V4:从0到1的突破
DeepSeek此前最大的弱点是缺乏多模态功能。V4将原生支持图片、视频和文本的联合理解与生成,不再只是一个“文字选手”。这一补齐至关重要,因为多模态的Token消耗比纯文本高一个甚至数个数量级,是B端商业化的关键。
4.2 Gemini 3.1 Pro:原生多模态的持续进化
Gemini从设计之初就采用统一Transformer编码器处理文本、图像、音频、视频,模态间信息融合在模型底层完成。实测中,Gemini能理解复杂电路图的工作原理、将文学风格转化为网站设计、生成3D椋鸟群飞模拟并实时配乐。
典型案例:Gemini 3.1 Pro可以根据《呼啸山庄》的文学意境,自动生成一套完整的风景摄影师个人作品集网站,视觉色调与小说氛围相符。这种跨模态转换能力,是文字创作者将抽象文学内核注入数字交互界面的强大工具。
五、成本与定价策略:极致性价比 vs 性能溢价消失
5.1 DeepSeek V4的成本优势
DeepSeek系列一贯以成本控制见长。据预测,V4模型主打性能极致优化,成本较前序系列或下降40%-50%。在AI Agent时代,复杂任务的执行涉及大规模推理与长链路生成,会消耗大量Token,成本差异在这种场景下会被急剧放大。
此前V3的训练成本仅557万美元,性能却可比肩GPT-4。V4若延续这一路线,将延续“技术平权”的使命。
5.2 Gemini 3.1 Pro的定价策略
更具信号意义的是,Gemini 3.1 Pro在性能大幅提升的同时,定价反而更具竞争力:
混合价格:$4.50/百万token,低于GPT-5.2的$4.80、Claude Sonnet 4.6的$6和Claude Opus 4.6的$10
分档定价:≤200K tokens时输入$2、输出$12;>200K tokens时输入$4、输出$18
免费访问:用户无需订阅Gemini Advanced,即可在Gemini Web UI免费使用
这意味着价格战已从“性价比竞争”升级为“性能溢价消失”的新阶段。
六、生态与适配:国产算力闭环 vs Google全家桶
6.1 DeepSeek V4的战略转向
V4最值得关注的不是参数增长,而是硬件适配的战略转向:
优先适配华为昇腾、寒武纪:给予国产芯片商数周优先期进行软件优化
未提前开放给英伟达、AMD:打破行业惯例,让美国硬件在中国市场处于相对劣势
构建自主可控生态:从“用别人的芯片跑自己的模型”走向“用自己的芯片跑自己的模型”
这意味着DeepSeek V4的落地将从算力基础设施、模型生态适配到行业应用全链条释放红利。
6.2 Gemini 3.1 Pro的生态优势
Gemini的护城河不仅在于模型本身,更在于Google Cloud和Workspace构成的企业基础设施——这是OpenAI和Anthropic短期内难以复制的。部署策略分层清晰:
开发者:Gemini API、Google AI Studio、Antigravity平台
企业客户:Vertex AI和Gemini Enterprise集成
普通用户:Gemini App和NotebookLM免费使用
结论:两条路线,一个未来
DeepSeek V4与Gemini 3.1 Pro的同期竞技,本质是中国开源力量与美国闭源巅峰的技术哲学对决:
DeepSeek V4:中国工程派的集大成者,以mHC新架构+DualPath框架实现极致成本控制和推理效率提升,通过优先适配国产芯片构建自主可控生态。编程能力登顶预期+多模态补齐短板,使其成为国产AI的“全村希望”。
Gemini 3.1 Pro:美国学派的推理王者,以ARC-AGI-2 77.1%的断层领先和三层思考模式定义推理能力新高度。幻觉抗性跃升+原生多模态优势,使其在复杂推理和专业场景中无可替代。
没有哪一个能全方位取胜——会选模型的人,比只用单一模型的人更有优势。对于国内开发者和内容创作者,建议双模型布局:通过RskAi(ai.rsk.cn)可先体验Gemini 3.1 Pro的推理能力,待DeepSeek V4镜像接入后实时对比测试,为技术决策提供一手数据支撑。
DeepSeek V4的发布,标志着中国AI从“追赶者”向“并行者”乃至局部领先者的转变。而Gemini 3.1 Pro证明,谷歌正在以更激进的迭代节奏卷土重来。这场战役,才刚刚开始。
【本文完】


















 1586
1586


 到【灌水乐园】发言
到【灌水乐园】发言








