
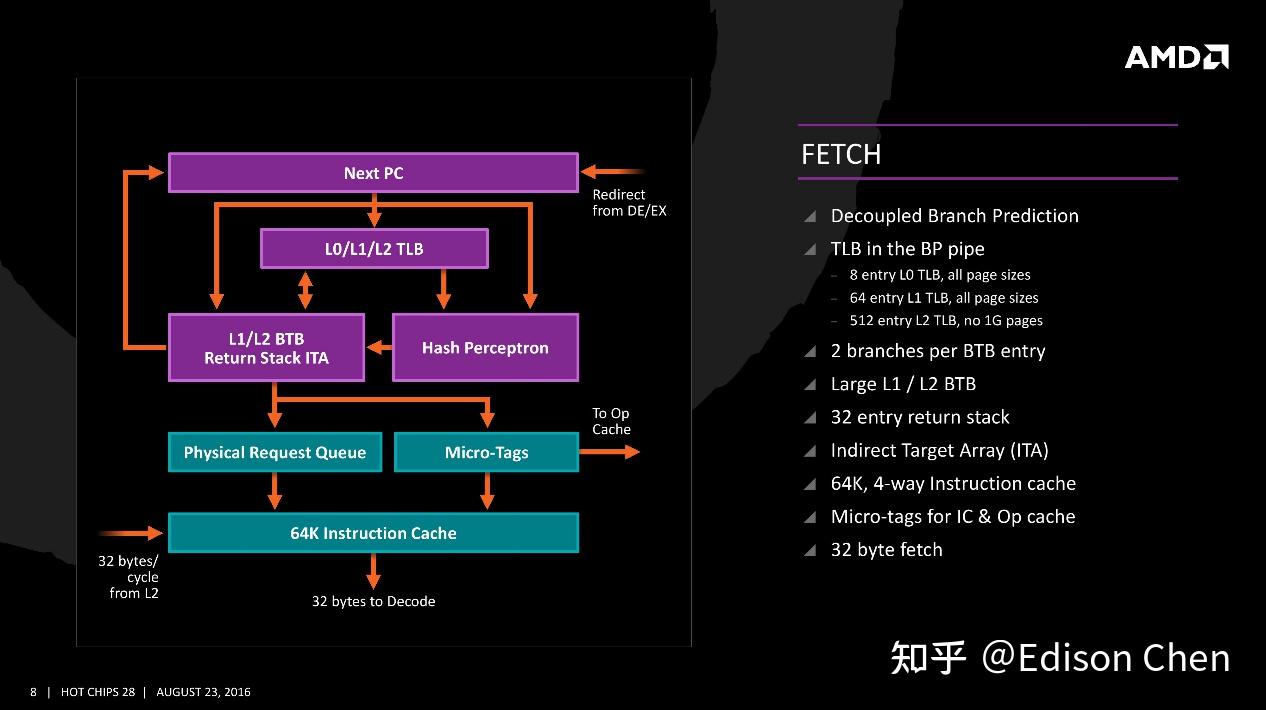
终于到了领先时刻?
AMD 在推出追求平衡之道的 Zen 后,虽然一举扭转了推土机时代的巨大性能落差,但是和 Intel 之间差距仍然存在不容忽视的差距,直到 Zen3 问世,AMD 有了几个月的性能领先时间窗口,比较遗憾的此时正值矿潮最疯狂的时候,AMD 的第一波 Zen3 都缺乏核显,使得它无法在市场上和具备核显的 Intel CPU 竞争,桌面份额并未获得增长甚至有倒退的迹象。
到了 Zen4 后,AMD 开始引入了核显,但是此时矿潮已经退散,而 DDR5 内存价格还比较高昂,在 DIY 市场里 AMD Zen 4 平台在一段时间里都不怎么受待见,倒是在价格不是那么敏感的笔记本、服务器市场上 AMD 接连拿下不少大单,在用户方面也获得了很好的口碑。大家对 AMD 的认受度确立后,最难受的自然是原本占据笔记本、服务器最大份额的 Intel,现在 Intel 在笔记本和服务器市场正面临前所未有的压力。
从产品竞争力角度看,AMD 在 CPU 市场里的目前最大短板就是桌面部分,目前 Intel 采用了混合架构(例如 14900K/13900K 采用了 8 大核 + 16 小核),在吞吐力以及 CPU 频率上占优。
但是 Intel 第十三、十四代酷睿存在一个不容忽视的缺点,那就是功耗极高,以至于其自动产品阈值设定被新固件负优化,大家都惊呼更新 BIOS 后他们的期间十三代、十四代酷睿性能明显下降。
你要是说出厂即燃烬的话 Intel 肯定不接受,毕竟它可以把责任推给主板厂商:这是主板厂商不遵循要求导致的。只是对于消费者来说,这就是有点难受了,因为在经历了半年的不稳定后,现在直接削掉了性能当解决方案(14900K 相当于削成了”14800K-”,当然 14800K 并不存在),这中间的损失似乎没法索赔。
随着 DDR5 内存价格逐渐平民化,AMD 在桌面的份额开始有了起色,按照市场调查机构 Mercury Research 的最新报告,AMD 今年第一季的桌面份额达到了 23.9% 的历史新高,是 2017 年 Zen 问世时的四倍,未来 AMD 能否再下一城的关键就是日前推出的 Zen 5 微架构系列处理器。
x86 现在可谓是精彩纷呈,不过 x86 之外的世界也很有趣,按照路透社的独家报道,ARM 的 CEO 表示 ARM 处理器在未来 5 年里将会拿下 Windows PC 市场 50% 的份额。大家可能觉得这是玩笑,不过这次可能真的有点不一样,因为传闻中 NVIDIA 也在从事 ARM 桌面 CPU 的开发,这意味着以往 ARM Win PC 的最大问题——无法胜任重要应用的情况将会有巨大变化,NVIDIA 加入 ARM PC 后,显卡驱动和应用很可能会快速跟进,游戏、工作站应用等都将成为可能。
所以,现在是到了 x86 阵营认真对待外来挑战的时候了,Zen 5 这份答卷 AMD 做得如何,成为当下最强架构?
Zen 5 基本概况
AMD 在 2017 年正式推出了基于 Zen 微架构的 Ryzen 消费端处理器,对于这个微架构的名称——Zen 所包含的意义,AMD 的说法是体现了:IPC、频率、功耗以及面积四者的平衡,其实这四者不仅仅是 Zen 也是所有处理器产品的四根最重要琴弦,只有在合理的范围内拨动才能弹出动人的曲子。
Zen5最初是在大约 2019 年 10 月份左右在 Eypc Horizon Executive Summit 研讨会上被 AMD 的 Mark Papermaster证实正处于设计阶段,之后开始出现 Zen5 由 Zen2 首席架构师 David Suggs 领衔的说法(上面是旧的截图,新的简介已经更改为 Chief architect for the Zen2 microprocessor core and a subsequent high-performance core)。
但是到 2022 年,David Suggs 就离开了 AMD,至今一直都是自雇人士。现在 Zen5 架构的演讲文稿已经改由当年(2011 年)Bobcat(支持乱序执行,用于抗衡 Intel Atom 等低功耗处理器,在推土机年代是 AMD 产品线中少有的亮点)架构师 Brad Cohen 和首代 Zen 首席架构师 Mike Clark 接手。
下图是目前 Zen 核心团队成员最近的一次聚会(讨论未来 Zen 架构构想),其中前排墨绿色上衣的就是 Mike Clark。

Zen5 是 Zen 微架构的第五代,产品实现采用 Chiplet 小芯组合,分为 CCD 和 IOD 两种小芯片,CCD 相当于传统意义上的 CPU,IOD 则是系统总线+内存控制器+周边互连,Zen4 后 IOD 还引入了 RDNA2 核显。
在 Zen1/2 时代,每个 CCD 里有两个 CCX,每个 CCX 里有四个 CPU 内核共享一块独立的 L3 Cache,。
从 Zen3 开始,CCX 改为 8 个 Zen3内核共享一块 L3 Cache(这也意味着 8 个内核之间的数据一致性性能更理想)。
Zen5 依然采用了和 Zen3/Zen4 一样的 CCX 规模:8 个 Zen5 内核共享一块 L3 Cache(容量为 32 MiB)。
AMD 将基于 Zen 微架构实现的桌面、移动产品品牌命名为 Ryzen,包含有两个 CCD 的属于 Ryzen x9xx,往下的则只有一个 CCD。
Zen5 的桌面端产品线(代号 Granite Ridge)属于 Ryzen 9000 系列,上一代或者说 Zen4 是 Ryzen 7000 系列,今天上市的最顶级型号为 Ryzen 9700X,包含有一个 Zen5 CCD,里面有一个 CCX,8 个内核共享 32 MiB L3 Cache。

根据产品定位的不同,Zen5 CCD 采用了不同的制程生产,面向桌面的版本(代号:Eldora)采用的是台积电 N4X 制程。
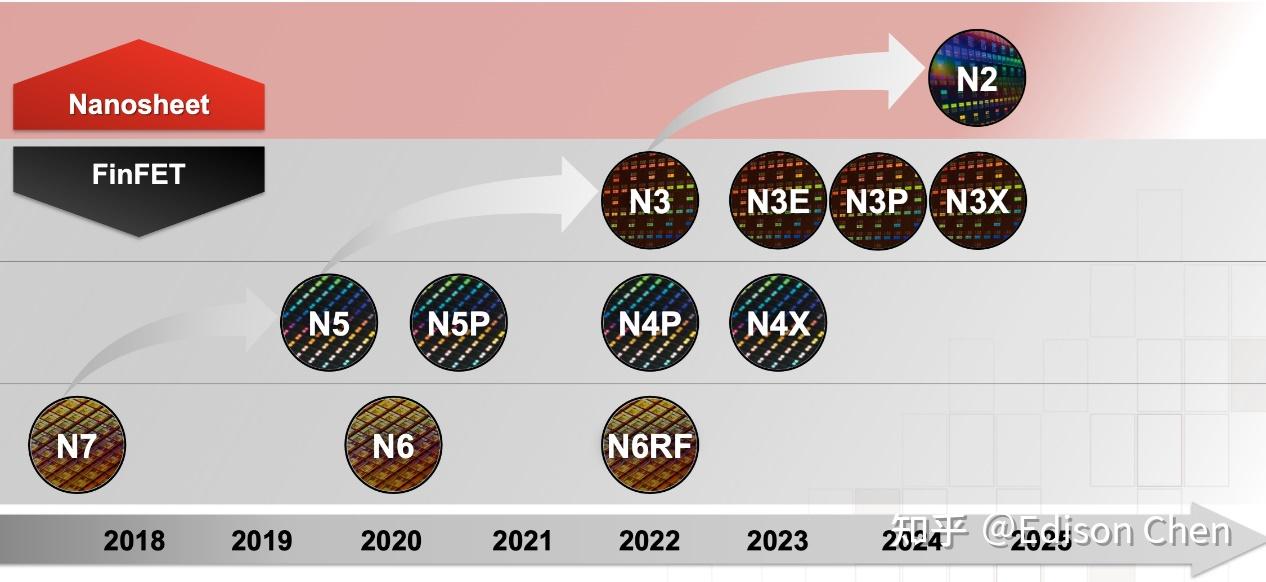
按照台积电的新闻稿,N4X 是面向高性能计算的制程,它的性能比 N5(Zen4 采用的制程)提升超过 15%,在 1.2 伏特电压下也比同等节点的 N4P 制程快 4%,并且在超过 1.2 伏特电压时依然能维持性能提升。
AMD 计划稍后推出 3nm 版本的 Zen5,但是具体时间并未透露,我估计要明年才能看到。
和 Zen4c 类似的是,AMD 也计划推出面向能耗敏感的 Zen5c 变种。Zen4c 除了 Cache 外,和 Zen4 是完全一样的,目前已经在笔记本等领域得到应用,对于 Zen5c 或者未来的 ZenXc 变种是否在桌面推出,AMD Mike Clark 认为 这是很有可能的,并且认为未来操作系统在紧凑内核的调度方面会变得更成熟。
内核调度的确是一个不容忽视的问题。
就拿 Zen4 来说,双 CCD 版本的 Ryzen 7 其中一个 CCD 的频率要比另一个低,但是在 Linux 下,这两个 CCD 内核的优先度都是一样的,在 Linux 调度器面前,高频 CCD 和低频 CCD 都是一视同仁,都是随手一甩扔给任意一个闲置内核。
这个问题在 Linux Kernel 6.11 下依然存在。
当然,根据实践,目前是有一些简单的诀窍实现双 Zen4/Zen5 实现更好的自动内核调度,只是这种方法会让 Intel 的 Thread Director 冲突.也就是启用了 Zen4/Zen5 的性能优先内核调度的话,同样的设置会让 Intel Thread Director 失效,拥有 P-core 和 E-core 的 Intel 处理器在多线程时的性能会下降 8% 左右。当然,这样的互斥问题只有像我这样拿着同一个 Linux 操作系统硬盘在不同平台上跑测试才会遇到,普通用户应该极少遇到。
Zen5 的微架构在多方面进行了更新,例如流水线前端的分支预测器和指令解码器、指令窗口资源、执行端口和单元、向量数据路径、L1 数据高速缓存都有一定的改进,但是在频率方面并没有做更大的提升,基本上维持在上代 5.5 GHz 级别。
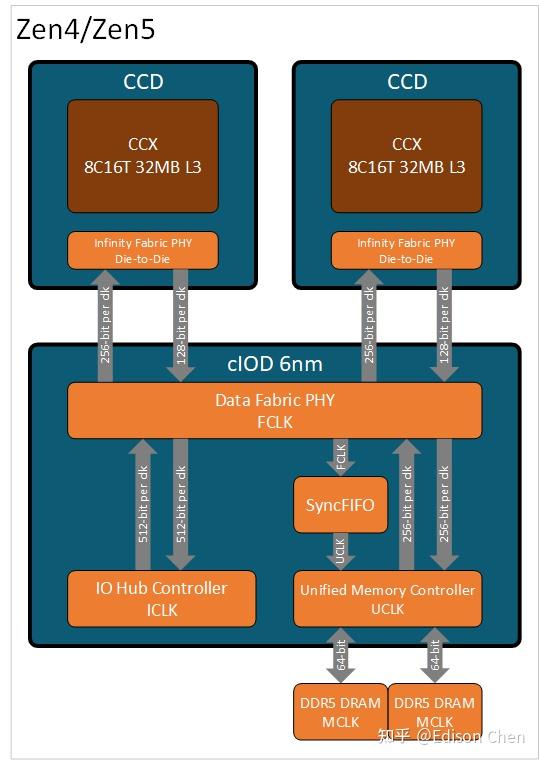
最原封不动的当属 IOD,依然是 Zen4 时候的那个 6nm IOD.
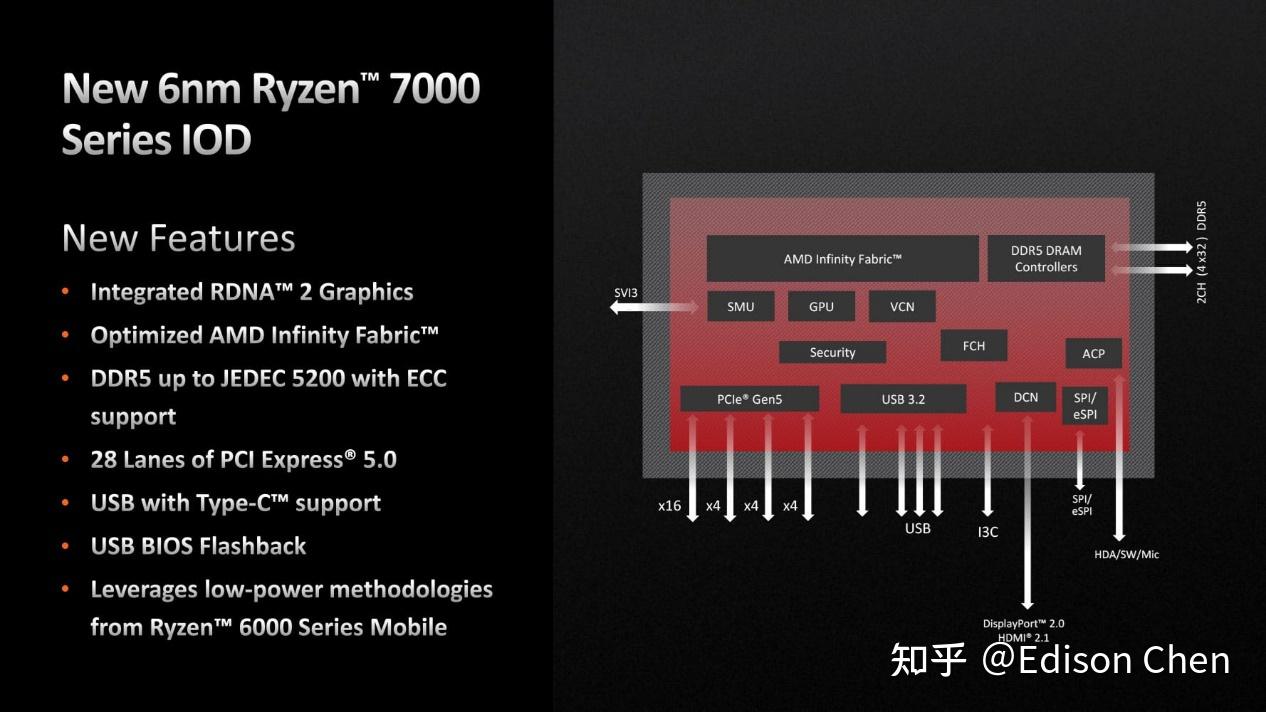

这意味着 Granite Ridge 的核显、PCIE 5.0、DDR5 内存等能力和 Zen4 是别无二致的。考虑到桌面处理器目前对周边能力的需求以及竞争对手的产品状况,继续沿用 6nm IOD 问题并不大,是一个比较明智的选择。
当然,我和大家也都希望 AMD 能够提供新的 IOD,因为更先进制程在功耗方面总是有好处的。
Zen4 在频率、整数性能方面较 Zen3 取得不少提升,但是在面对 Intel Golden Cove(Alder Lake 和 Raptor Lake 的 P-Core 微架构)时浮点性能是要差不少的。
以 SPEC CPU2017 的单任务程浮点类测试 fprate 1-copy 为例,在 GCC 14.1(march=native 或znver4、-Ofast)为编译器时,Ryzen 9 7950X 的得分为 15.5,而它的对手 Core i9 14900K 是 19.2,前者是后者的 81% 不到。这是单线程的情况,Intel 现在采用了混合架构,拖着一大堆 E-Core,所以在强调吞吐能力的浮点应用中,AMD Zen4 会比较吃亏。
相较而言,在任务整数类测试 intrate 中,Ryzen 9 7950X 是 11.5,Core i9 14900K 是 12.3,前者约是后者的 93.5%,7950X 的 IPC(每周期指令)值为 2.14,Core i9 14900K 是 2.10。
大家常见的桌面应用(如游戏、办公软件等)在性能需求上还是更偏整数(不考虑分支指令和访存指令的话,整数浮点指令数比例可能是 9:1),但是现在超算服务器和工作站已然成为 AMD CPU 业务最重要的增长极,这两个现金奶牛市场对浮点性能需求极高,所以 Zen5 的重要改进点落在了浮点性能上。
提升浮点性能的办法有多种,例如增加浮点单元、拓展 SIMD 宽度、频率、内核数等,但是随之而来的将是更大的内存带宽压力以及功耗。
AMD Zen4 给出的答案是:
- 更强的每周期指令递交能力;
- 更宽的指令派发、执行设计;
- Cache 数据带宽倍增;
- 新增 AI 加速能力。
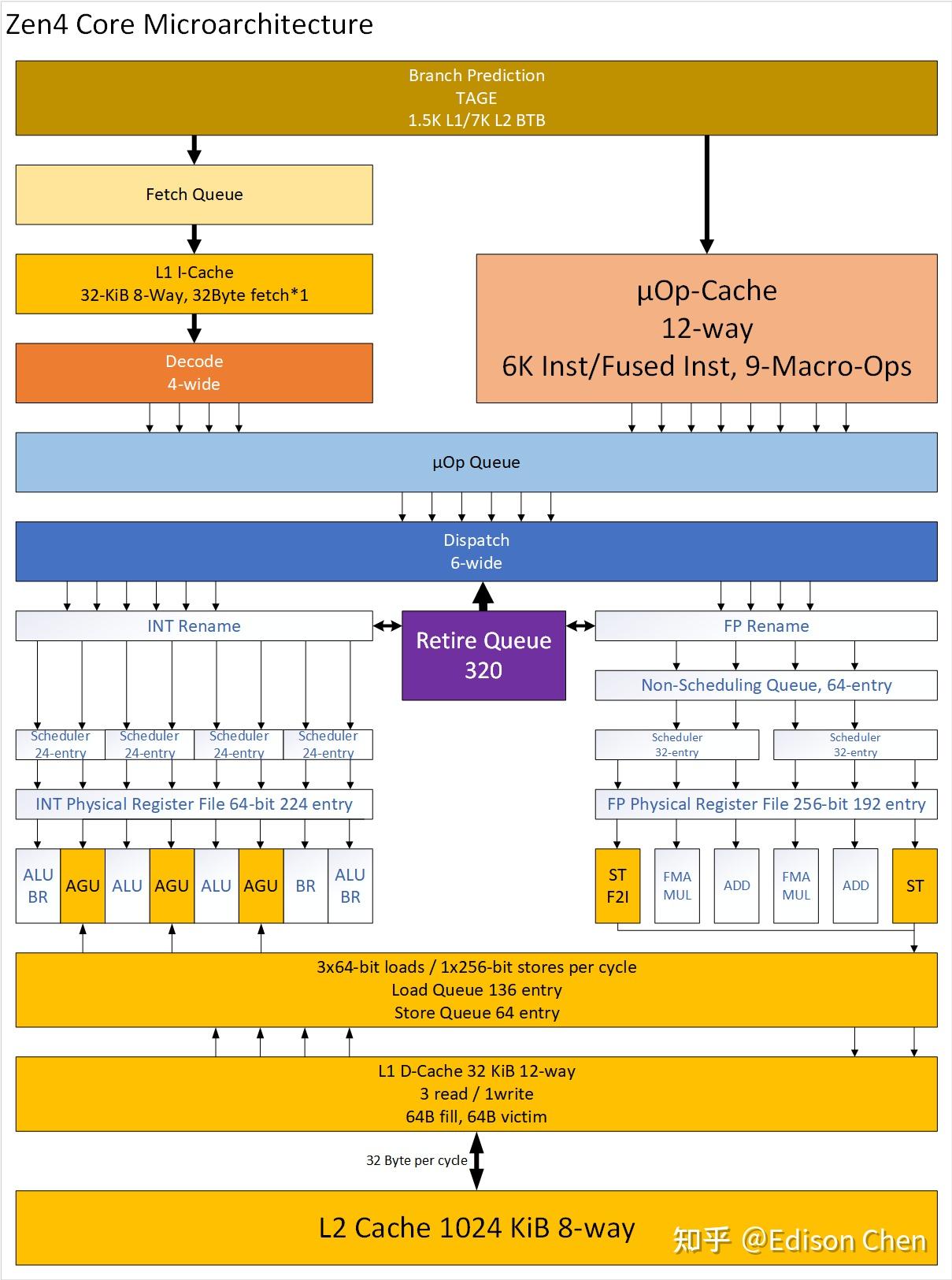
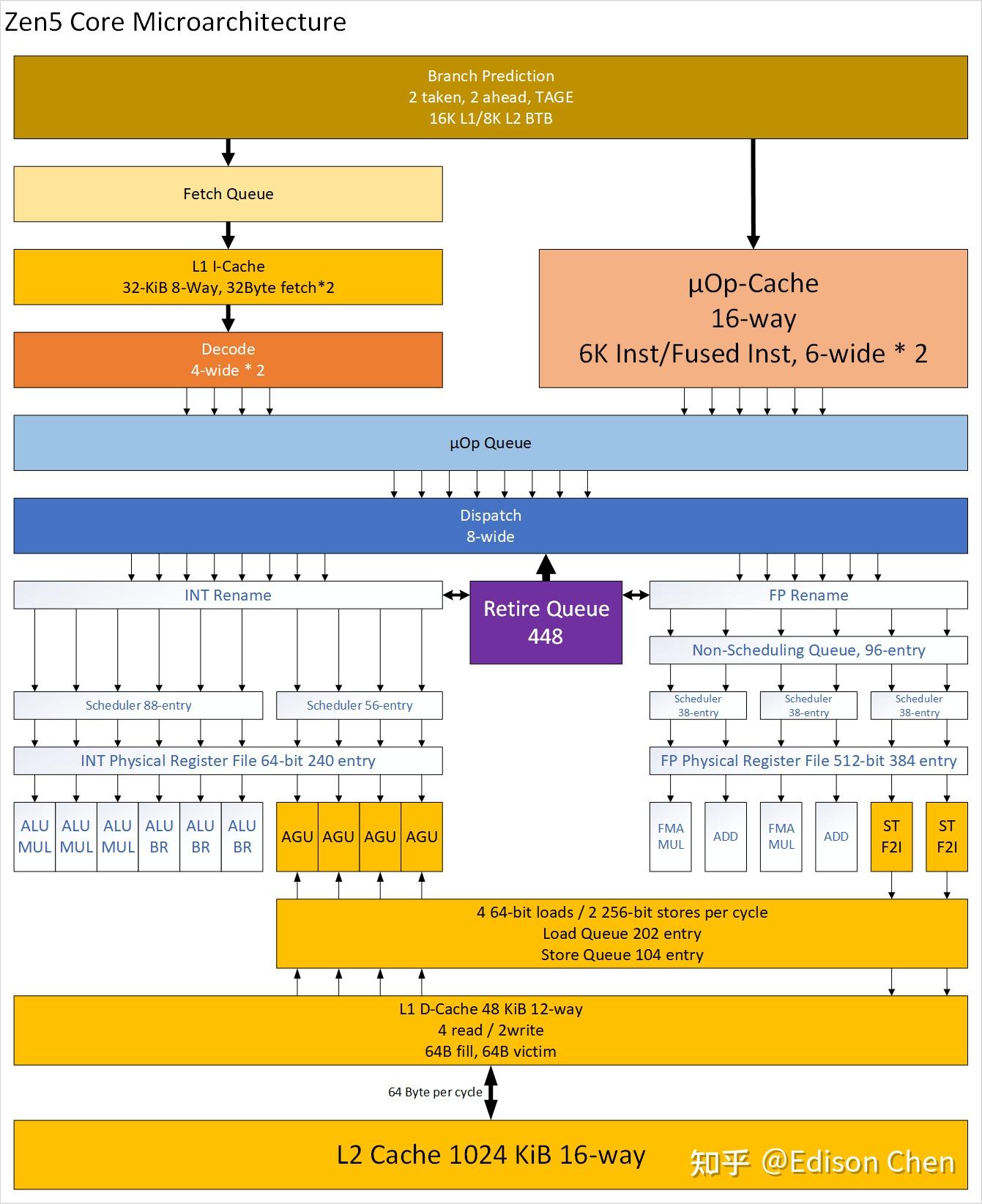
上面这两张图分别是 Zen4 和 Zen5 的架构图,基本按照 AMD 提供的资料绘制,从整体上来看,Zen5 和 Zen4 相比有很大变化,无论是前端、后端。
针对其中的一些微架构细节我做了一些简单的测试:
底层测试——ROB、推测寄存器堆、加法调度器、L/S 单元资源
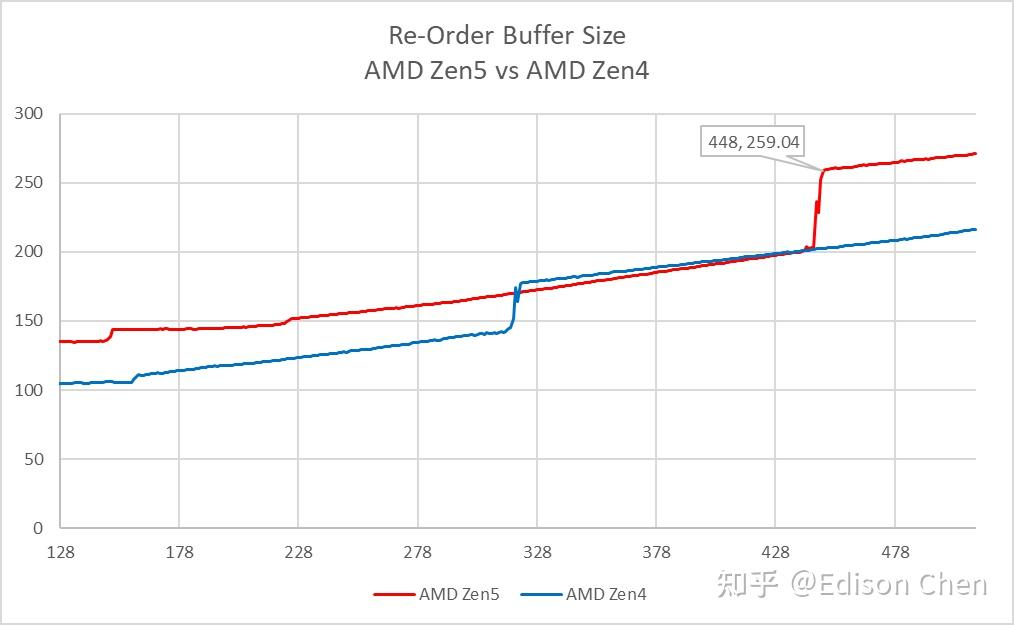
ROB 实测值是 448,和AMD 提供的信息一致;
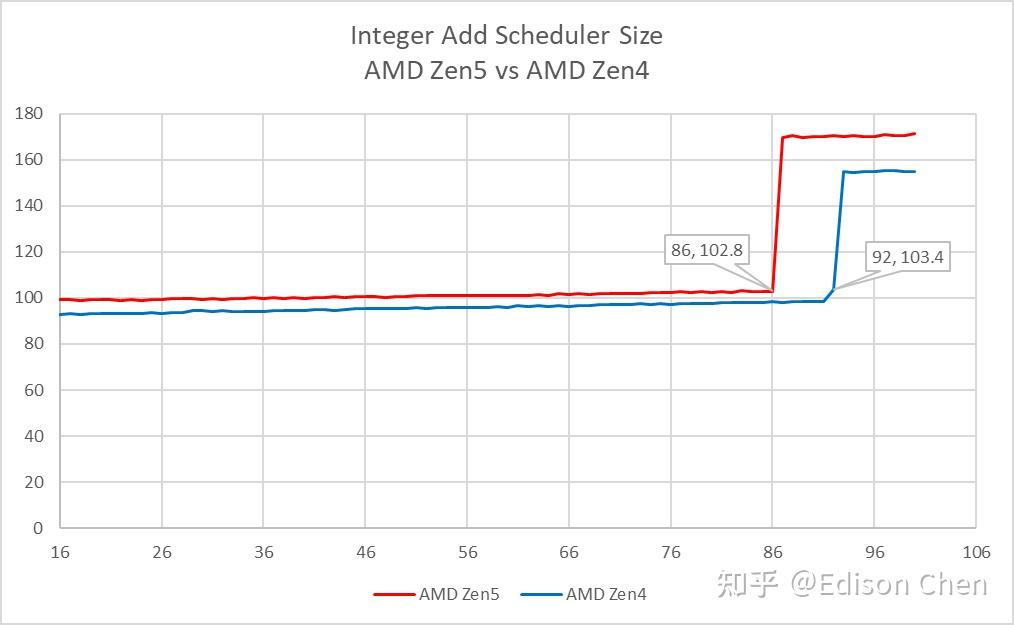
整数调度器方面,Zen5 实测值为 86,略低于 AMD 提供的 88,差别不大,这可能是因为一些额外的开销或者架构状态占用。
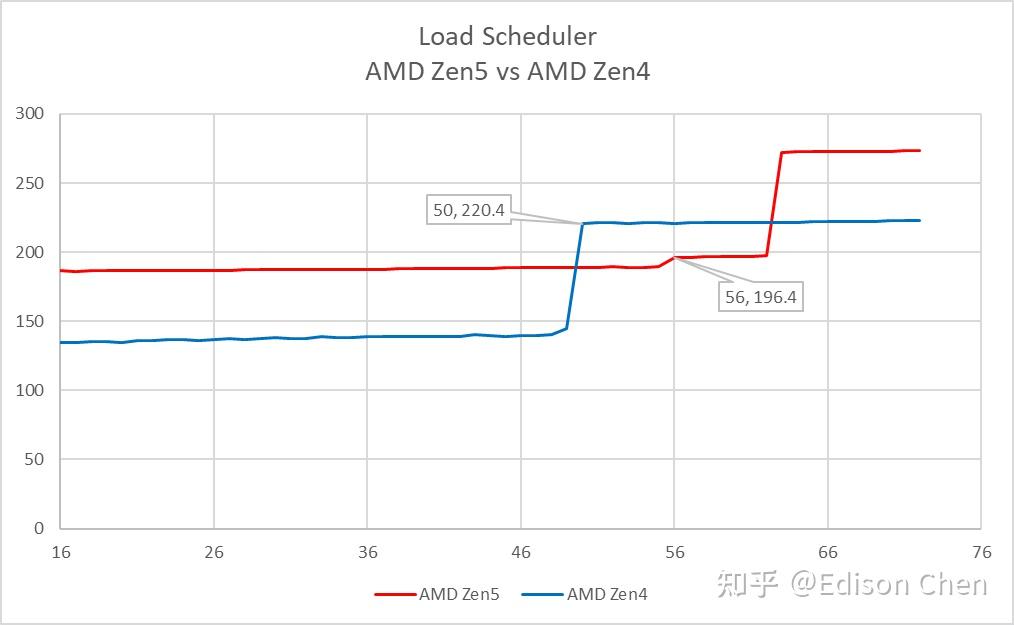
AGU Scheduler 实测值为 56,和 AMD 提供的信息一致。
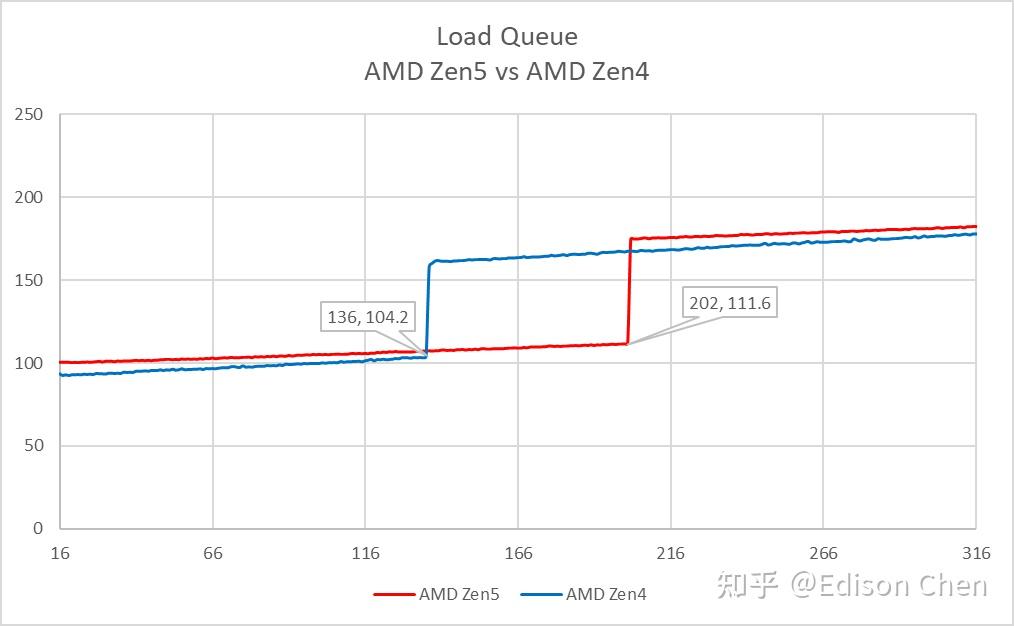
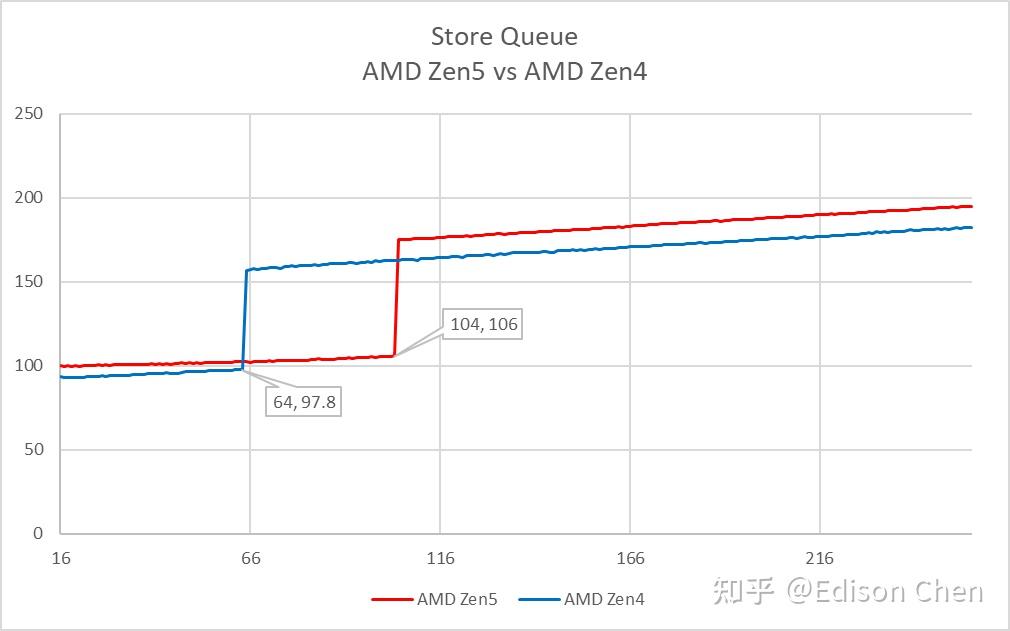
LSQ 实测方面,Load Queue 为 202 项,Store Queue 为 104,AMD 并未提供相关细节。
和 Zen4 相比,Zen5 的 ROB “放弃”了 NOP 合并的功能,这使得 Zen5 在 ROB 和解码测试中跑 NOP 指令吞吐有时候看上去不如 Zen4。
底层测试——各种指令模板解码能力
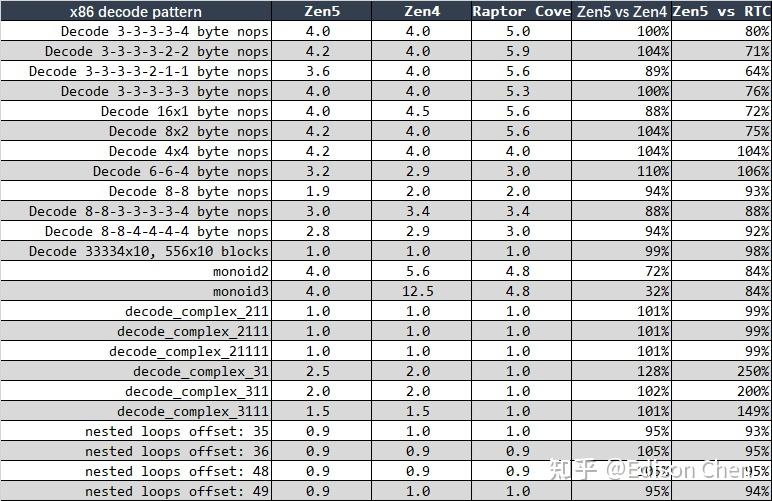
上表中的解码能力测试是当年 Travis 为了测试 Alexander Monakov 提出的 SKL 具备每周期 5 条 16 字节指令解码能力,但却因为重命名工位限制为每周期 4 指令的想法而设计的,原结果是 CPI(每指令周期数),这里我已经将测试结果转换为 IPC。从上面这个表格的测试结果看,Zen4 在 monoid3 的时候 IPC 可以达到 3.125 倍于 Zen5,但是复杂指令 3-1-1 模板里,Zen5 是 Zen4 的 1.25 倍。Raptor Cove 在较短的 x86 指令解码上更有优势,而在复杂指令模板下有时候只有 Zen5 的 40% 到 50%。
底层测试——指令窗口资源对比
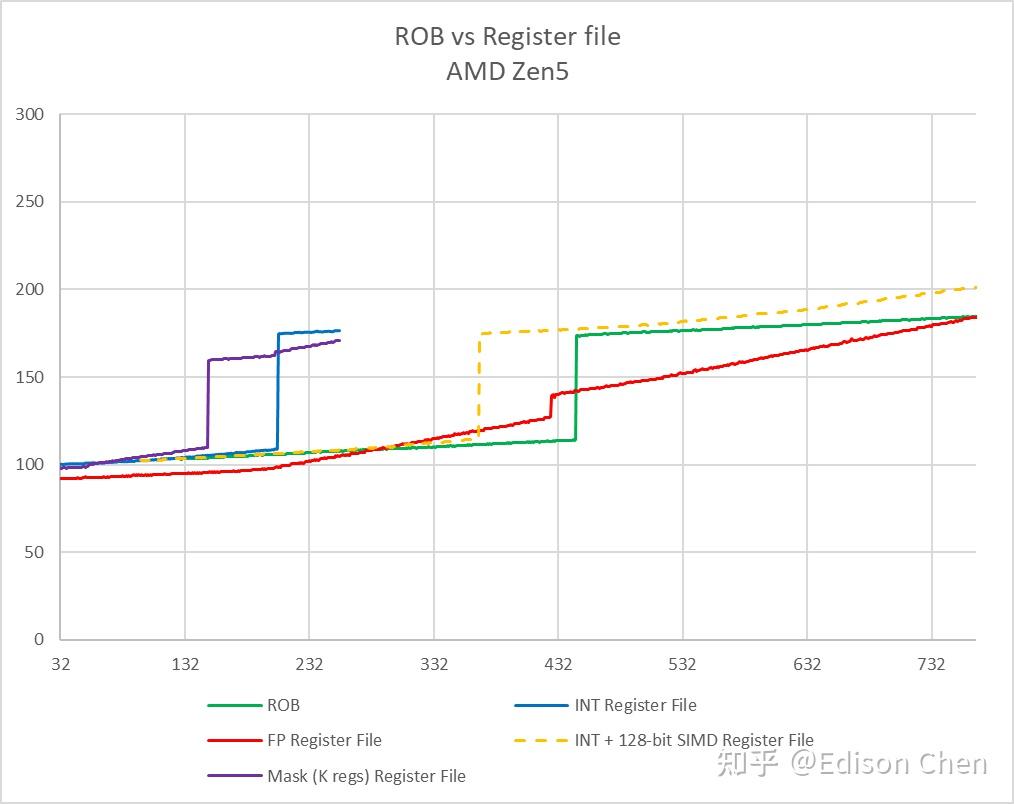
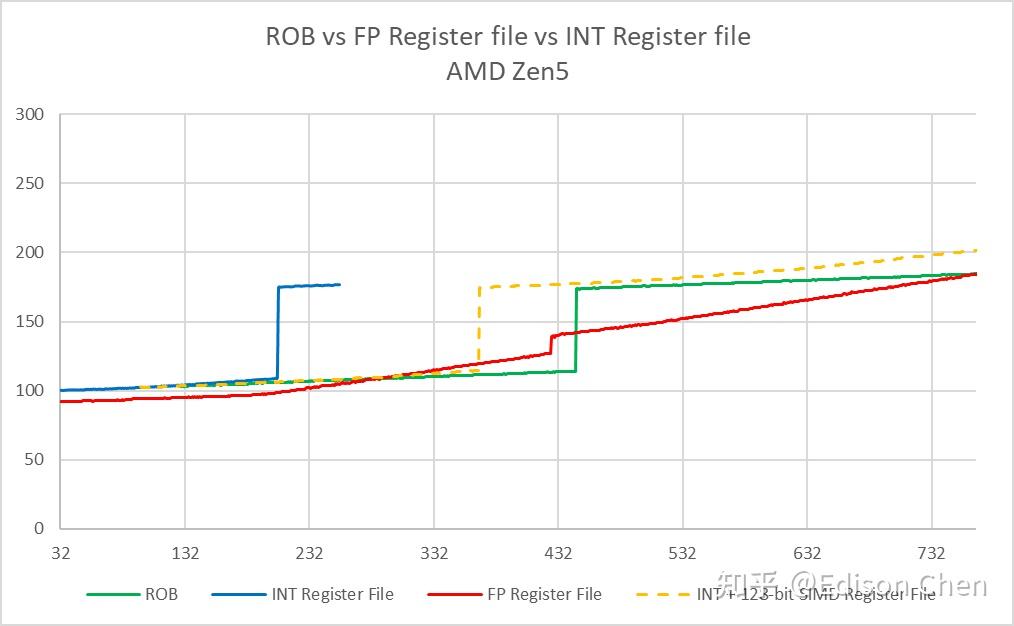
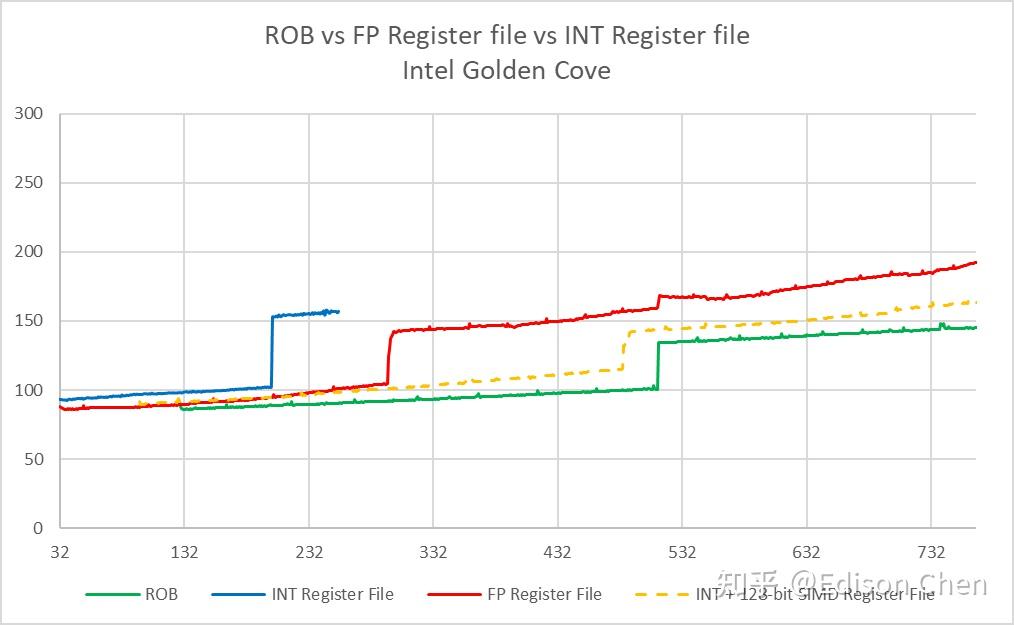
(请忽略图中曲线的起始点和终止点差别,这只是因为出于测试耗时考虑的参数设置问题而已,关注发生明显跳变的位置就行)。
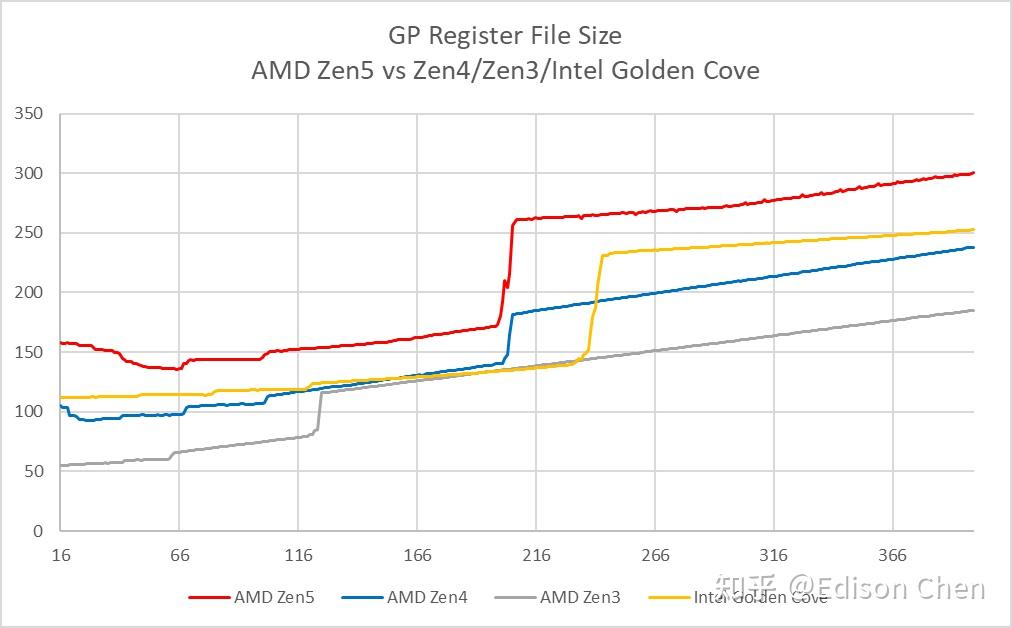
对于乱序执行处理器来说,寄存器重命名技术可以在维持指令集寄存器约束的情况下,实现更高的指令并行能力,寄存器堆数量越大,可以并行跑的指令数理论上就越多。
从程序员角度观察,Intel Golden Cove 和 Zen5 的整数寄存器堆大小比较接近,Zen5 的浮点/向量寄存器堆要大不少,但是在整数指令和向量指令混合的时候,Golden Cove 的规模更有优势。
Zen4 在这方面与另外两者相比要黯淡不少。
在乱序执行资源方面,Zen5 的浮点和向量寄存器堆有巨幅的增长,而整数寄存器堆实测基本一样(本文所有测试数据都是关闭超线程下录得的,超线程数据还没整理好)。
底层测试——L1D Cache-L2 Cache 总线带宽
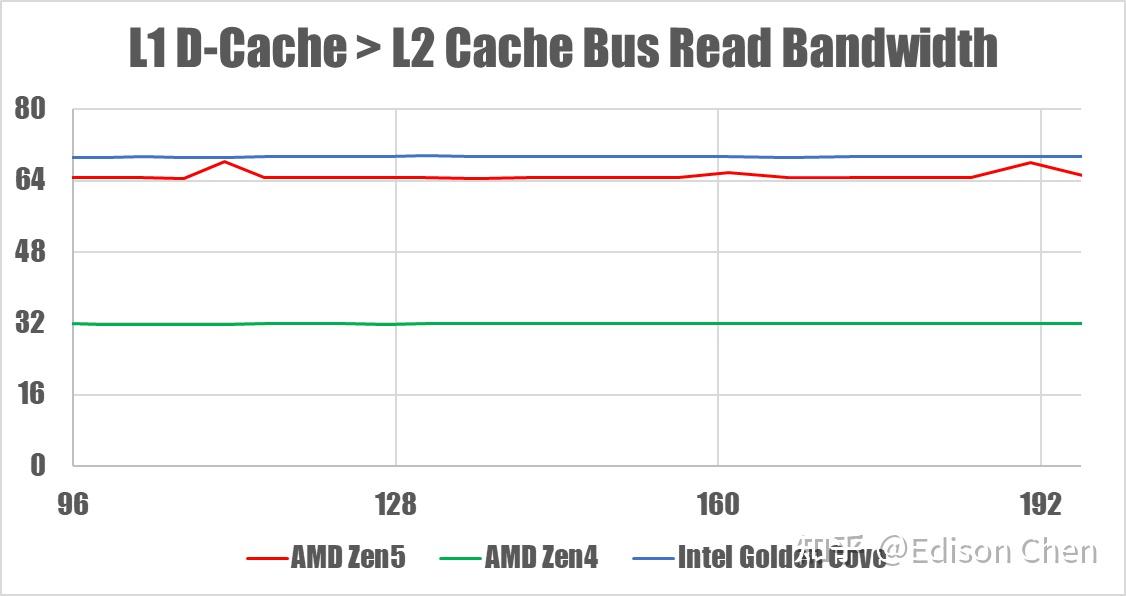
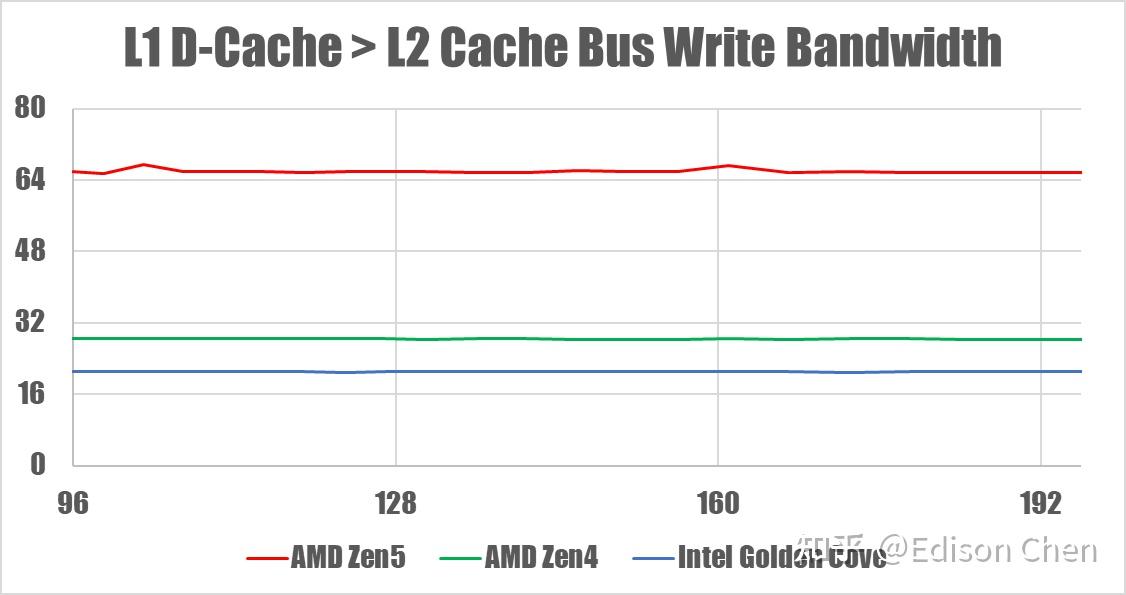
在 L1-L2 总线方面,Zen5 都提供了 512-bit 读写能力,Zen4 是 256-bit,Intel Golden Cove 的读取为 512-bit、写入是等效 168-bit。
更多底层测试在本文后面,现在让我们来看看 Ryzen 9000 系列的产品规格。
目前发布的 Zen5 桌面产品有 4 个型号,分别是 Ryzen 9 9950X、Ryzen 9 9900X、Ryzen 7 9700X、Ryzen 5 9600X,规格如下:

首轮上市的只有单 CCD 版本也就是 Ryzen 9700X 和 Ryzen 9600X,双 CCD 版本会在稍后,本文测试的就是其中的 Ryzen 7 9700X,你可以将其视作上代产品 Ryzen 7 7700X换代,它们都是单个 8 内核 CCD。
和双 CCD 版本相比,Ryzen 7 9700X 除了内核规模减半外,由于和 SDF 总线连接方面写入总线只有 128-bit,因此有效写入带宽也会减半,但是读取带宽是满血的 256-bit。
AMD 提供的 TDP 值其实已经没啥参考价值,比较有意义的还是 PPT 或者说 Power Package Tracking,它和 TDP 的关系是 TDP * 1.35。
像这里的 Ryzen 7 9700X TDP 是 65 瓦,它的 PPT 值就是 88 瓦左右,大家选择给 AMD Ryzen 选择散热器的时候记得要用 TDP * 1.35 来做选择,确认散热器具备相应 PPT 解热能力。
绝大部分的 AM5 主板在更新固件后都能使用 Ryzen 9000 桌面处理器,据闻主板厂商正在做支持 DDR5 7600MT/s 的固件,不过到目前为止我们的测试平台还只能达到 7200MT/s。
当然,高频内存设置未必是 Ryzen 9000 的最佳解,UCLK:MCK 的最佳比值为 1:1 时的同步频率 6400MT/s,如果再收紧时序参数,性能并不亚于搭配高频内存的水平。
底层测试——内存/Cache 带宽、时延以及能耗比
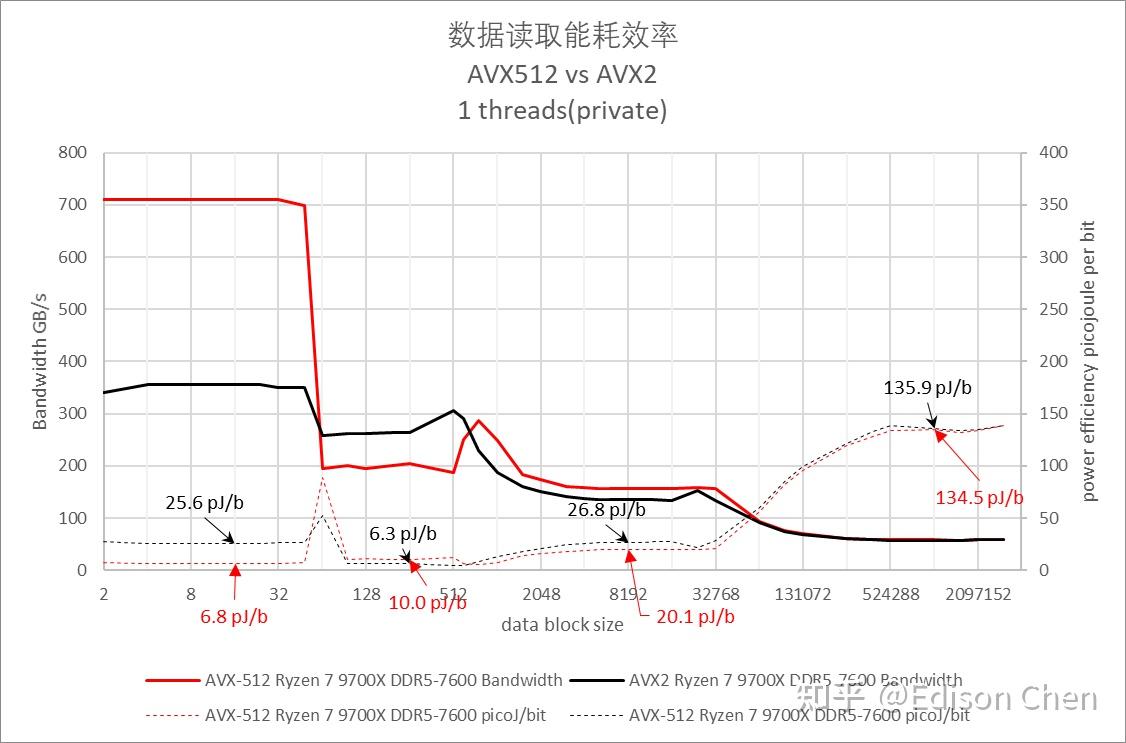
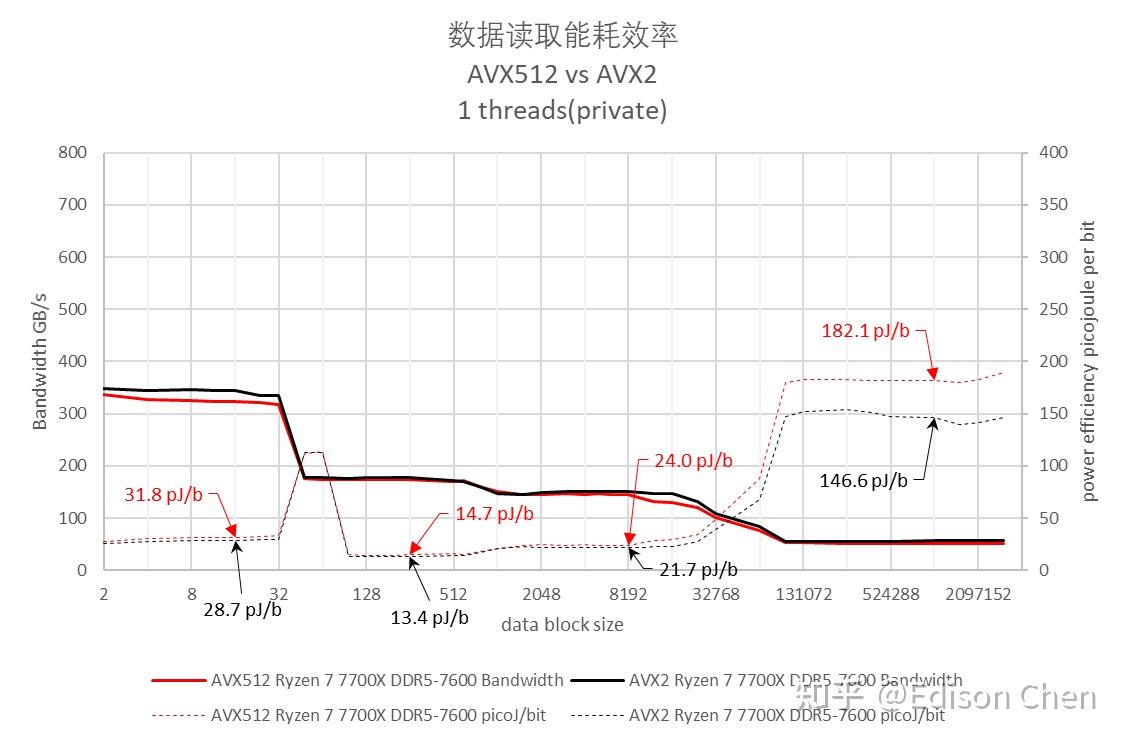
从测试结果来看,Ryzen 9 9700X 启用 AVX512后在 L2 Cache 处发生了低于 AVX2 的情况,这应该是因为降频所致(这张图里的测试数据是在并没有锁定 CPU 频率的情况下获取)。
在 L1 Cache 阶段 AVX512 指令集下,Ryzen 9 9700X 的读取带宽为 709.36 GB/s,256 KiB(L2 Cache)处为 205.13 GB/s,8 MiB(L3 Cache)处为 155.83 GB/s,1 GiB(内存)处为 57.89 GB/s(注意,这里的数据为单线程)。
在能耗方面,在 L1D Cache 内的话,AVX512 时的能耗比为每 bit 6.8 皮焦耳(比 7700X 降低 78.6%),AVX2 为 25.6 皮焦耳(比 7700X 降低 10.8%);
在 1GiB 时,AVX512 的能耗比为每 bit 134.5 皮焦耳(比 7700X 降低 26.1%),AVX2 为 132.3 皮焦耳(比 7700X 降低 7.3%)。
底层测试——指令吞吐和时延
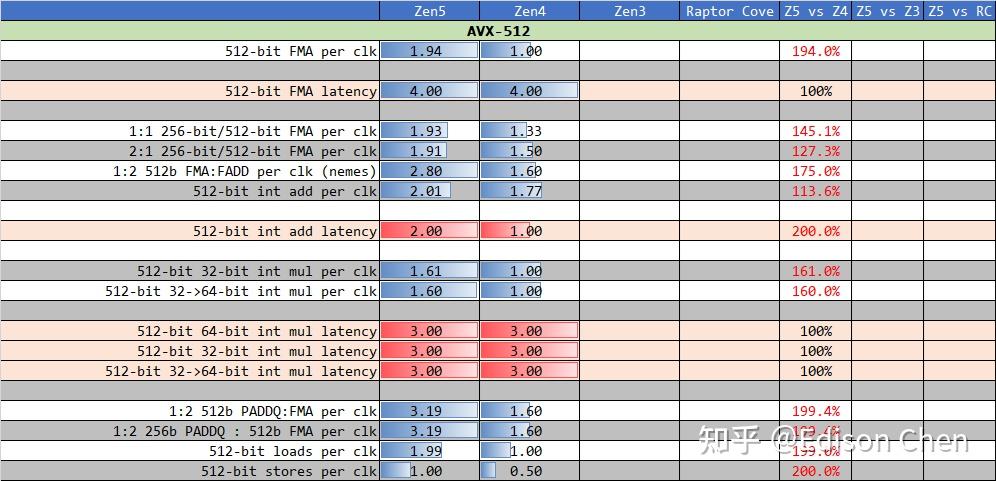
Intel Core 13 代和 14 代处理器除了它们发布时的固件,现在关闭 E-CORE 也无法启用 AVX512。
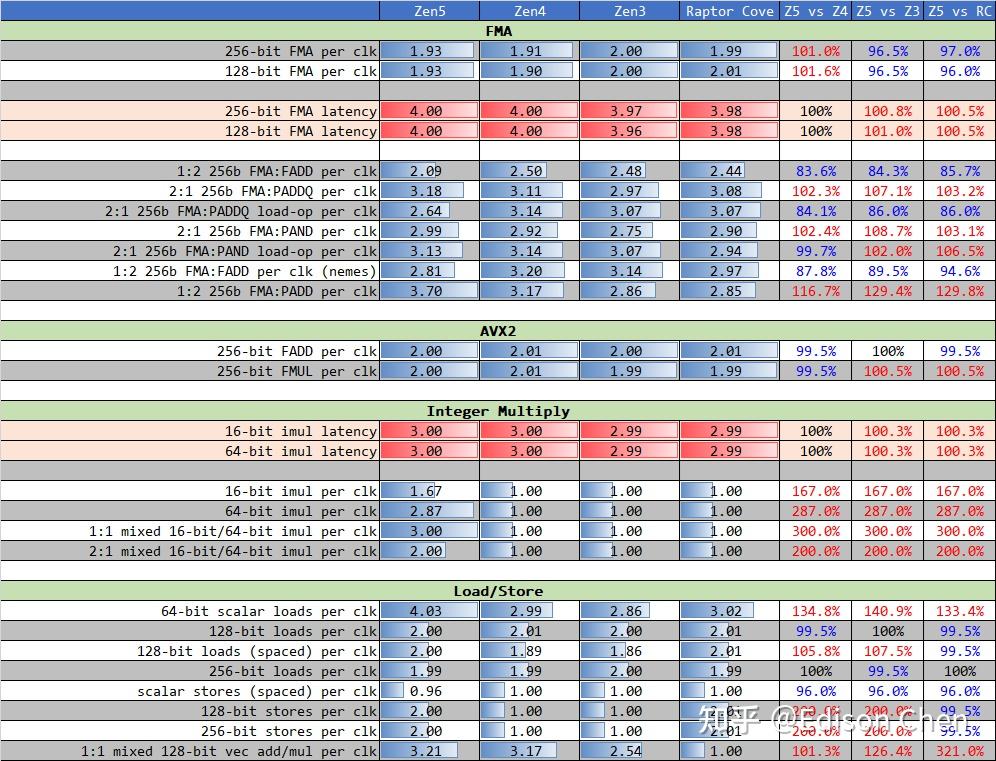
从测试结果来看,Zen5 和 Zen4 相比:
1:1 方式混合 256-bit 和 512-bit FMA 指令时,吞吐比 Zen4 提升了 50%。
2:1 方式混合 256-bit 和 512-bit FMA 指令时,吞吐比 Zen4 提升了 27%。
1:2 方式混合 512-bit FMA 和 FADD 指令时,吞吐比 Zen4 提升了 75%。
512-bit 整数 add 指令吞吐比 Zen4 提升了 13%。
512-bit 整数 add 指令时延是 Zen4 的两倍。
512-bit 32-bit int mul per clk 测试的是 vpmulld zmmzmmzmm 指令,以 AVX512 的 zmm 存储 512-bit 数据进行 32-bit 整数乘法,这条指令相当于单次执行 16 个 32-bit 乘法运算。在这个测试中,Zen5 比 Zen4 快了 60%。
512-bit 32->64-bit int mul per clk 的情况类似。
在 512-bit 访存指令方面,Zen5 无论读取还是写入,性能都是 Zen4 的两倍。


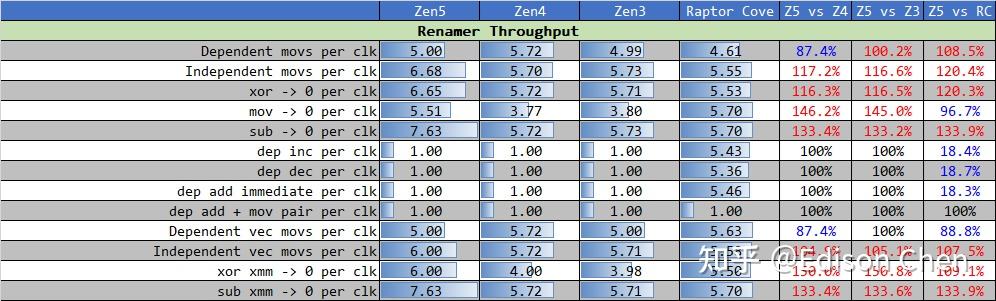
其中,renamer 吞吐测试测试的是乱序流水线中寄存器重命名单元的性能,该单元的作用主要是消除指令之间寄存器相依问题,从而提高指令集并行能力或者说处理器的吞吐性能。
其中,还有 dep 的测试项目都是无法实现寄存器重命名的,其余指令则是可以执行寄存器重命名处理。
从测试结果来看,相依性的 mov 指令 Zen5 会比 Zen4 低一些,但是在不相依的时候,IPC 从 5 提升到了 6.7(提升了 34%),这说明 Zen5 在重命名工位的资源能比较好的支撑流水线后端更强的访存单元。
Raptor Cove(Golden Cove)在这组测试中的 dep add immediate 等指令时,吞吐要比两个 AMD 微架构快得多,这其中 dep inc 这个指令其实是连续跑 inc %r15(对 r15 寄存器里的值加 1 ),此时 Raptor Cove 的指令吞吐量是 Zen5/4 的 5.43 倍。
底层测试——流水线深度
现代处理器都采用了多级工位设计,大家把这种多级工位设计成为流水线化或者管线化。
流水线深度和处理器频率延伸能力、分支预测失败惩罚有密切关系。
一般来说,流水线工位越细分,各个工位的时间片就越短,处理器的频率看起来越就越高,但是工位越多,分支预测缺失导致的性能损失也就越多。例如 5 级工位的流水线遇到分支预测缺失,可能也就是损失 5 个处理器周期,但是如果是 20 级流水线可能损失的 CPU 周期就会达到 20 个。
现在的内核流水线设计异常复杂,不同指令流向经过的流水线工位数可能是不一样的。
为了探测 Zen5 的流水线深度,我使用了多种代码来测试。
下表中的左侧是以伪代码方式提供分支程序测试片段,以第 7 个测试(Test 6)为例:
Test 6N= 18 brMOVZX XOR ; if (c & mask) { REP-N(c^=v[c-256]) } REP-2(c^=v[c-260])
这段伪代码中包含了一个 MOVZX 内存载入操作指令,根据处理器的不同,它可能需要额外的 5 到 6 个周期(可能更少)来执行,在支持乱序执行、乱序 L/S 的处理器中,这个动作占用的流水线工位通常会被掩盖掉。
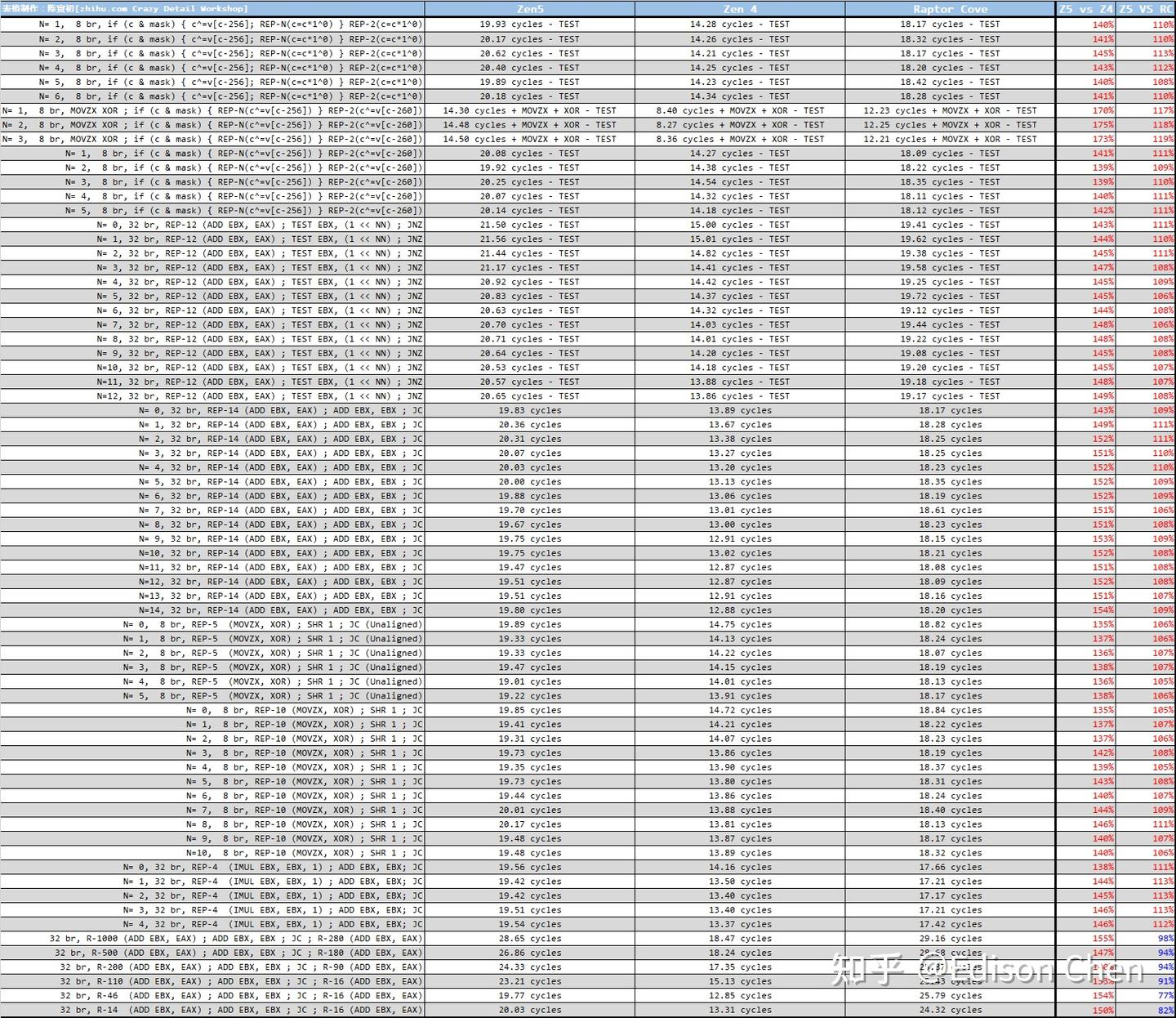
从实测结果来看,Zen5 的分支预测缺失导致的惩罚要比 Zen4 高得多,平均达到了 20.1 周期,而 Zen4 是 13.83 周期,Raptor Cove 是 18.83 周期,可以认为 Zen5 的等效整数流水线深度大约在 20 个级工位左右。
从这点可以认证 Zen5 和 Zen4 在内部结构上存在巨大差别。
底层测试——分支预测
分支预测是乱序执行处理器非常重要的组成,最早好像是 IBM 的分立元件处理器 360/91 上实现,当年 Cyrix 的 5x86 可能是第一款号称支持动态分支预测的 x86 处理器,但是该功能居然在最终版本被禁用,同年稍后推出的 Pentium Pro 则应该是真正将动态分支预测落地实用的 x86 处理器。
分支预测常见的类型有 Direction Prediction 和 Indirection Prediction,前者最常见的有 if else,其跳转的目标是确定的(跳转的方向 A 或者 B 设定好的),而后者虽然也有 if else 等形式,但是跳转的方向则是不确定的(A 和 B 的位置是不确定的)。
以生活中的例子来举例。
例如,你在早上出门的时候要判断是否带雨伞,如果天气预报说下雨,那你就会带雨伞,否则不带。对这种分支做预测,就是方向预测。
依然是上面的带雨伞,但是现在你虽然知道要带雨伞,但是不知道雨伞放哪里了,你需要找家人,询问放在家里什么地方,这就是间接预测。
我们前面的测试用了 100% 无法成功预测的指令和可以 100% 成功预测的指令来测量分支预测缺失导致的惩罚周期数来估计流水线深度,下面让我们对这部分进行更深入的测试。
首先是方向预测。
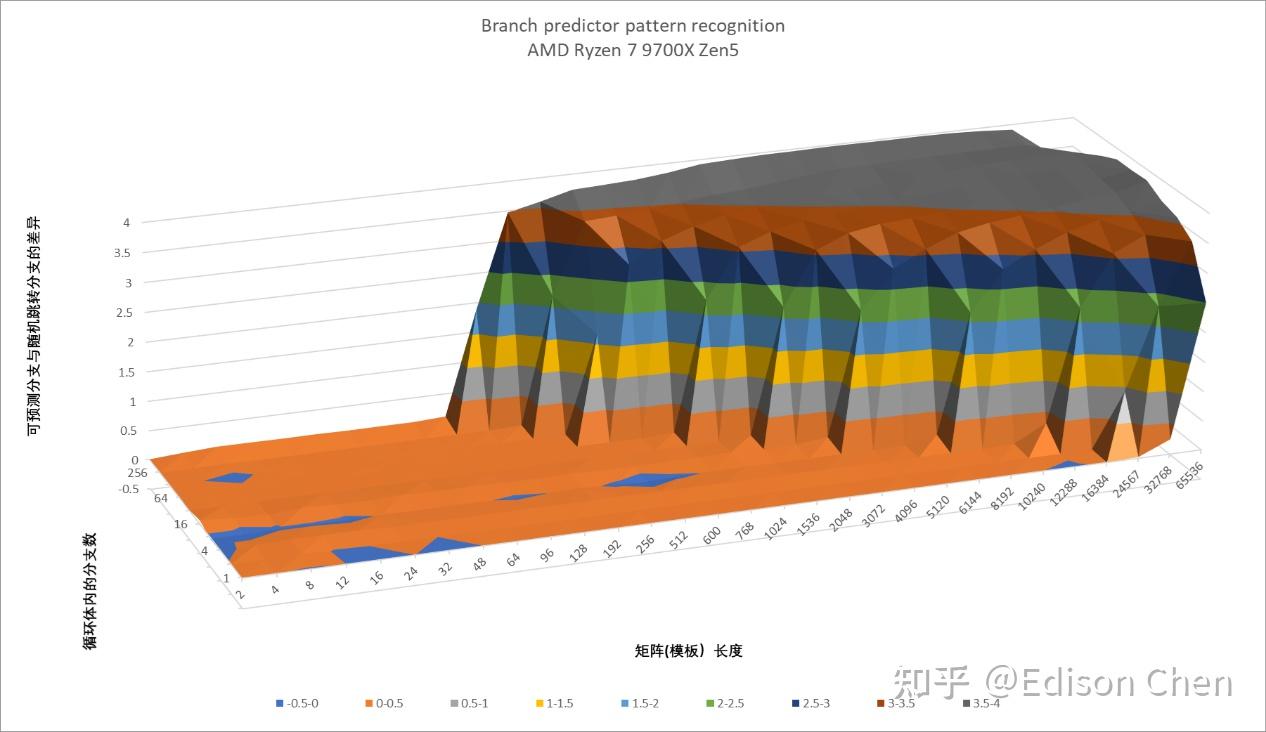
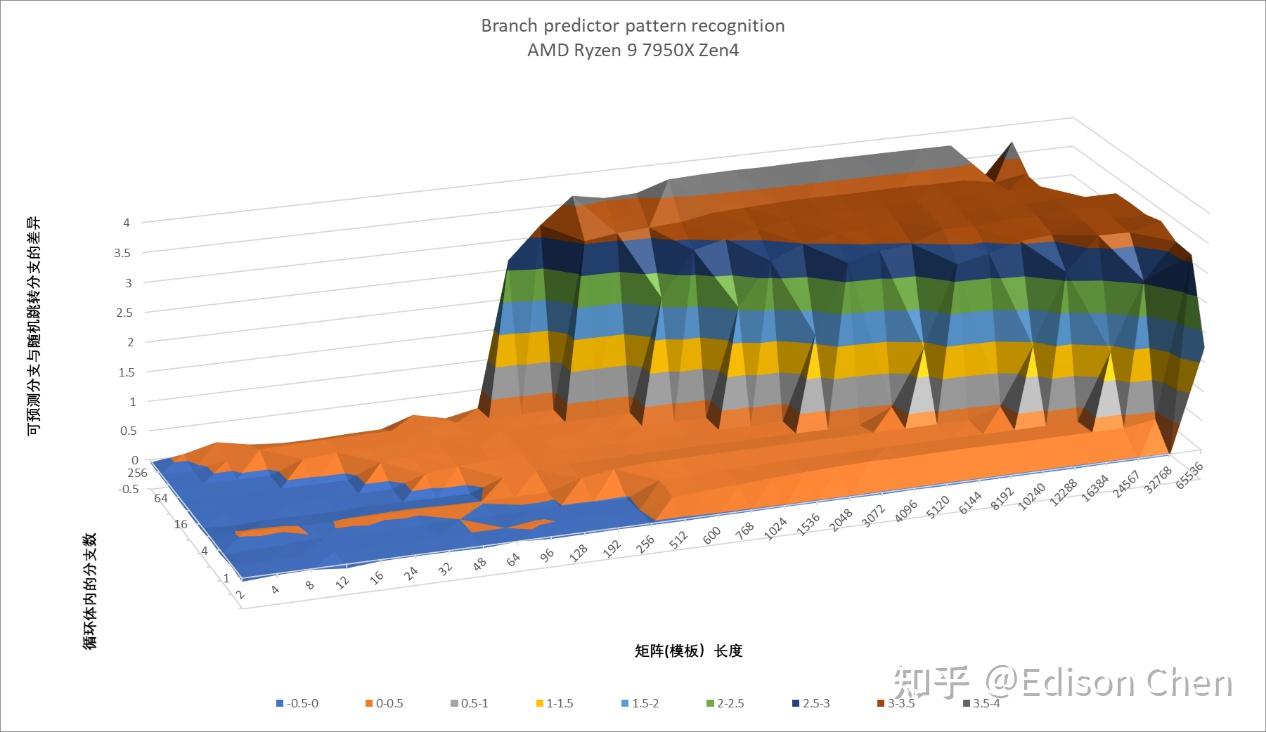
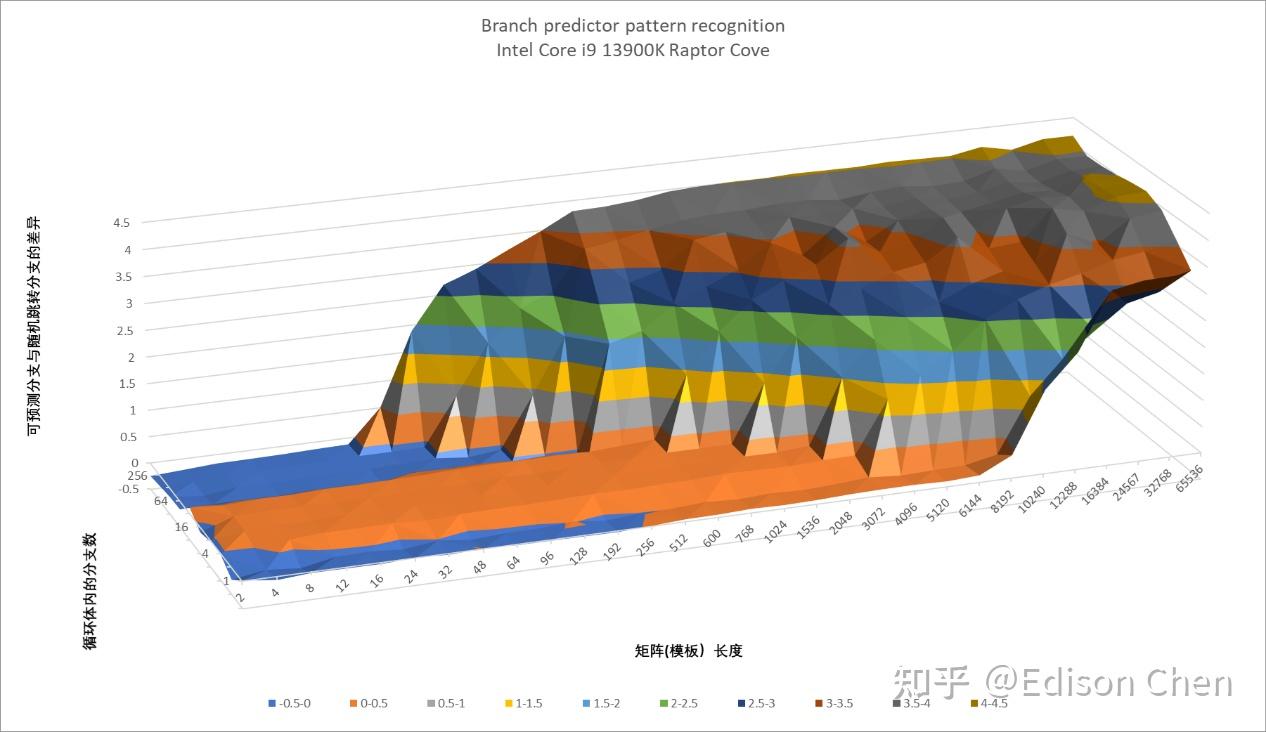
上面这几张图分别是 Zen5、Zen4、GoldenCove 的分支预测模式识别曲面图,测试的分支预测类型方向预测。
按照对角线来看的话,图中左下侧代表的是最简单的分支序列,右上侧则是最复杂的分支序列。
理想的状态应该是完全平坦的底部或者说一马平川,曲面上升越陡峭,意味着分支预测器越容易发生预测缺失。具体个别点位上的变化不需要特别关注,主要看发生明显抬升的位置。
从测试结果来看,Zen5 和 Zen4 都在 32K 处开始出现比较明显的抬升,Raptor Cove 则是在 8K 开始出现比较明显的抬升。
接下来让我们看看间接预测。
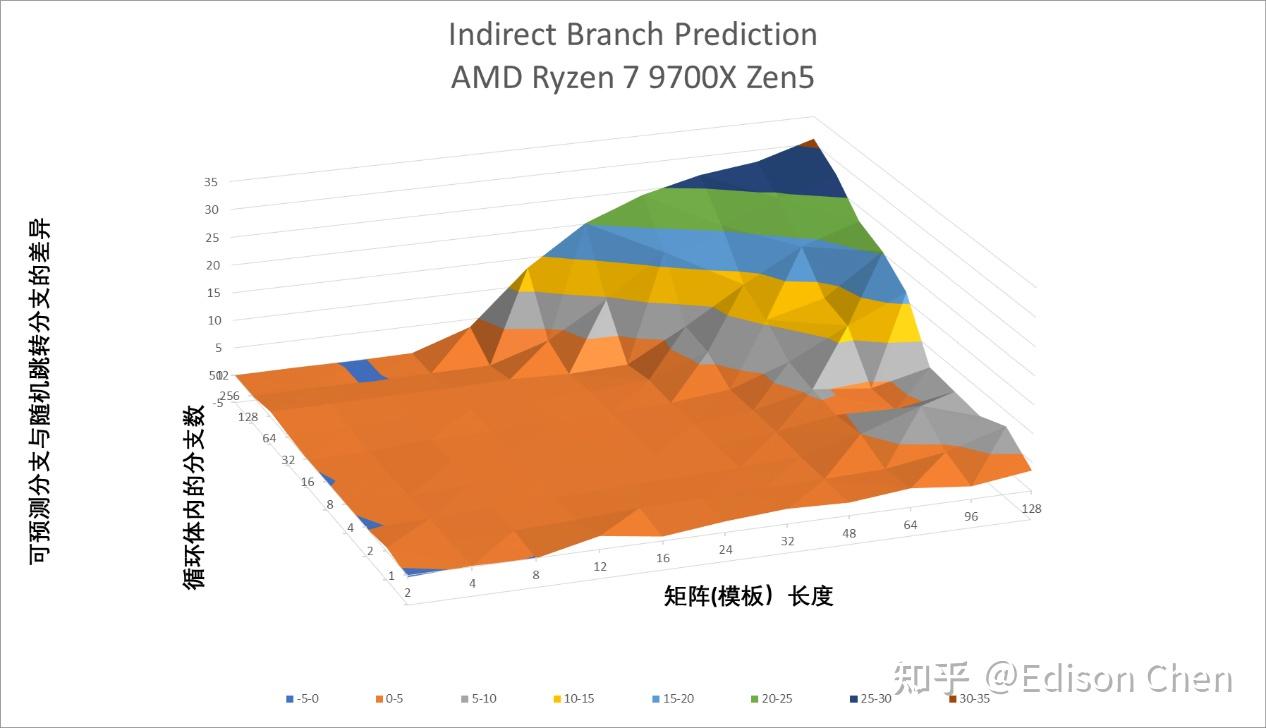
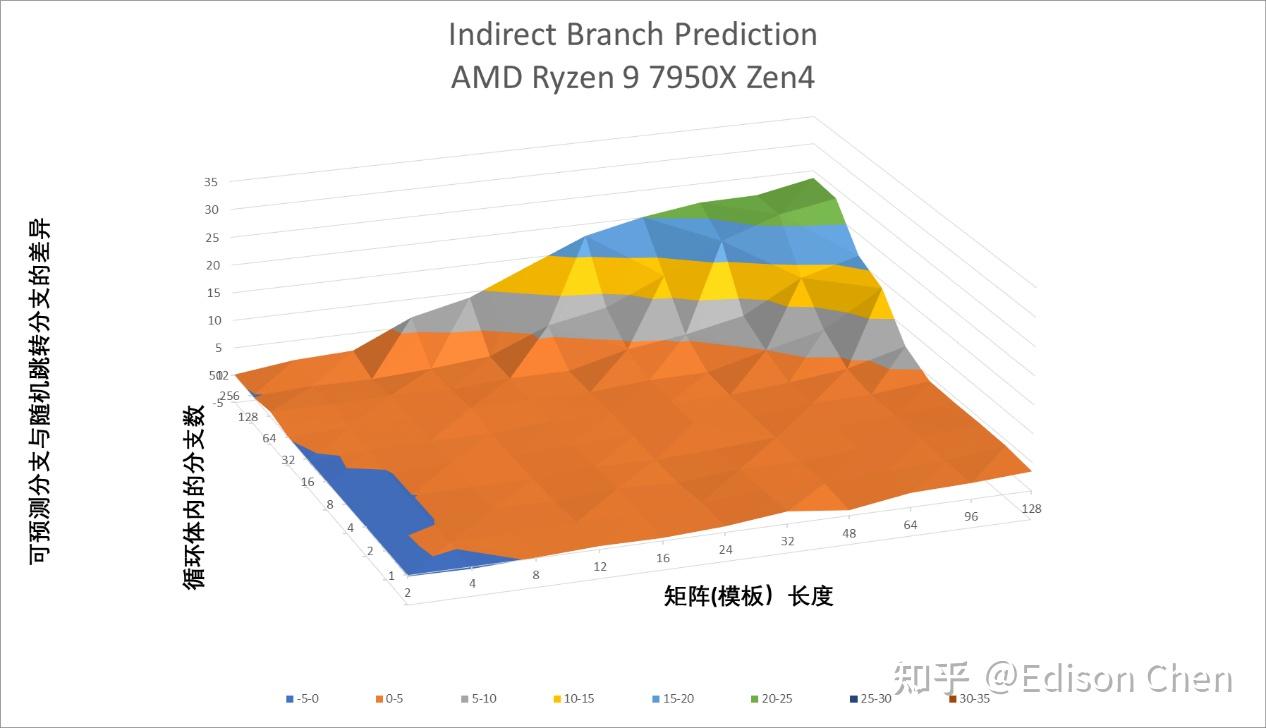
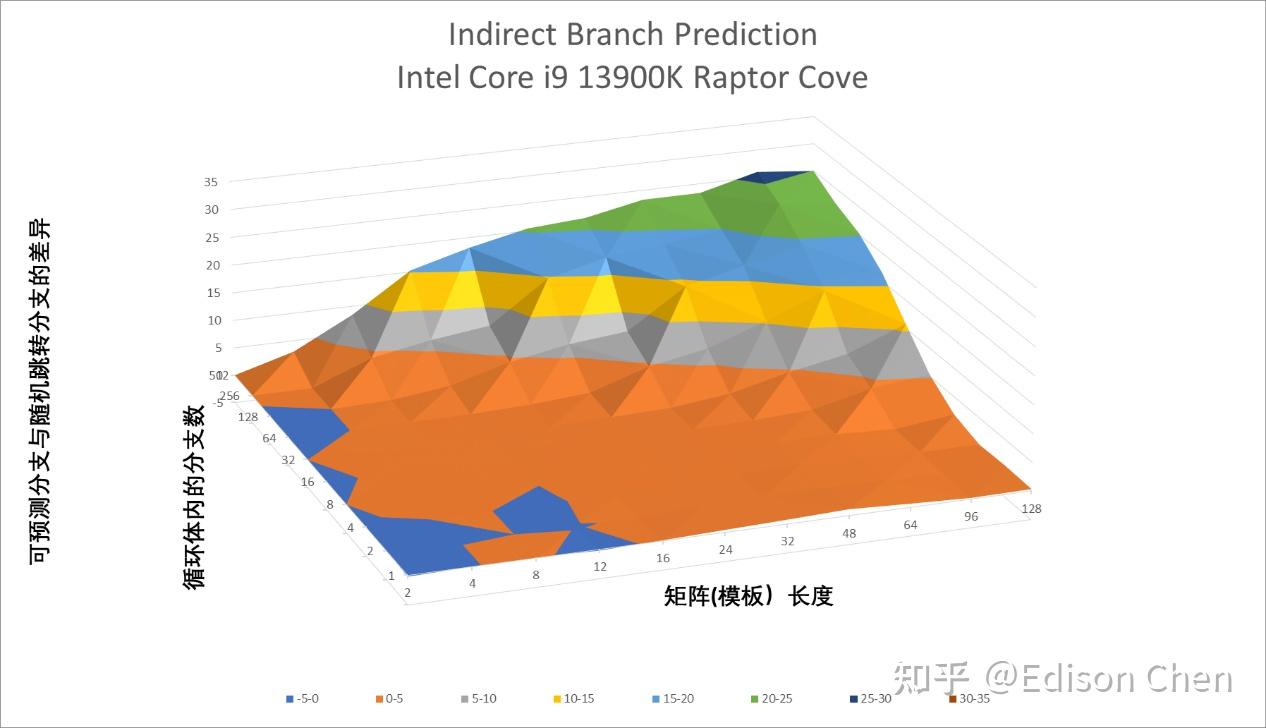
间接预测要比方向预测更复杂更棘手,因为跳转的方向是近乎不确定,AMD 在多年前的 Zen1 里就引入了名为 ITA 的间接目标标签技术用于增强这方面的表现:
从测试结果来看,AMD Zen5 在目标数量达到 16 个的时候出现高于均值的跳变,而 Zen4 则是在 8 个目标的时候出现高于均值的跳变。Intel Raptor Cove 在 4 个目标后就发生高于均值的跳变。
整体而言,AMD Zen5 具有比 Zen4 更出色的间接预测能力,曲面图的地平坦度(代表了成功预测的分支数)比 Zen4 好不少,不过相对的如果预测失败其受到惩罚要高(陡峭)不少。
底层测试——Cache 一致性性能
在多处理器系统里,各处理器如果需要更新某块内存里的数据,就需要同时更新各处理器相应缓存里的对应数据,在有些情况下有可能会性能瓶颈(虽然对于桌面用户来说极为罕有),Cache 一致性性能测试就是为了测试 CPU 的性能表现。


从测试结果来看,单 CCD 的 Ryzen 7 9700X 核间时延要比 Ryzen 7 7700X 略高。
接下来,让我们进入测试环节,首先说一下测试平台:
测试平台
CPU:
AMD Ryzen 7 9700X
Ryzen 7 7700X
Ryzen 7 5800X
Intel Core i9 13900K
Core i9 14900K
主板:
AMD Ryzen 9000/7000:微星 B650M GAMING PLUS WIFI MS-7E24
AMD Ryzen 9000/7000:华硕 ROG X570E Gaming
Intel Core i9 14900K:华硕 ROG MAXIMUS Z790 APEX ENCORE
Intel Core i9 13900K:华硕 ROG STRIX Z790-H GAMING WIFI
内存:
影驰 HOF OC LAB AURORA S 16 GB*2(7700X、9700X、14900K)
七彩虹 CVN DDR-6000 16 GB*2(13900K)
阿斯加特(Asgard) DDR4 3600*4(5800X)
内存频率设置基本都以该内存在各自平台上的极限来设置,作为参考,在 CPU2017 中提供了 Ryzen 7 9700X DDR5-6400CL28 的设置。
操作系统:
Windows:Windows 11 23H2
Linux:Ubuntu 24.04 Kernel 6.11
编译器:GCC 14.1 + vector tree patch(GCC 14.1.1 会采纳)
备注:
13900K 采用的主板 BIOS 为去年(2023 年) 8 月份的版本(1303),尚未被 Intel 今年的缩缸固件影响。
14900K 采用的主板 BIOS 为今年 5 月份的版本,版本号为 1301,多核模式设置为解除所有限制。主板曾经更新过最新固件,不过回退到 1301 后性能依然维持以前的水平。
关于编译器部分,CPU2017 使用的为 gcc 14.1,但是该版本在遇到 AVX512 和 -Ofast 组合的时候会在编译 CPU2017 测试集的时候出错,此问题在我递交 issue 到 GNU 后,确认是独属于 GCC 14.1 的问题,很快获得了一个 patch,问题得到解决,该 patch 预期会在 14.1.1 中应用。
处理器基准测试——SPEC CPU2017
CPU 2017 是非盈利机构 SPEC(标准性能评估公司)推出的 CPU 性能评估套件,SPEC 成立于 1998 年,会员包括 Intel、AMD、IBM、DELL、联想、华硕、技嘉等业界大公司,每隔大约 10 年就会推出一版新的 CPU 性能评估套件,CPU 2017 是该机构在 2017 年推出的,是所有处理器、电脑厂商做处理器性能评估的最重要手段之一(如果不是使用上有一定门槛,上面这句话的“之一”是可以省略的)。
SPEC CPU 的特点是由各个机构提供实际应用的源码,它的每一个子项目其实都是源自真实应用修改而来,其修改主要是针对可移植性和遵循的语言标准,例如 x264 的真实版本采用了大量的汇编代码,但是这样的形式不利于移植到不同指令集架构上测试,因此 CPU 2017 中的 x264 采用的是纯 C 语言版本。
和上一版本 CPU 2006 相比,CPU 2017 的代码已经全面更新,虽然依然使用 C/C++ 和 Fortran,但是相对以前的版本来说,已经变成了多语言的大混装。Fortran 语言同时出现在浮点和整数测试集,而非像以往那样只出现在浮点测试集。
CPU 2017 的规则更加严谨,speed 测试集允许使用 OpenMP 多线程处理,主要测试较大数据集和较大访存压力下的单任务多线程性能,而 rate 测试集则只允许单线程,禁止自动并行化,但是允许以多任务的方式跑多个 rate 测试,目的是测试吞吐率,单个 rate 任务的访存压力要比 speed 小很多。
不过 speed 测试集也不是全部项目都支持多线程,只有浮点密集型的 fpspeed 所有项目支持多线程,整数密集型的 intspeed 10 个子项目中只有最后的 657.xz_s(数据压缩)是支持多线程的。
这样的规则让以往 CPU 2006 以及更早版本中常见的编译器自动并行化“优化”手段被禁止使用,减少了测试结果的混乱(测试如果使用了编译器自动并行化后,实际上变成了编译器比拼),提高了可比性。
测试使用了 gcc 14.1 加额外的 vector tree 修正补丁(解决 avx512 和 -Ofast 同时导致 fortran 编译失败的问题,补丁由 gcc 官方开发团队提供,会在 gcc 14.1.1 采用)。
编译开关为 -march=native 和 -Ofast,-march=native 表示采用编译器预设的微架构识别信息来选择最佳化设置,对 Zen5 架构的处理器来说,在 gcc 1.41 上面 native 就是 znver5。
我另外都跑了所有参赛选手的 x86-64 和 x86-64-v4(支持 avx512f)这两种开关,性能表现会比 native 略低一点点,为了节省篇幅和图表制作时间这里就不放了。
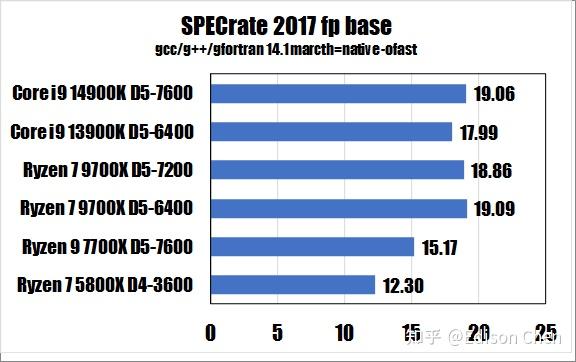
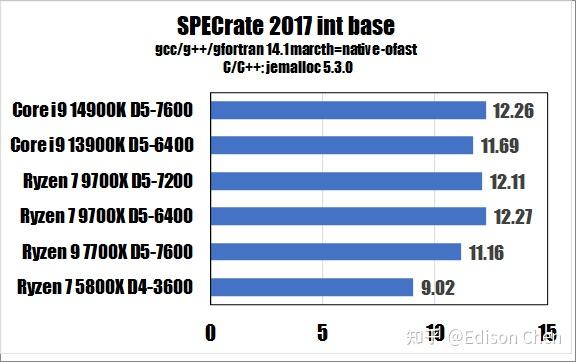
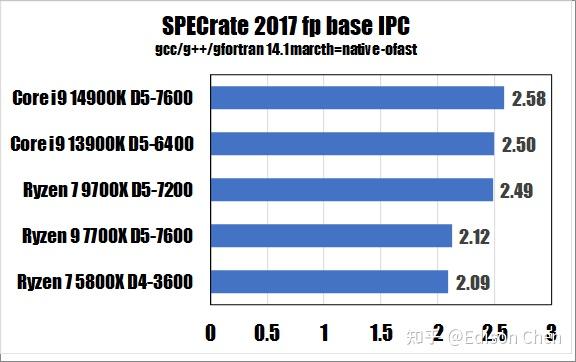
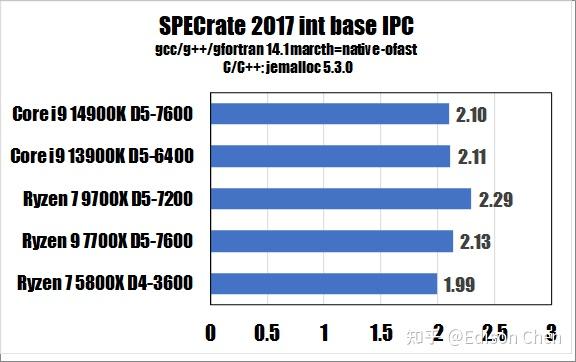
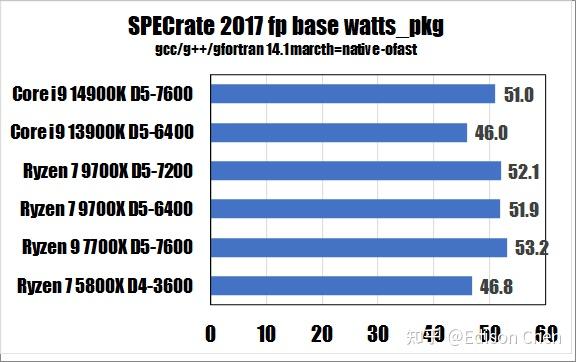
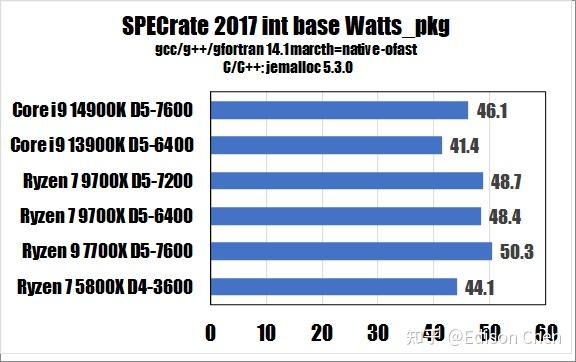
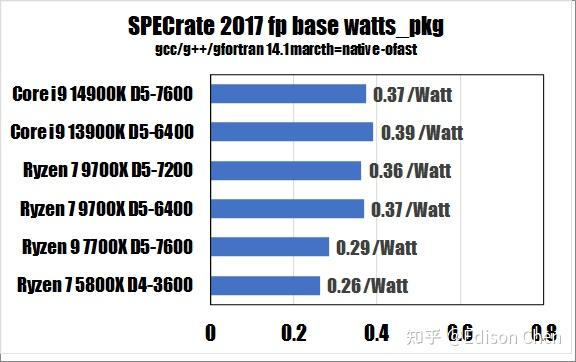
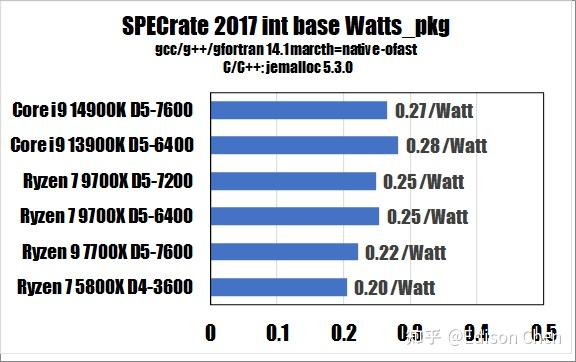
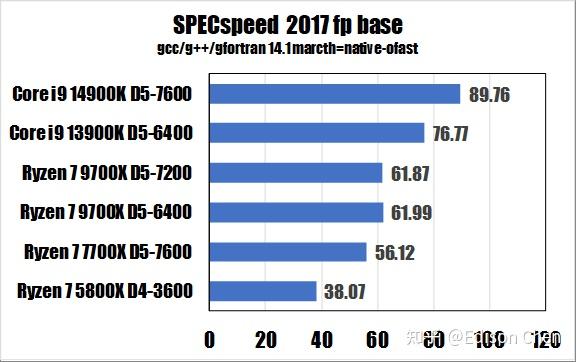
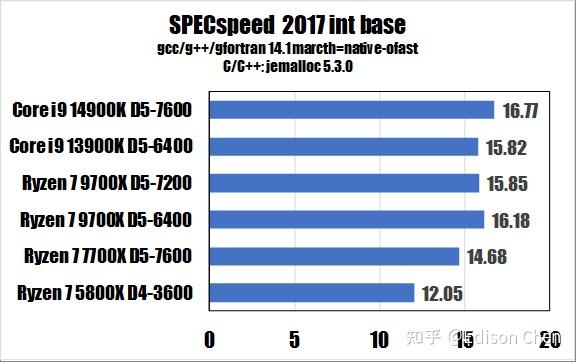
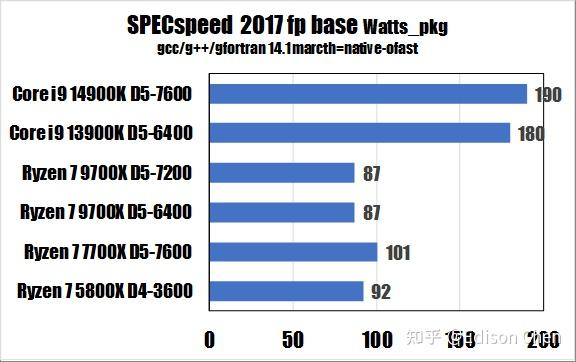
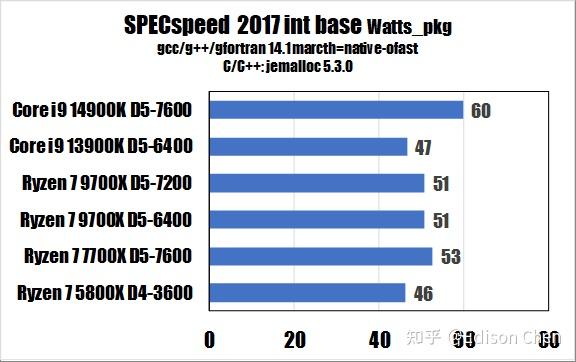
从测试得分来看:
在 SPECrateINT_2017(整数单任务)测试方面,Ryzen 7 9700X(DDR5 7200)比 Ryzen 7 7700X(DDR5 7600)快大约 9%。
在 SPECrateFP_2017(浮点单任务)测试方面,Ryzen 7 9700X 比 Ryzen 7 7700X 快大约 24%。
在 SPECspeedINT_2017(整数重载任务)测试方面,Ryzen 7 9700X 比 Ryzen 7 7700X 快大约 8%。
在 SPECrateFP_2017(浮点重载多线程)测试方面,Ryzen 7 9700X 比 Ryzen 7 7700X 快大约 10%。
在 IPC(每周期指令数)方面:
在 SPECrateINT_2017(整数单任务)测试方面,Ryzen 7 9700X 比 Ryzen 7 7700X 高大约 7%。
在 SPECrateFP_2017(浮点单任务)测试方面,Ryzen 7 9700X 比 Ryzen 7 7700X 高大约 17%。
在耗能(CPU 本体全片)方面:
在 SPECrateINT_2017(整数单任务)测试方面,Ryzen 7 9700X 是 Ryzen 7 7700X 的94%。
Ryzen 7 9700X 每瓦特得分是 0.25,Ryzen 7 7700X 每瓦特得分是 0.22。
在 SPECrateFP_2017(浮点单任务)测试方面,Ryzen 7 9700X 是 Ryzen 7 7700X 的98%。
Ryzen 7 9700X 每瓦特得分是 0.36,Ryzen 7 7700X 每瓦特得分是 0.29。
在 SPECspeedINT_2017(整数重载任务)测试方面,Ryzen 7 9700X 是 Ryzen 7 7700X 的 96%。
Ryzen 7 9700X 每瓦特得分是 0.25,Ryzen 7 7700X 每瓦特得分是 0.22。
在 SPECrateFP_2017(浮点重载多线程)测试方面,Ryzen 7 9700X 是 Ryzen 7 7700X 的 86%。
Ryzen 7 9700X 每瓦特得分是 0.36,Ryzen 7 7700X 每瓦特得分是 0.22。
DDR5-6400CL28 下的 Ryzen7 9700X 性能普遍比 DDR5-7600CL34 更快,虽然幅度不算很大,该设置下单线程下的优势要大于多线程。
处理器基准测试——7z
7z 是目前比较常见的压缩、解压缩打包工具,免费开源,这么多年来一直是我系统中唯一安装的压缩、解压缩软件。
7z 的压缩算法采用了 LZMA,内建了一个基准测试工具,我们测试的版本为 23.01 for linux。
其中解码测试比较偏重 CPU 整数性能,如果分支预测缺失会有较大惩罚的话,对解压缩性能会有很大的负面影响。
压缩测试很大程度上和内存时延有关。
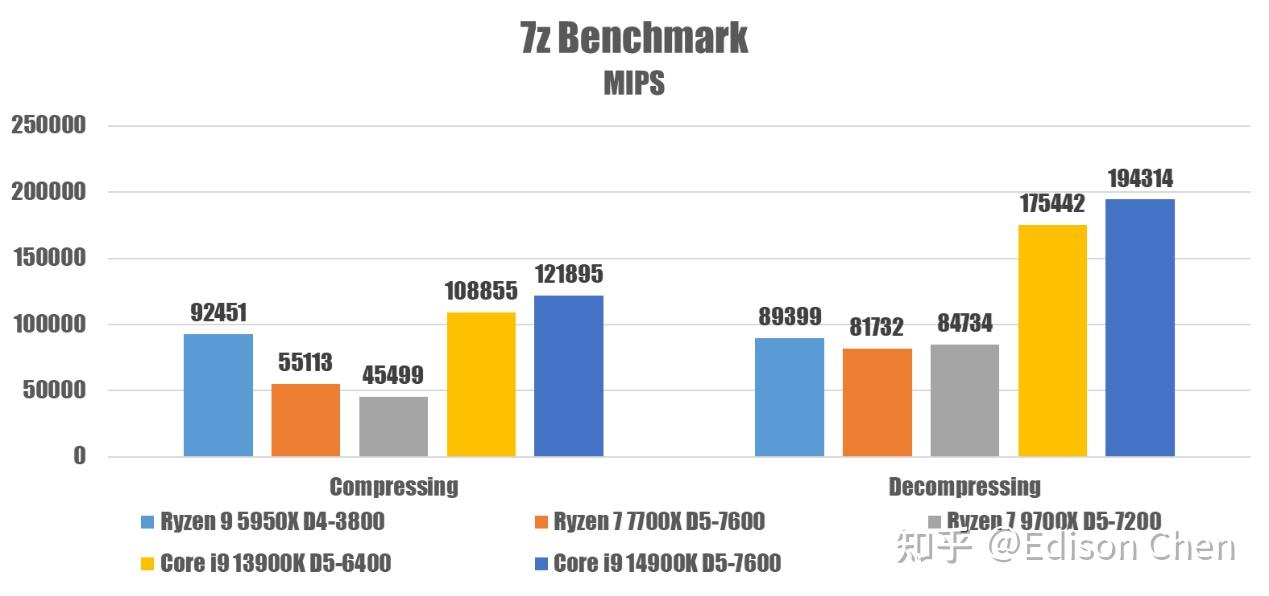
从测试结果可以看到 Zen5 的解压缩性能有点不尽人意,我们前面的测试证明了 Zen5 的等效整数流水线深度是 20 级,而 Zen4 和之前的 Zen 等效整数流水线深度是 14 级,更深的流水线意味着更大的分支预测缺失惩罚。
根据运行特性采集结果,9700X 的全程全核 IPC 大约是 1.36,而 7700X 大约是 1.42,分支预测缺失率在大约 10%,对 Zen5 来说这类应用不会很舒适。
处理器基准测试——x265
x265 是目前最常见的 h.265 开源视频编码器,它采用了大量汇编指令手工优化,是众多视频爱好者的首选编码器。
这里我使用了 duck 4k30 fps 的 y4m 文件作为输入素材,让 x265 对其进行编码,x265 命令行如下:
x265 --preset slow --crf 28 --ctu 64 --profile main10 --input ducks_take_off_2160p50.y4m --output x265_encoed.mp4
这个测试非常吃内存性能。根据运行时的动态指令特性采集分析,x265 的 load 指令占比为 26.7%、store 指令是 7.4%,分支指令是 5%。
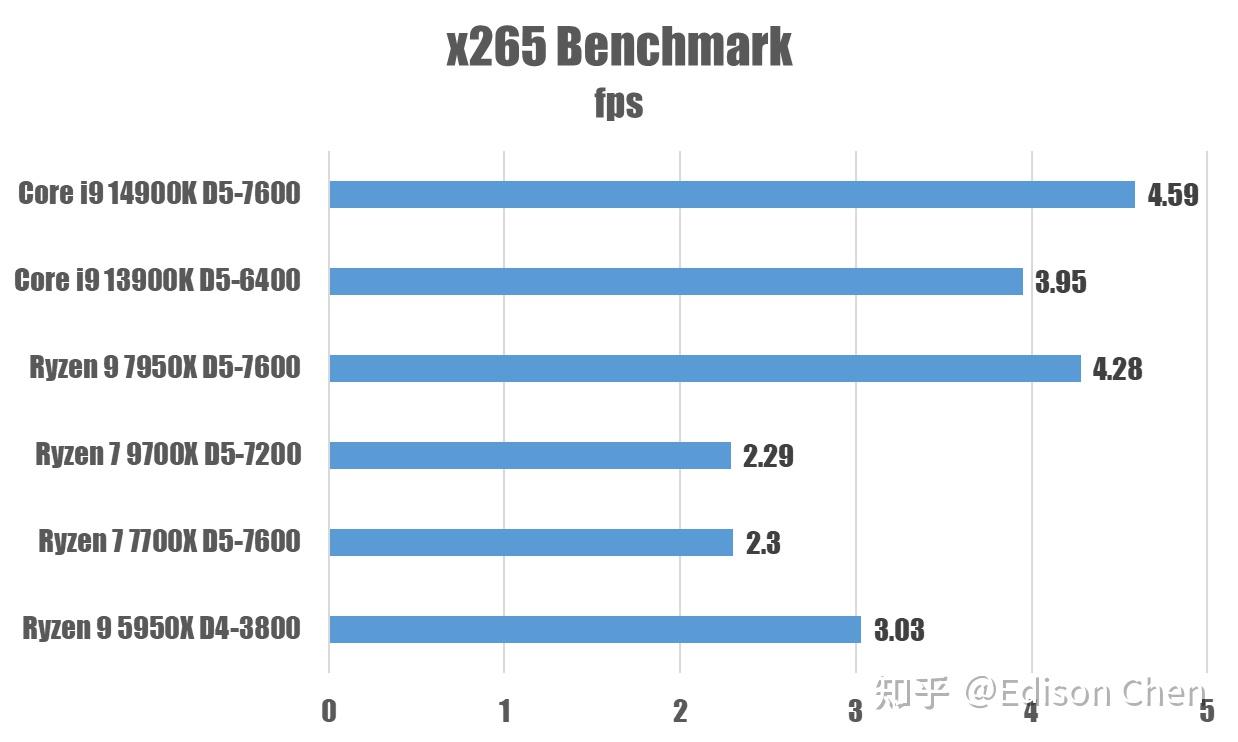
咦,虽然分支指令占比较低,但是在这里 Ryzen 7 9700X 基本上是和 Ryzne 7 7700X 同一水平。
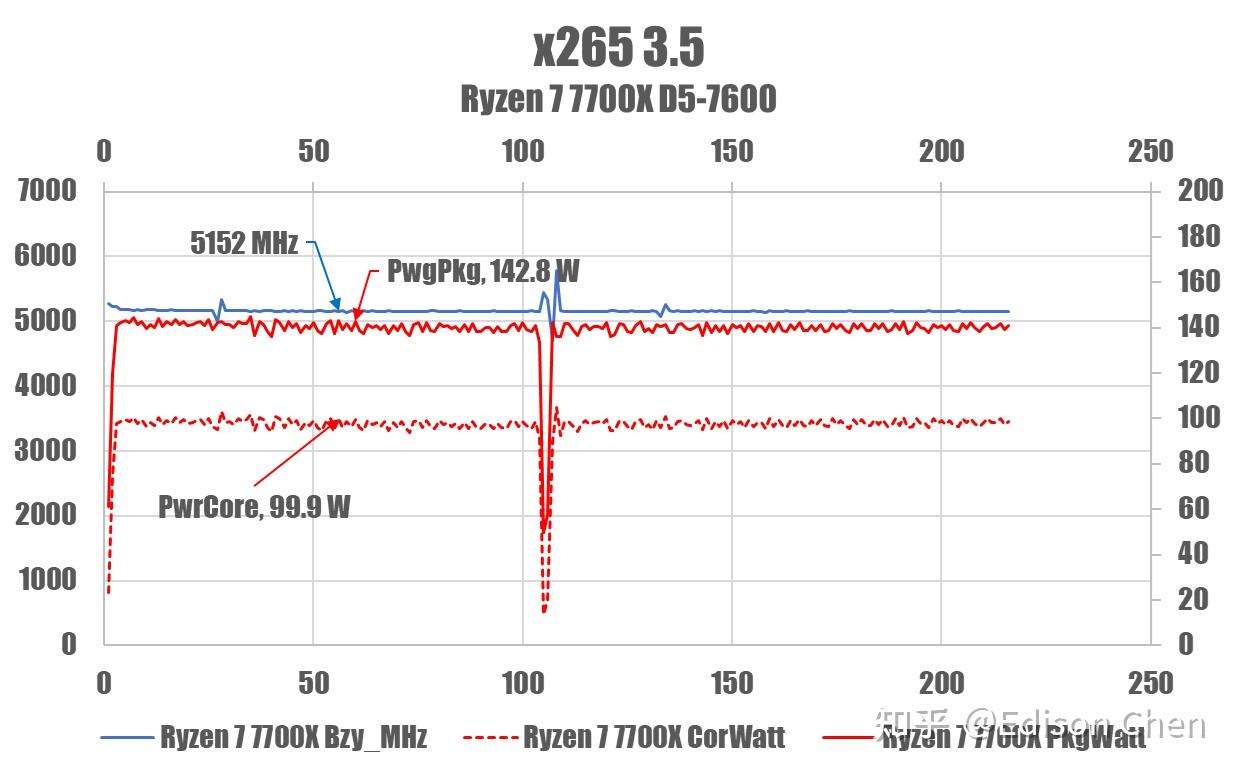
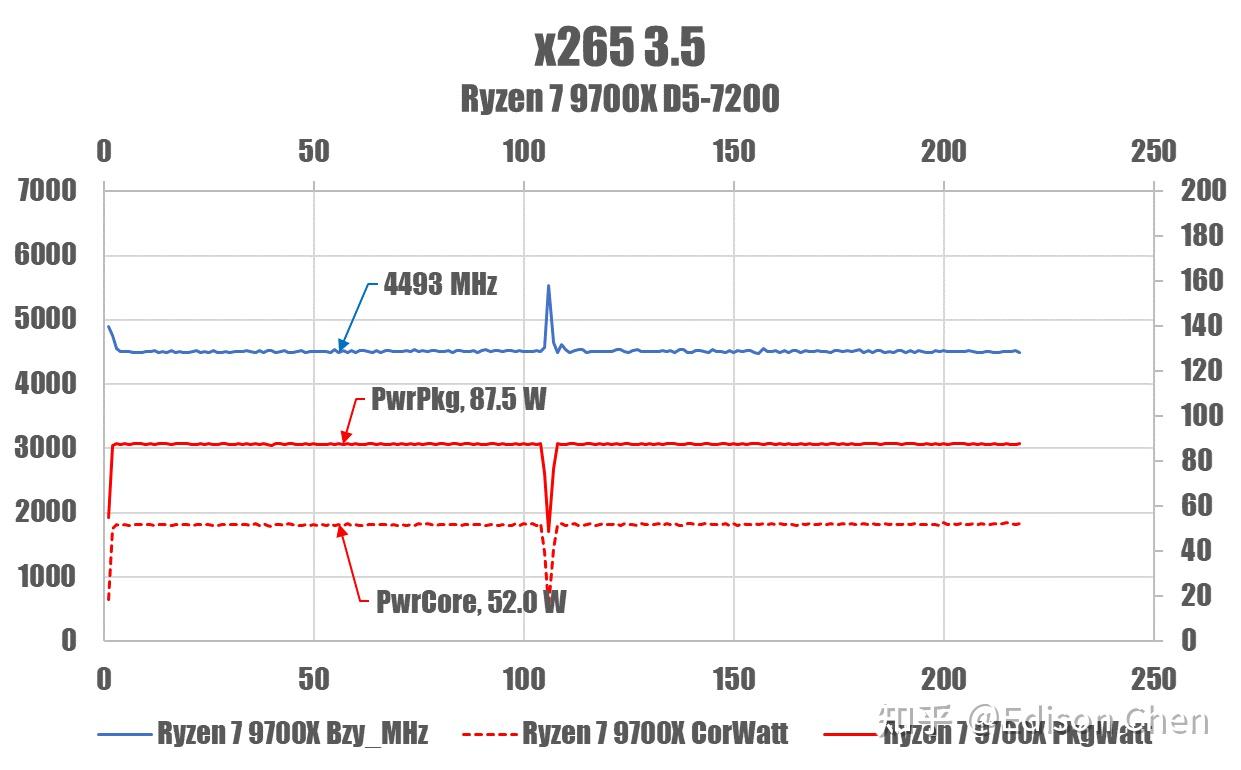
正如大家所看到的,Ryzen X7 9700X 在运行 x265 的时候,全片功率已经达到了 TDP*1.35 的 PPT 上限(87.X 瓦),此时频率降低到了 4493 MHz。
Ryzen 7 7700X 的 PPT 为 105W*1.35 = 141.75 瓦,这里也达到了,此时频率能维持在 5.15 GHz。
所以,这里的情况更像是 Ryzen X7 9700X 触碰到了 PPT 上限禁制,严重影响了性能发挥。
当然,如果此时你将 Ryzen 7 9700X 和 Ryzen 7 7700X的能耗比做对比的话,就会发现前者的能耗比非常出色。
测试总结

从微架构的角度来看的话,Zen5 和 Zen4 相比存在巨大差异:
更深的流水线——等效 20 级,Zen4 则是相当于等效 14 级,额外的流水线深度意味着分支预测缺失造成的惩罚会严重不少,则在 7z 测试中有所体现。
AMD 提供的 65W TDP(~88W PPT)在某些情况下会严重限制 Ryzen 7 9700X 的性能发挥,这在 x265 测试中有体现。
Zen5 的浮点、向量性能要明显好于 Zen4,这在 CPU2017 浮点测试集中有体现。
Zen5 的能耗比相当出色,特别是考虑到更深的等效流水线深度、单周期 AVX512 支持能力。
如果是现在新购电脑的话,基于 Zen5 Ryzen 9000 是的确是最好的选择,当然我说的是当下。
数个月后,我们应该能看到 Zen5 的真正对手——Arrow Lake,按照这次测试的 Zen5 表现来看,我觉得还是 Zen5 有点悬的。但是另一方面,Zen5 应该是有后手的,例如 3nm 版本的 Zen5、更低功耗的 IOD 等等,都是摆在禅师面前的不错选择。
我会持续关注 Zen5 后续以及 Arrow Lake 的相关消息,本文也可能会随时更新,请点击关注便于了解相关动态。