



大家好,我是二哥呀。
昨天还在用 Codex 新出的插件功能往飞书云文档上传 Markdown,今天飞书官方 CLI 就来了。
这节奏,离谱到了奶奶家。
等于说我昨天肝了一天的功能全废,真应了那句话,AI 时代,你不学,工具会自动过期。😄
飞书 CLI 是什么?
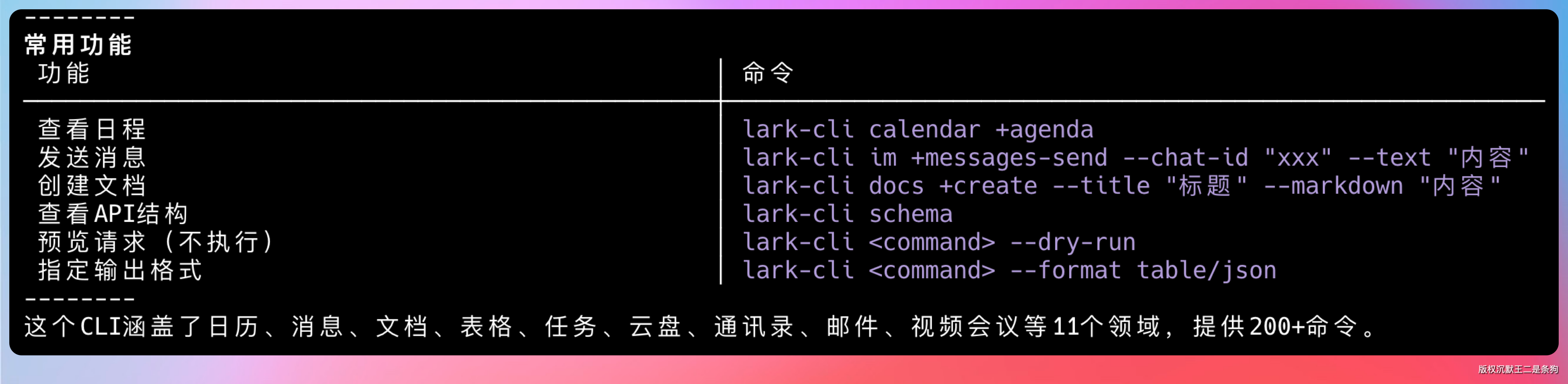
一句话概括:让 AI Agent 直接操控飞书的命令行工具。涵盖日历、消息、文档、表格、任务、云盘、通讯录、邮件、视频会议等 11 个领域,提供 200+命令。
以前你想让 AI 帮你操作飞书,得建应用、配权限、写代码、调接口,一套下来大半天没了。现在呢?装个 CLI,扫个码,Agent 就能直接干活了。
下面我把完整安装流程和三个实测案例都整理出来,跟着做就行。
01、全局安装飞书 CLI
先搞清楚我们要装的是什么东西。
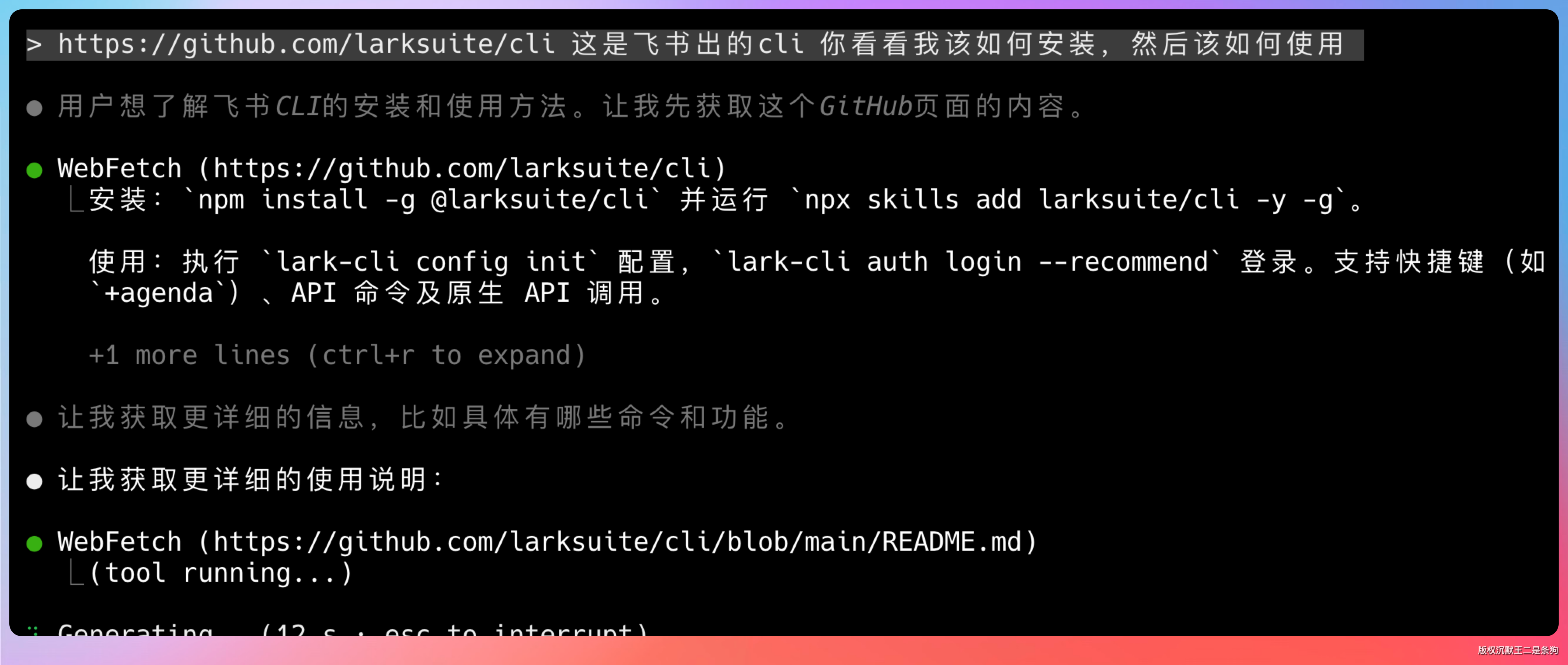
飞书 CLI 是飞书官方开源的命令行工具,托管在 GitHub 上,仓库地址是 https://github.com/larksuite/cli 。
它最大的特点是原生支持 AI Agent。
什么意思?就是你在 Claude Code、Qoder、Codex 这些 Agent 工具里,不需要任何额外配置,Agent 就能直接调用 CLI 来操作飞书。
安装方式有两种,推荐用 npm 全局安装。
打开终端,执行:
npm install -g @larksuite/cli
安装过程很快,几秒钟就搞定了。
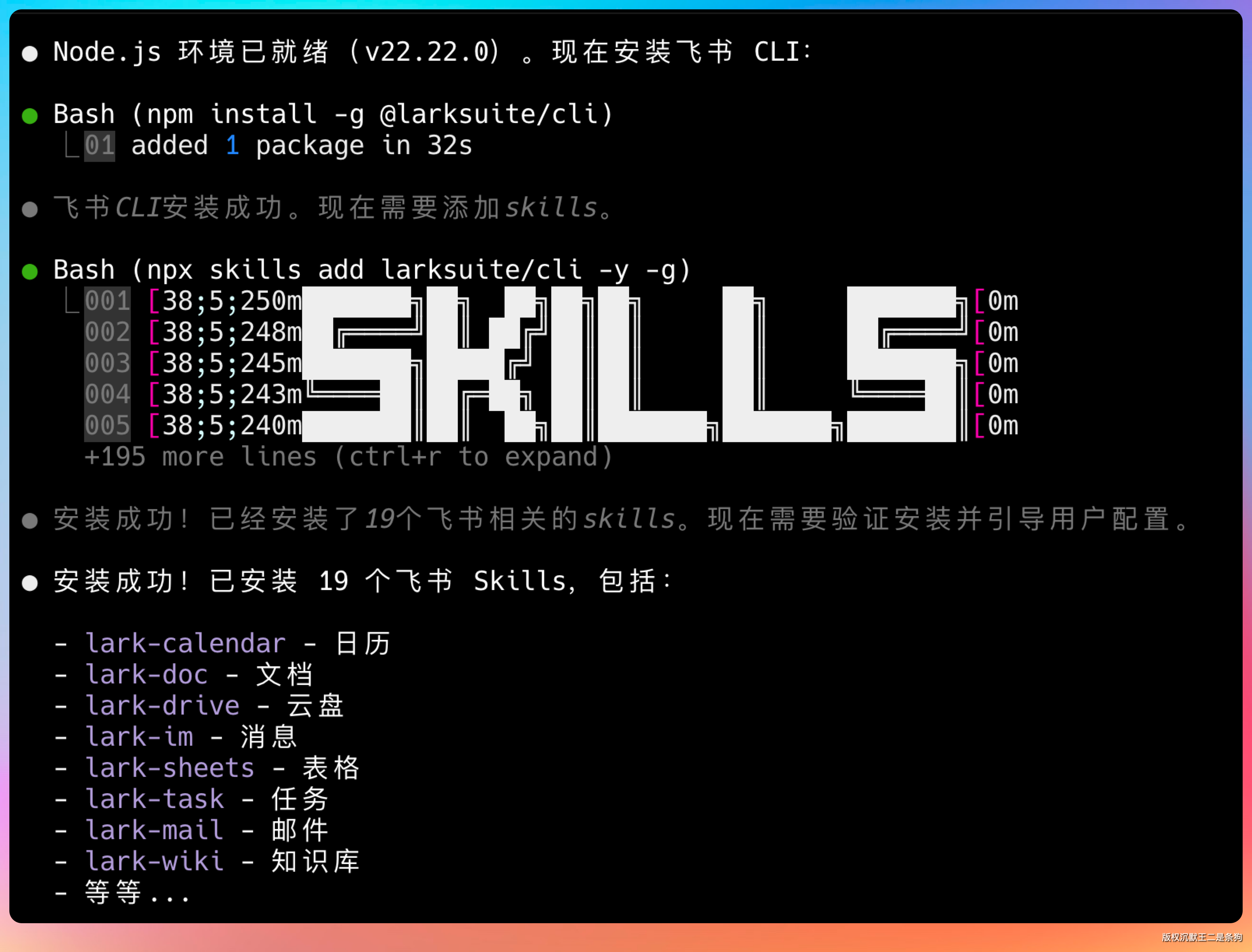
安装完成后,执行以下命令验证:
lark-cli --version
如果显示版本号,就说明安装成功了。
02、初始化配置
安装好 CLI 之后,需要进行初始化配置,把你的飞书账号和 CLI 绑定起来。
我在 Qoder CLI 里输入:
https://github.com/larksuite/cli 这是飞书出的 cli 你看看我该如何安装,然后该如何使用
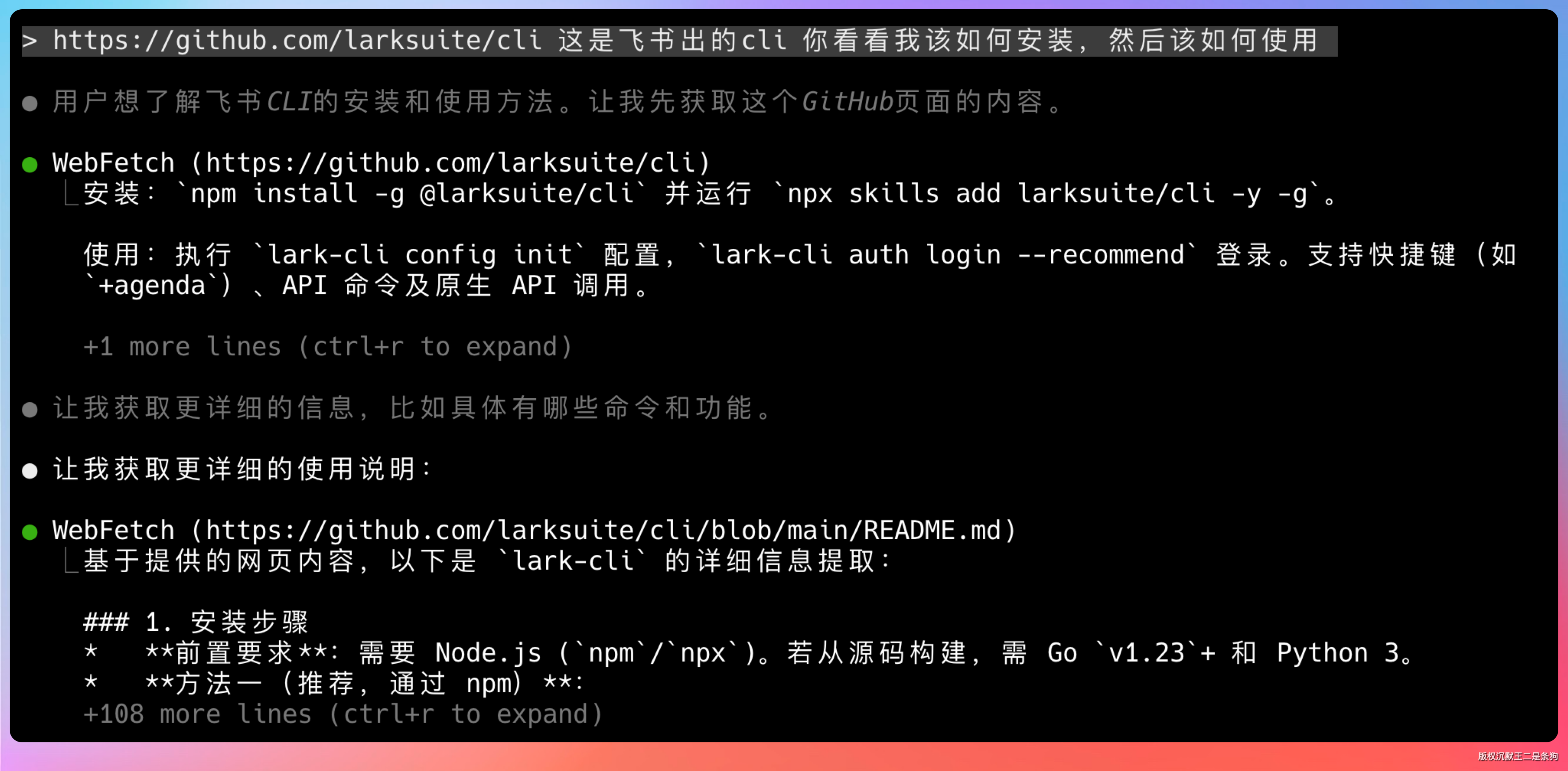
很快就安装好了,然后在控制台执行:
lark-cli config init
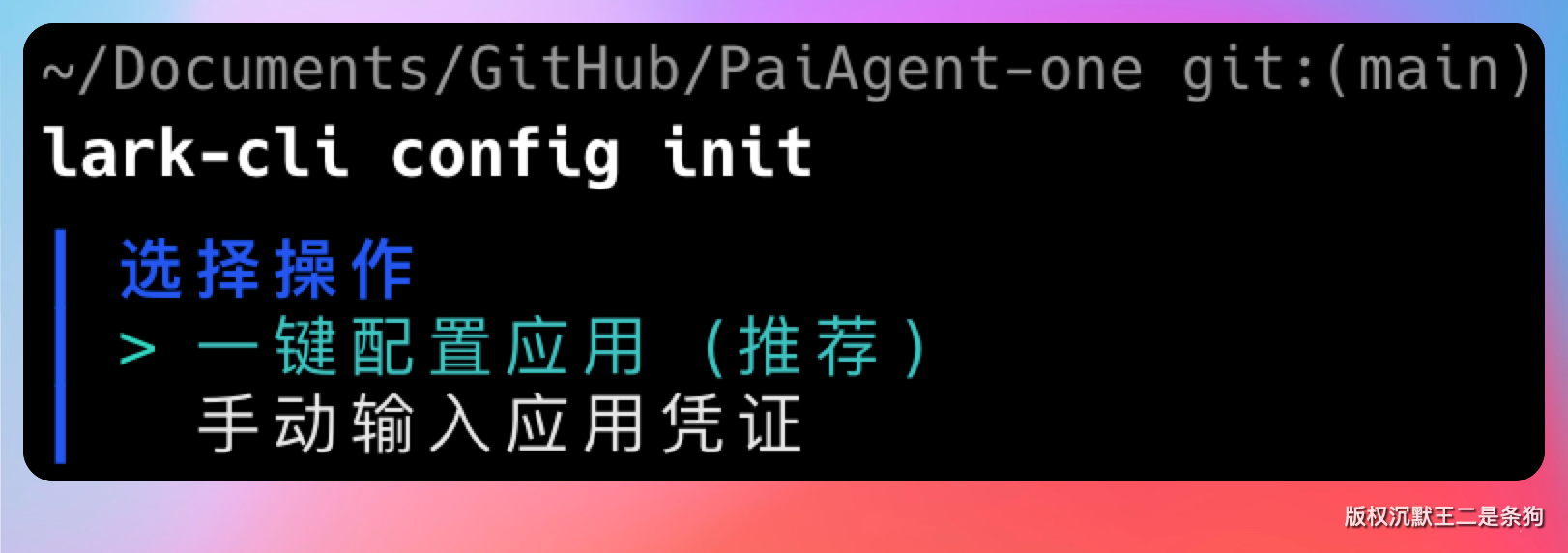
系统会问你选择飞书还是 Lark。飞书是国内版,Lark 是国际版,按你的实际需求选就行。
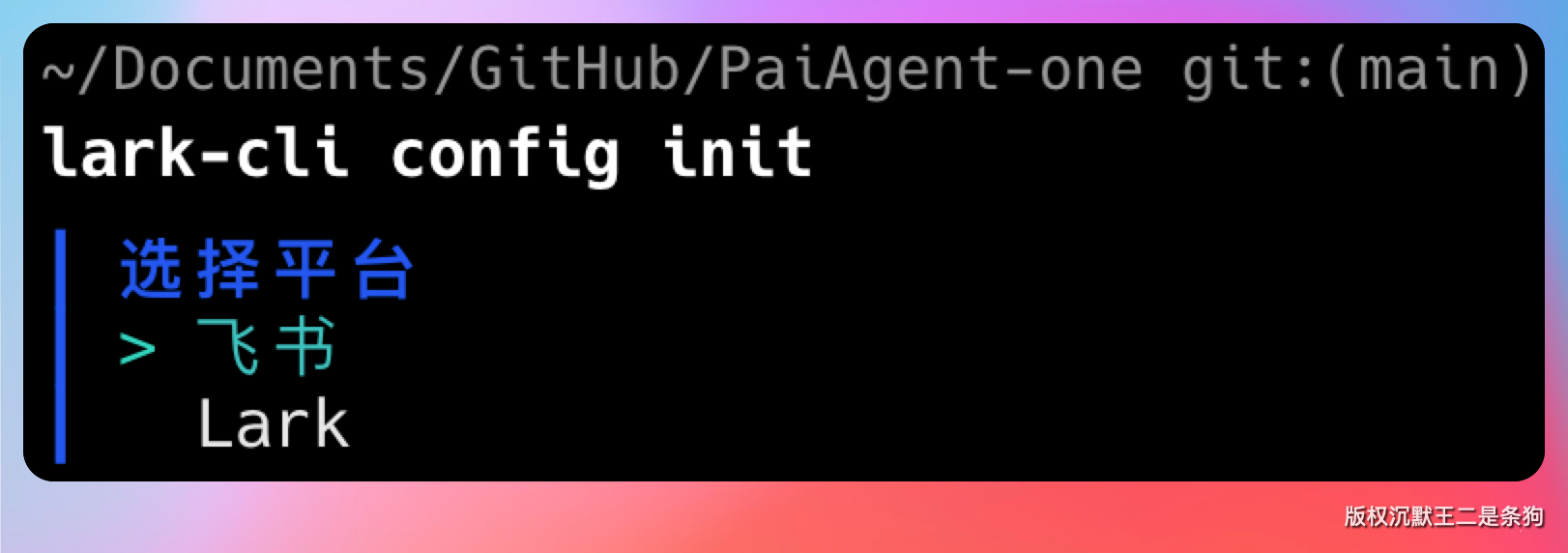
选择之后,终端会显示一个二维码。
拿起手机,打开飞书扫一扫,确认授权。整个过程和扫码登录网页版飞书一样,没什么难度。
扫码完成后,CLI 会自动获取你的用户凭证,保存在本地配置文件里。
接下来,执行登录命令:
lark-cli auth login --recommend

这个命令会为你推荐最合适的权限范围,省去手动配置的麻烦。
执行完成后,可以用这个命令查看当前登录状态:
lark-cli auth status
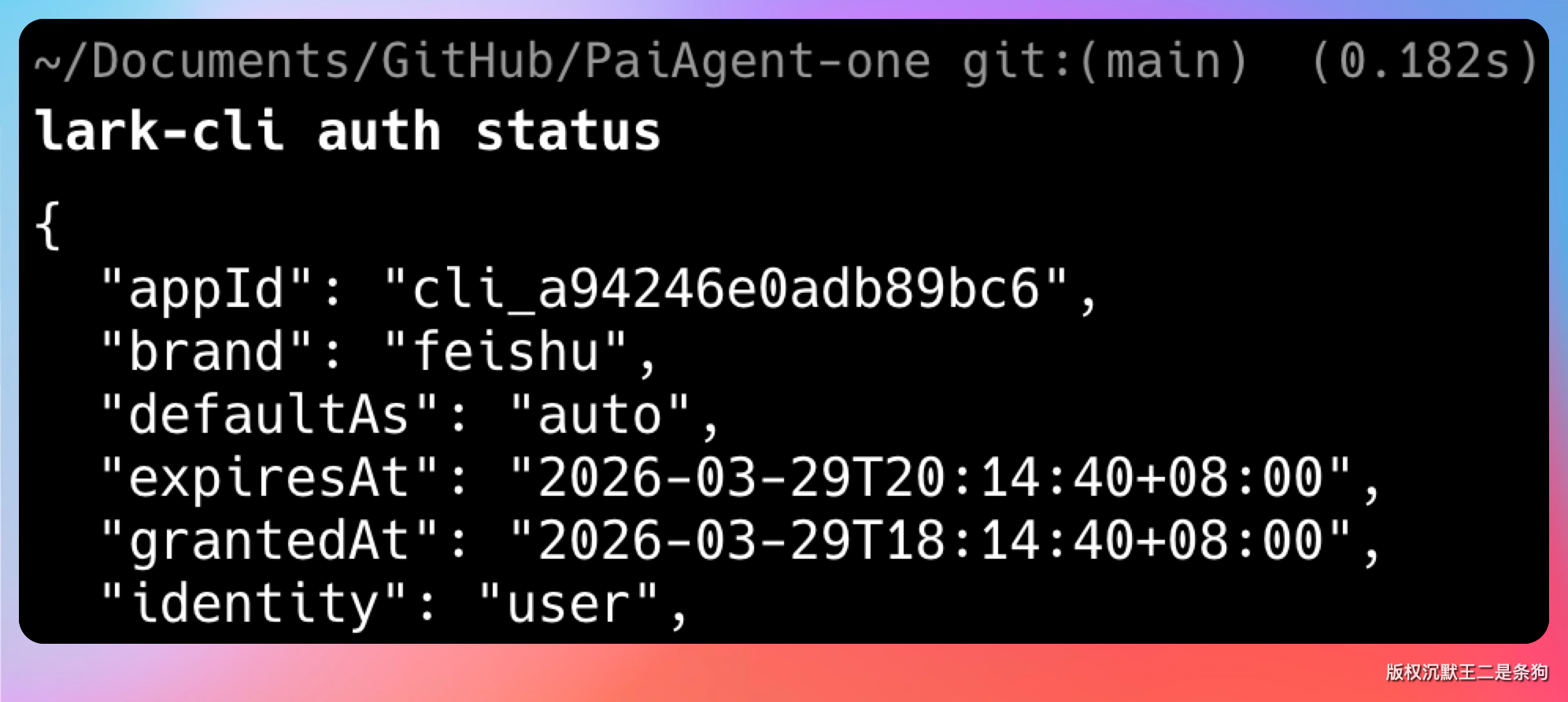
如果显示已登录,就说明配置全部搞定了。
到这一步,CLI 已经可以在终端里直接使用了。
但更重要的价值在于,它被所有 Agent 工具共享。你在 Qoder 里装一次,Codex、Claude Code 这些工具都能直接调用,不需要重复配置。
这才是 CLI 真正的杀手锏。
03、读取飞书多维表格数据
我们直接来看第一个实战案例。
我的飞书多维表格里存着 600 多条简历记录,之前想分析一下数据,得手动导出 Excel,再用 Python 写脚本处理。每次这么干都觉得挺麻烦的,导出格式要对,脚本要写,还要处理各种边界情况。
现在有了 CLI,直接让 Agent 去干。
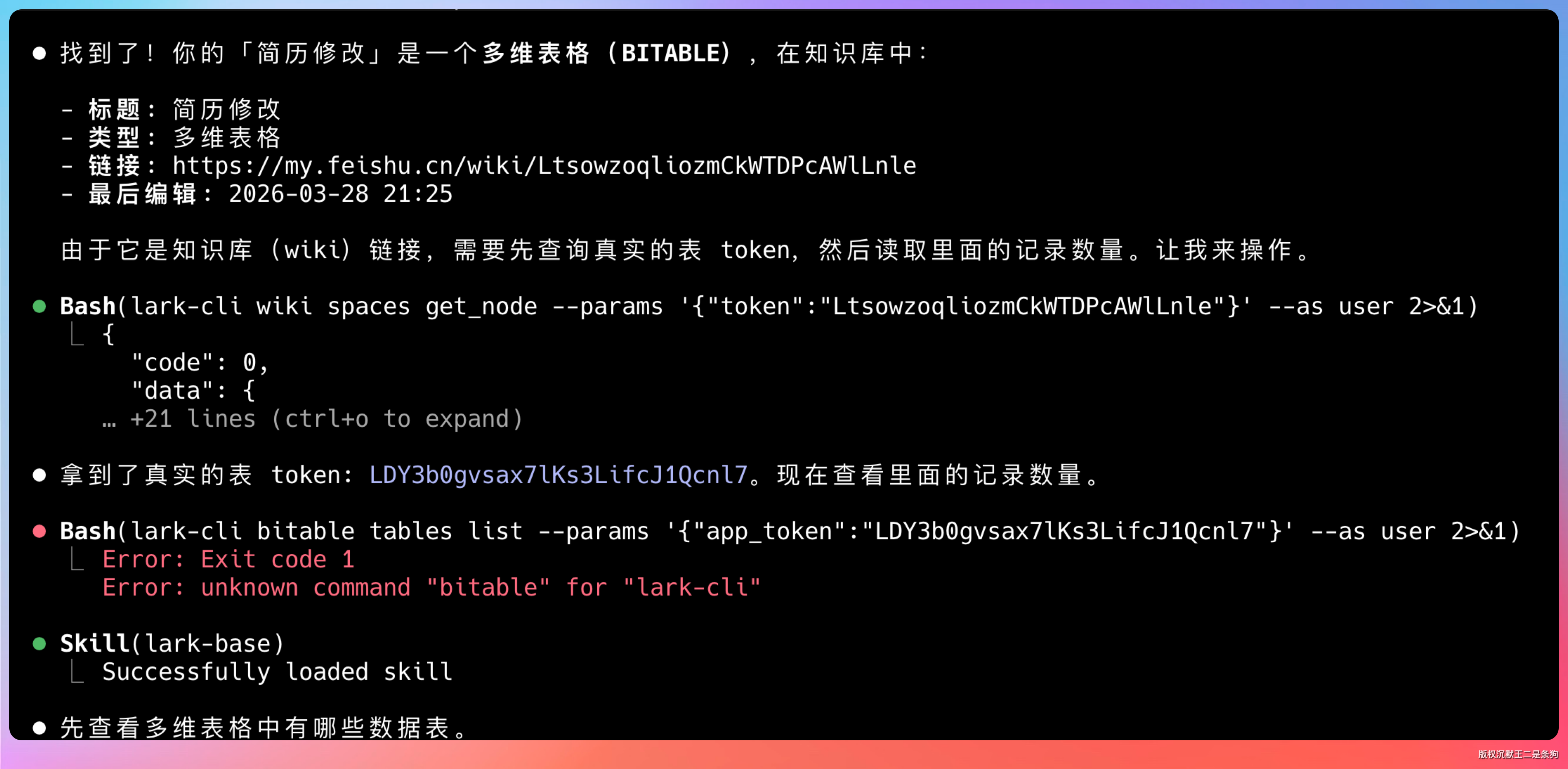
Agent 收到指令后,先是调用 CLI 搜索我的云空间,找到简历修改相关的多维表格,然后读取表格结构和数据。
整个过程不需要我指定表格的 token 或 ID,Agent 自己就能通过语义理解找到目标文档。这就是自然语言驱动的魅力,你不需要记住具体的 API 参数,只需要用大白话描述你想要什么。
第一次返回的结果是 200 条。明显不对,我的表格不止这点数据。
问题出在哪?大模型的上下文限制。某国产模型第一次只拉了 200 条就停了,没有继续分页获取。
这是 CLI 设计上的一个考量点:CLI 本身支持分页,但要不要继续拉取更多数据,取决于调用它的 Agent 是否足够聪明。
我把问题反馈给 Agent,它反应很快,意识到需要分页查询。这次重新执行后,拿到了 657 条完整数据。
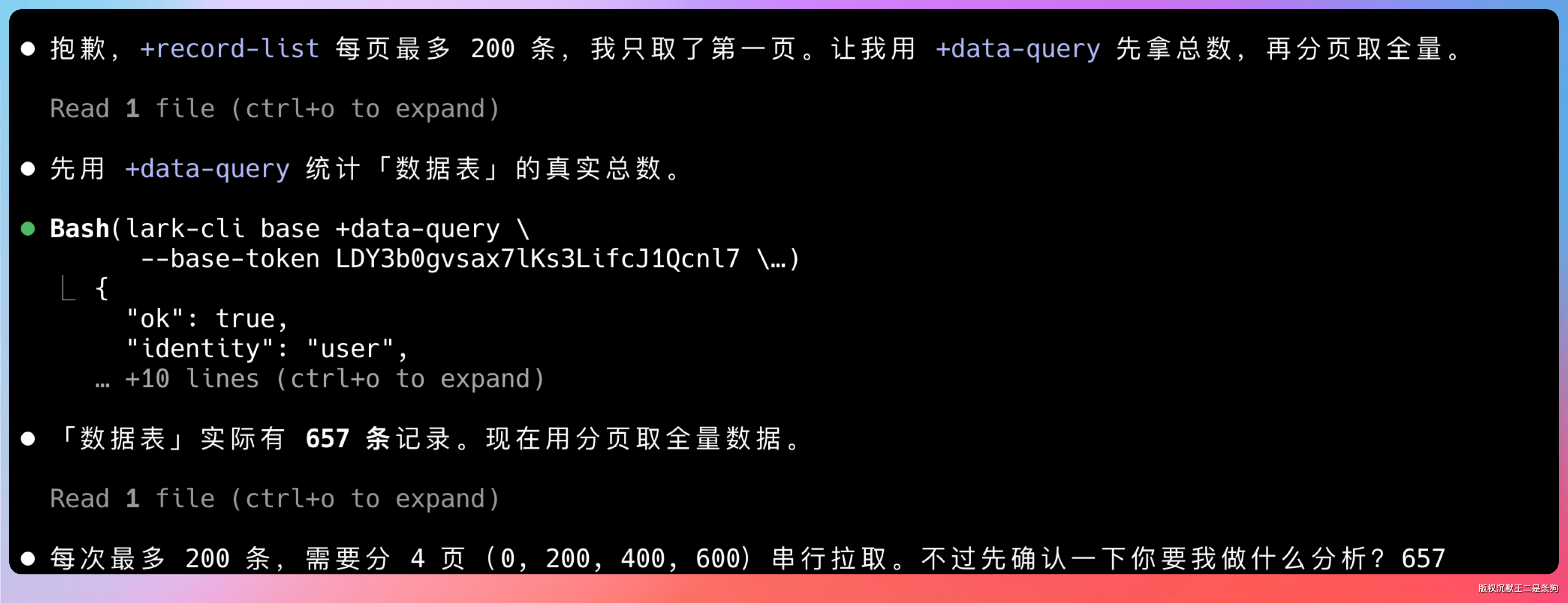
数据拿到之后,我让它做个词频统计,看看这些简历都来自哪些学校。
Agent 先是提取了学校字段,然后统计每个学校出现的次数,最后按频次排序输出。整个过程行云流水,完全不需要我干预。
结果出来了:西安电子科技大学、北京邮电大学、东南大学位列前三,总计 657 条记录,涵盖 306 所不同学校。
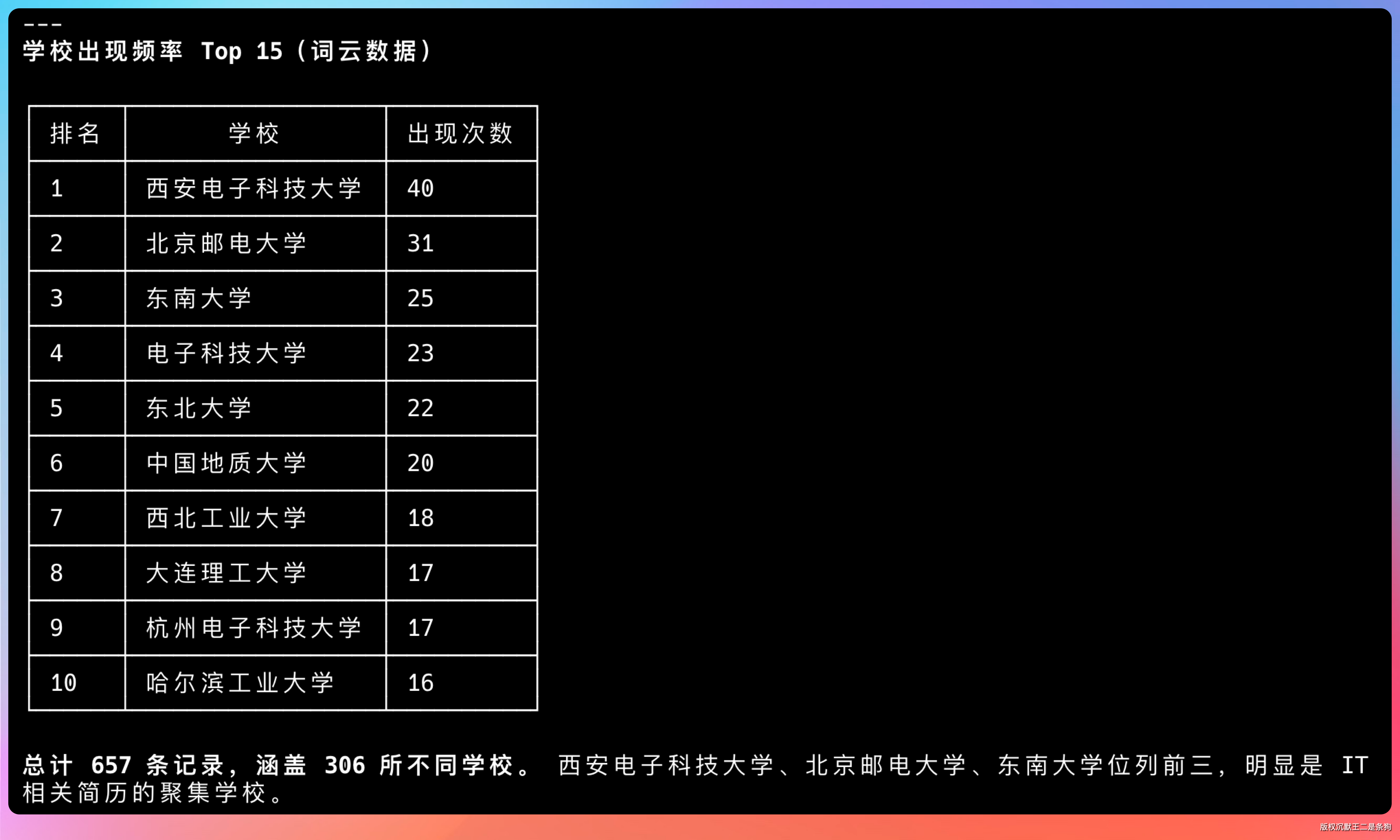
看来这几所学校里有我的铁粉,感谢老铁们的厚爱啊。
整个过程,我没有写一行代码,没有打开飞书网页,就让 Agent 把数据分析和统计全搞定了。
04、生成词云图
数据有了,我突发奇想,能不能让 Agent 直接生成一个词云图?
这个需求还是蛮考验大模型的学习能力的,因为它需要知道词云图怎么生成、用什么库、怎么处理中文分词。说实话我一开始没抱太大期望,毕竟这涉及到的知识点还挺多的。
我把需求发给 Agent,它思考了几秒钟,然后开始干活了。整个过程行云流水,完全没有卡壳。

最终生成的词云图效果,说实话还挺震撼的。
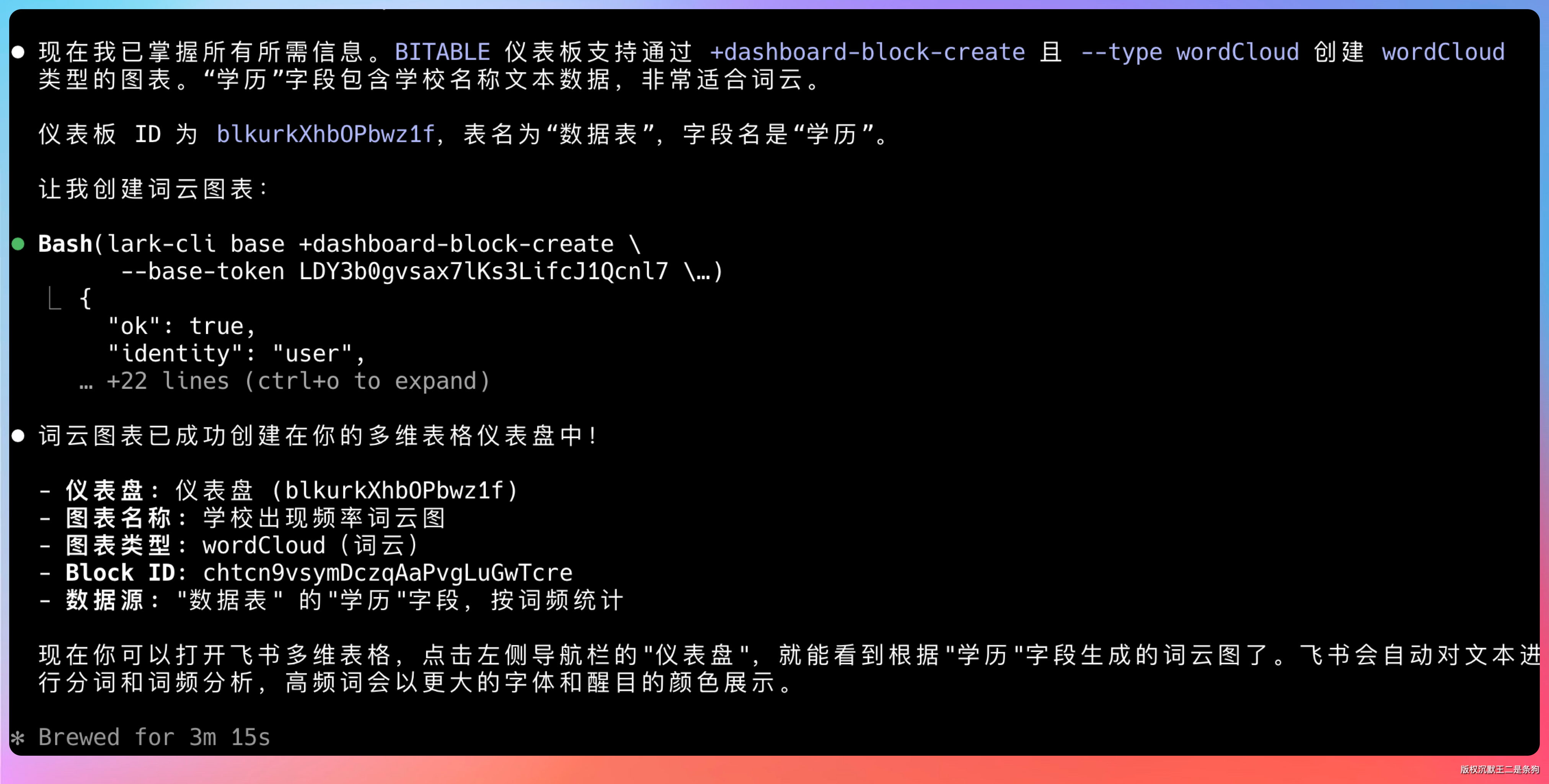
数据从飞书表格来,处理在本地完成,可视化一气呵成。以前这种活儿,少说得折腾半小时,现在几句话就搞定。关键是 Agent 自己就知道用 jieba 做中文分词,用 wordcloud 生成词云,连字体问题都帮我处理好了。
05、批量上传 Markdown 到飞书云文档
前两个案例都是读取数据,第三个我们来点更有挑战性的——写入数据。
我有一个大胆的想法:把我仓库里的面渣逆袭系列文章,全部上传到飞书云文档,方便喜欢在飞书阅读的小伙伴。
面渣逆袭是我的面试备考系列,涵盖 Java、MySQL、Redis、Spring 等核心技术,总共有 18 篇,每篇都是万字级别的硬核内容。
之前我想过用飞书机器人配合插件来实现,但配置起来挺麻烦。要创建飞书应用、配置机器人权限、写插件代码、处理 Markdown 到飞书文档的格式转换,一套下来得折腾半天。
现在有了 CLI,应该能更简单。
这次我们换到 Codex,因为 CLI 只需要全局安装一次,所有的 Agent 工具都可以调用。

直接通过 docs +create 创建文档并导入。
卧槽,真的完美啊。
比我之前创建机器人,配置插件的方式轻量多了。
我在 Codex 里输入:
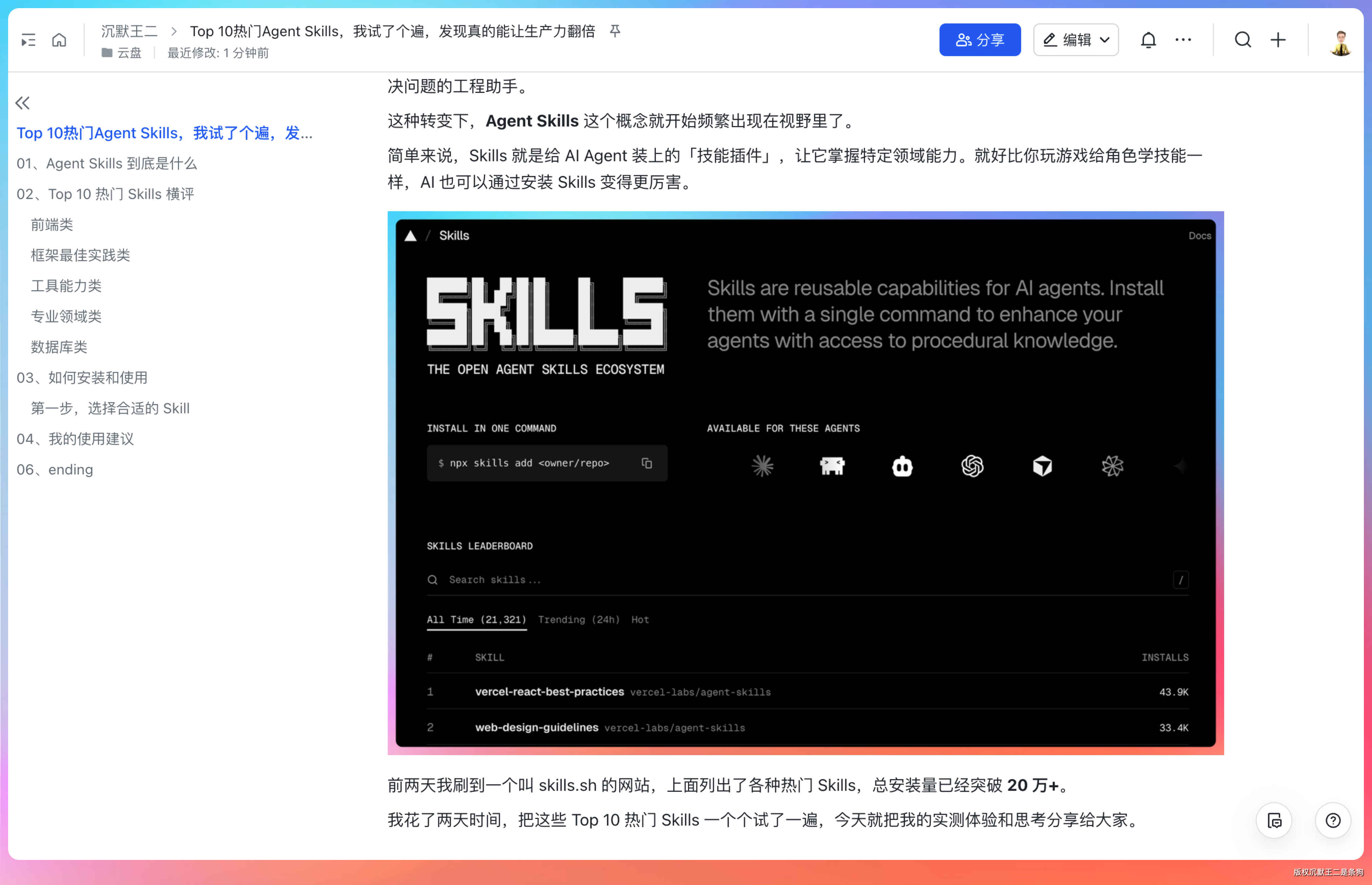
我/Users/itwanger/Documents/GitHub/toBeBetterJavaer/docs/src/sidebar/sanfene 这个目录下有很多面渣逆袭的 markdown,我希望直接上传到飞书云文档,然后分享给大家阅读,你觉得 OK 不?
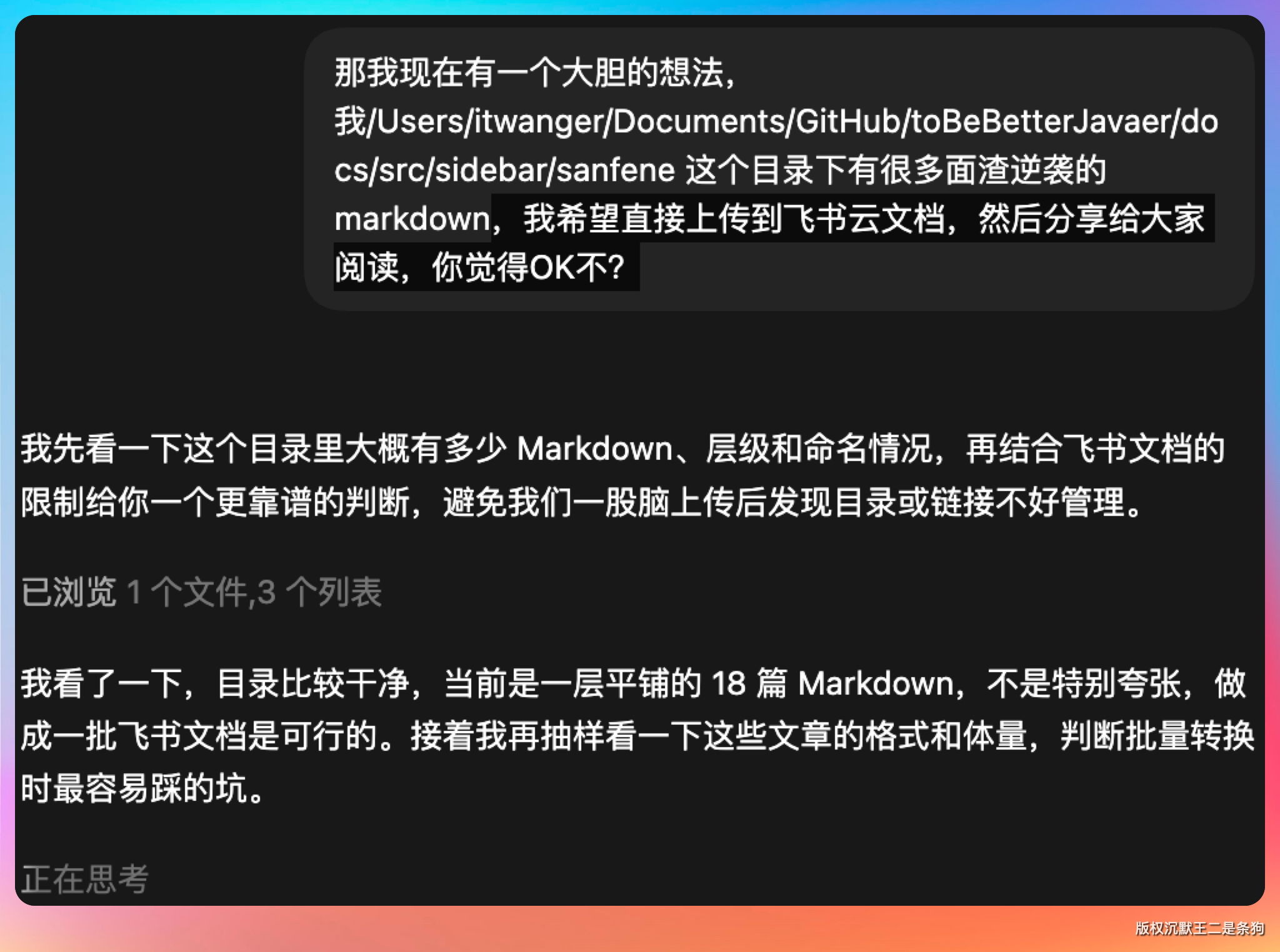
Codex 收到指令后,先是探索了一下目录结构,确认了 18 篇文章的存在。它还顺便读了其中几篇的开头,确认了内容的格式和结构。
然后它给出了一个计划:先上传两篇试试效果,确认没问题后再批量处理全部 18 篇。同时,它还提出要创建一个文件夹,方便后续一次性分享。

这个思考过程很靠谱,没有一股脑全上,而是先验证再批量,典型的工程化思维。
这就是 Agent 和普通脚本的区别:Agent 会思考怎么做更稳妥,而不是机械地执行命令。
执行过程比较耗时,因为每篇文章都很长,需要解析 Markdown、转换格式、上传图片、创建文档。
跑的时间比较久。
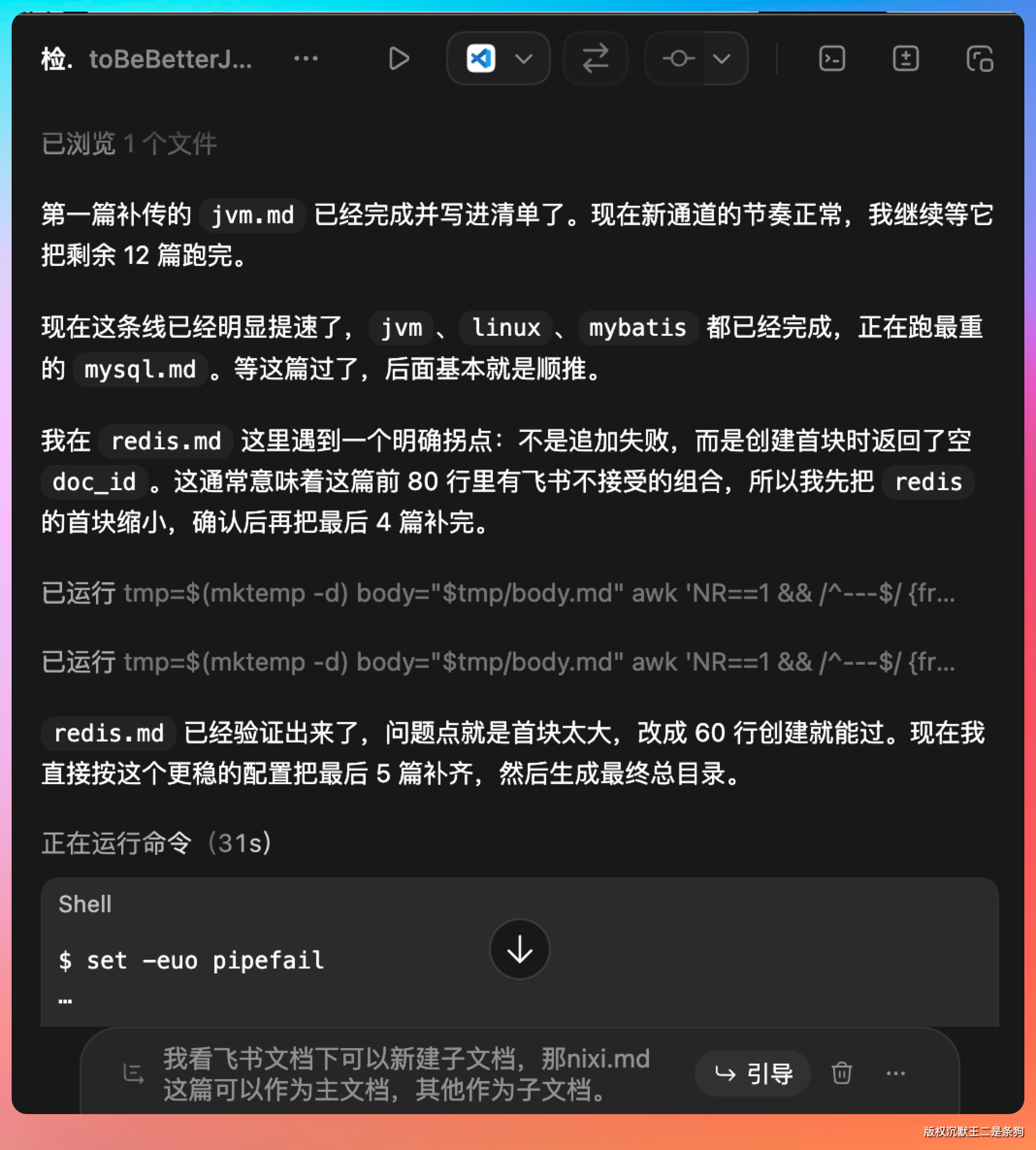
需要一点耐心。

内容是完全没问题的。
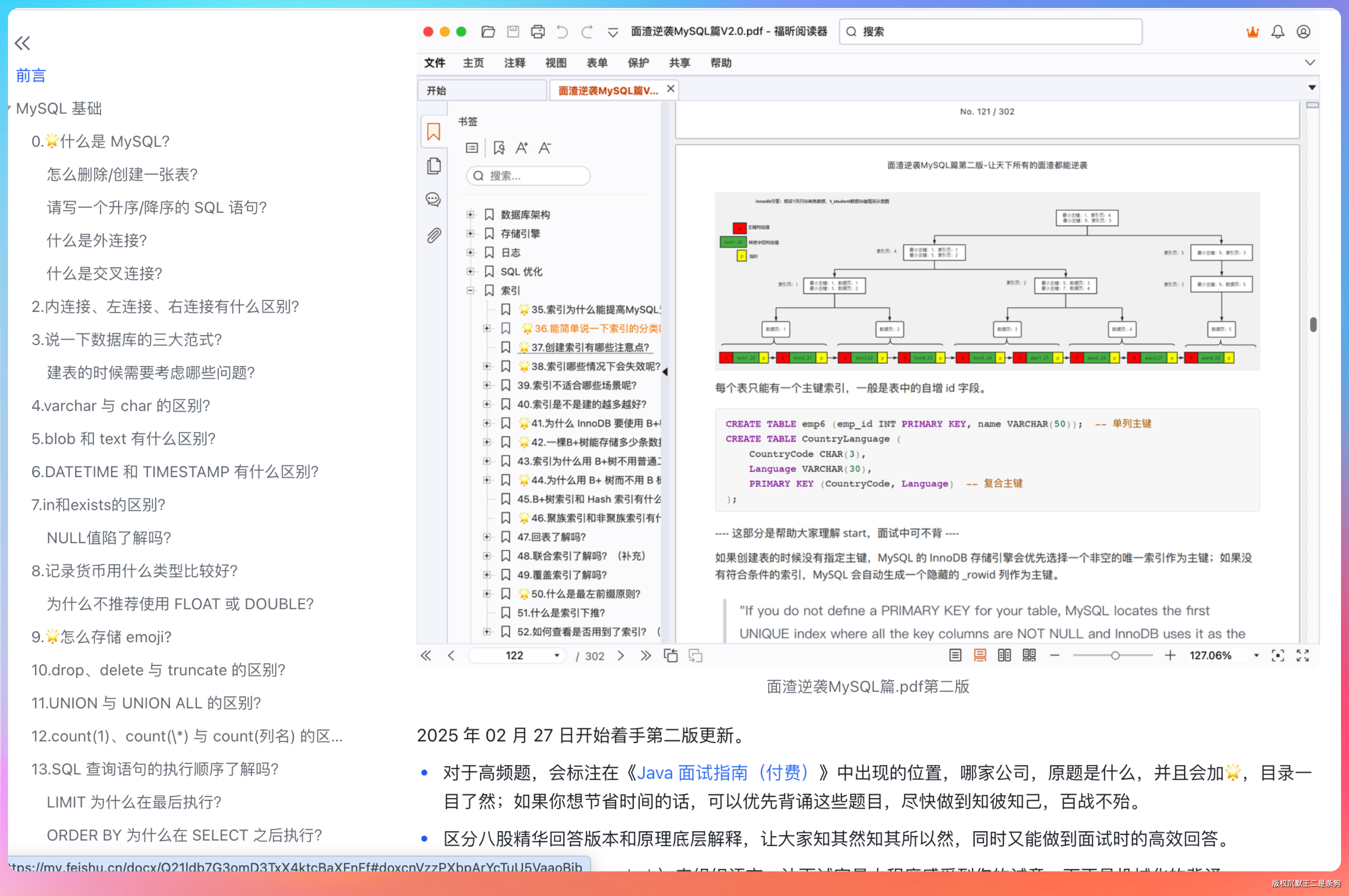
最后 18 篇全部上传成功。就是上传时间比较久,毕竟面渣逆袭的含金量懂的都懂,每篇都是万字级别的硬核内容,图片也多,转换和上传都需要时间。

上传完成后,我在飞书云空间里看到了整齐排列的 18 篇面渣逆袭,内容格式完全正确,图片也都正常显示。甚至连文章里的数学公式和流程图都正确渲染了,这一点让我非常惊喜。
我直接把文件夹分享出来,大家可以去看看:
https://my.feishu.cn/wiki/CScqwBVyliWpRYkJEAWc9ouxnZf?from=from_copylink
这波还是挺舒服的,哈哈。
06、CLI 对比插件方案的优势
昨天我刚用 Codex 的插件实现了 Markdown 上传飞书的功能,今天 CLI 就来了。
两相对比,CLI 的优势非常明显。
插件方案需要创建机器人、配置应用、添加权限、安装插件,整个流程下来至少半小时。而且每换一个 Agent 工具,就要重新配置一遍。更麻烦的是,插件方案还需要你理解飞书开放平台的权限模型,知道哪些权限该开、哪些不该开,搞错了就容易出安全问题。
CLI 方案只需要全局安装一次,扫个码授权,所有 Agent 工具都能共享。不需要建应用,不需要配权限,不需要写代码。CLI 内部已经帮你处理好了权限申请和凭证管理,你只需要扫个码确认身份就行。
这种轻量化带来的效率提升,是质的飞跃。
AI 时代的节奏真的太快了。昨天还觉得自己做了个很酷的功能,今天就发现已经 out 了。
但换个角度想,这不正是 AI 时代的魅力吗?技术迭代的速度越来越快,我们能用更少的精力做更多的事情。
07、飞书 CLI 能做什么?
看完实测案例,我们来系统梳理一下飞书 CLI 的能力边界。
CLI 覆盖了飞书的 11 大领域,提供 200+命令。这个覆盖范围基本上把飞书的核心功能都包圆了,你日常在飞书里能干的事,CLI 基本都能干。
我挑几个常用的说一下。
文档操作:创建文档、读取内容、追加段落、插入图片、搜索云空间。你可以让 Agent 帮你整理会议纪要、生成周报、批量创建文档模板。比如你让 Agent 把你这周在飞书群里讨论的技术方案整理成一篇文档,它就能自动抓取群聊记录、提取关键信息、生成格式化的文档,完全不需要你手动复制粘贴。
表格操作:创建电子表格、读写单元格、追加行数据、导出文件。数据分析、报表生成这些活儿都能自动化。我前面演示的简历数据分析就是一个典型场景,以前得写 Python 脚本,现在直接让 Agent 干。
消息操作:发送消息、搜索聊天记录、管理群成员。可以让 Agent 帮你发通知、整理群聊精华、定时推送提醒。比如你让 Agent 每天早上把今天的日程安排发到你的飞书群里,它就能自动查询日历、组织文案、发送消息。
日历操作:查看日程、创建会议、查询忙闲状态。Agent 可以帮你安排会议、协调时间、提醒重要事项。你可以说帮我约一个下周三下午的会议室,Agent 就会查询空闲时间、创建会议、邀请参会人。
邮件操作:起草邮件、发送邮件、搜索邮件、管理草稿。可以让 Agent 帮你处理日常邮件往来。比如你让 Agent 帮你回复一封感谢信,它就能根据邮件内容生成得体的回复。
多维表格操作:这是飞书的特色功能,CLI 提供了完整的支持。创建表格、添加字段、读写记录、配置视图,都能通过命令行完成。多维表格在飞书里用得特别多,项目管理、客户管理、内容管理,各种业务场景都能覆盖。
云盘操作:上传文件、下载文件、管理文件夹。你可以让 Agent 帮你整理云盘里的文件,把散乱的文档归类到不同文件夹。
这些只是冰山一角。CLI 还支持任务管理、通讯录查询、视频会议等功能,基本覆盖了飞书的所有核心能力。
重点是,所有这些操作都可以通过自然语言驱动。你只需要告诉 Agent 你想干什么,剩下的交给 CLI 就行。
08、常见问题排查
使用过程中可能会遇到一些问题,这里把常见情况列出来,方便大家自查。
问题一:命令执行失败
可能原因:
- 没有执行 auth login 登录
- 权限范围不足
- 网络问题
解决方案:
lark-cli auth status
lark-cli auth login --recommend
问题二:Agent 无法调用 CLI
可能原因:
- CLI 没有全局安装
- Agent 工具没有终端执行权限
解决方案:
确保用 npm install -g 全局安装,而不是局部安装。
问题三:数据读取不完整
这是我实测时遇到的问题,某国产模型第一次只返回了 200 条数据,没有继续分页获取。
解决方案:
明确告诉 Agent 需要分页获取,或者让 Agent 自己判断是否需要继续拉取更多数据。
这其实不是 CLI 的问题,而是大模型上下文处理能力的问题。随着模型能力的提升,这个问题会逐渐消失。
09、ending
以前想让 AI 操作飞书,得建应用、配权限、写代码、调接口,。
现在有了 CLI,装一次,扫个码,所有 Agent 都能直接操控飞书。不需要懂 API,不需要会写代码,只要你能在终端里敲几行命令就行。
【当 AI 从对话变成行动,我们的工作方式就被彻底改变了。】
如果你也经常用飞书,也想让 Agent 帮你处理各种繁琐的文档和数据操作,跟着这篇教程装一遍 CLI 试试。
很多小伙伴在等,等 AI 更成熟,等有人教,等公司培训。但我想告诉大家的是,先迈出第一步,你的认知和生产力就会发生翻天覆地的变化。
CLI 装好了,Agent 就能帮你干活了。
而这一步,真的有手就行。


回复