{kind=link}
GTC 主题演讲的实时更新🔗
欢迎来到 GTC 2026!
SAP 中心座无虚席,所有人都翘首以待。
今年主题演讲以一段视频开场。视频将 Token 定义为现代 AI 的基本单位。它是支持科学探索、虚拟世界,以及在物理世界中运行的机器的基石。
随后,NVIDIA 创始人兼 CEO 黄仁勋在现场观众的热烈掌声中登上舞台。
他首先感谢了现场预热的主播们,并重点介绍了参与本次 GTC 的合作伙伴,以及超过 450 家赞助商、1000 场会议和 2000 位演讲者。
“本次大会将涵盖 AI 的五层蛋糕的每一层,”黄仁勋说。
他提及了 CUDA 诞生 20 周年,并称其为推动加速计算发展的“飞轮”。黄仁勋表示“AI 生命周期的每一个阶段”,它都提供支持。
随后,他将话题转向 GeForce,称 NVIDIA 是“GeForce 打造的公司”,而正是这一平台把 CUDA 带给了全世界。他回顾了 GeForce 的发展历史,将其与 AI 的发展全程相联,同时介绍了 DLSS 5,并现场播放了一段视频,展示 3D 引导神经网络渲染如何在本地硬件上实现实时、照片级真实的 4K 性能。更多详情可参见新闻稿。
接下来,黄仁勋介绍了数据处理领域,以及该领域如何在 AI 时代实现加速发展。他详细介绍了 NVIDIA 与 IBM、戴尔(Dell)、谷歌云(Google Cloud)、AWS、Microsoft Azure、甲骨文(Oracle)和 CoreWeave 的合作,以更好地服务客户。
黄仁勋强调了加速计算生态系统的深度,包括汽车、金融服务、医疗健康、工业、媒体、量子计算、零售、机器人和电信。
“所有这些不同的 AI 领域都有 NVIDIA 提供的平台支持。”黄仁勋表示。他还重点介绍了 NVIDIA 丰富的 CUDA-X 库,并称之为 NVIDIA 的“掌上明珠”。
黄仁勋还重点谈及了“AI 原生公司”的崛起。这类全新企业中,既有 OpenAI 和 Anthropic 等知名企业,还有一些不断涌现的新生力量。“过去一年,这一趋势呈爆发式增长,”黄仁勋表示。他提到,风险投资对初创公司的投入达到 1500 亿美元,并回顾了引发最新科技浪潮的一系列技术发展。
他表示受到这一浪潮的影响,市场对 NVIDIA GPU 的计算需求“已经爆表”。“我相信在过去几年里,计算需求增长了 100 万倍,”他说。
因此,黄仁勋预计 2025 到 2027 年期间,该需求增长将至少为公司带来 1 万亿美元收入。
从 Vera Rubin 到未来 —— 计算领域的代际飞跃
黄仁勋提到,凭借极致的软硬件协同设计,NVIDIA 的 Token 成本做到了全球最优。一位分析师将 NVIDIA 描述为“推理之王”。“这就是极致协同设计的惊人力量,”黄仁勋解释道,这是软件和芯片协同设计的过程。
下一步的核心布局,是 NVIDIA Vera Rubin 平台 —— 一个全新的全栈计算平台,包含 7 款突破性芯片、5 套机架级系统,以及一台面向代理式 AI 的超级计算机。该平台还搭载了全新的 NVIDIA Vera CPU 与 BlueField-4 STX 存储架构。
黄仁勋向观众详解了基于这些技术打造的全新系统的核心架构,他表示:“当我们谈及 Vera Rubin 时,我们想到的是一个垂直集成的完整系统。它配备了软件,实现了端到端的延伸,并作为一个巨型系统进行了整体优化。”
展望 Vera Rubin 之后,NVIDIA 的下一代重要架构是 Feynman。
黄仁勋表示,此架构将包含一个新的 CPU:NVIDIA Rosa。黄仁勋表示,该名称来自 Rosalind Franklin,其 X 射线晶体学揭示了 DNA 的结构并重塑了现代生物学。正如 Franklin 揭示了生命隐藏的架构一样,Rosa 旨在高效地在全栈代理式 AI 基础设施中移动数据、工具和 Token。
Rosa 是新平台的核心,该平台将 NVIDIA 新一代 LPU LP40 与 NVIDIA BlueField-5 和 CX10 相结合,通过 NVIDIA Kyber 实现铜缆和光电一体封装的纵向扩展,以及 NVIDIA Spectrum 级光学横向扩展。黄仁勋表示,Feynman 系列处理器推进了 AI 工厂的各个支柱发展,包括计算、内存、存储、网络和安全。
为了帮助加速新 AI 能力的横向扩展,黄仁勋宣布推出 NVIDIA Vera Rubin DSX AI Factory 参考设计和 NVIDIA Omniverse DSX Blueprint。DSX Air 是更广泛的 DSX 平台的一部分,它让企业能够在软件中模拟仿真 AI 工厂,然后再在物理世界中建造它们。
最后,黄仁勋宣布 NVIDIA 将布局太空。新的 Vera Rubin 架构以这位发现暗物质的天文学家命名,而 NVIDIA Space-1 Vera Rubin 等未来系统旨在将 AI 数据中心送入轨道,将加速计算从地球扩展到太空。
适用于 OpenClaw 的 NVIDIA NemoClaw 和 Nemotron 联盟
黄仁勋重点介绍了 OpenClaw,这是由开发者 Peter Steinberger 发起的开源项目,他称之为“人类历史上最受欢迎的开源项目”。
黄仁勋表示:“OpenClaw 开源了智能体计算机的操作系统。现在,OpenClaw 让我们能够创建个人智能体。”
开发者只需一条命令,就可以下载 OpenClaw,建立 AI 智能体,并开始使用工具和上下文对其进行扩展。NVIDIA 宣布在其整个平台上支持 OpenClaw,使开发者能够更轻松地在 NVIDIA 驱动的基础设施上安全地构建、部署和加速 AI 智能体。
黄仁勋表示:“当今世界上的每一家公司都必须制定 OpenClaw 策略。”
为了确保这项技术可以在企业内部安全部署,黄仁勋介绍了 NVIDIA OpenShell 运行时和 NVIDIA NemoClaw 堆栈,结合策略执行、网络护栏和隐私路由。黄仁勋表示,这些技术可以作为“全球所有 SaaS 公司的策略引擎”。
此外,NVIDIA 还通过新的 Nemotron 联盟扩展开放模型生态,围绕六个前沿模型系列展开,包括 NVIDIA Nemotron (语言与推理)、NVIDIA Cosmos (世界模型与视觉)、NVIDIA Isaac GR00T (通用机器人)、NVIDIA Alpamayo (辅助驾驶)、NVIDIA BioNeMo (生物学与化学) 以及 NVIDIA Earth-2 (天气与气候)。
物理 AI
NVIDIA 正将 AI 从数字智能体扩展到物理 AI,支持 AI 在现实世界中导航。
黄仁勋表示,NVIDIA 无人驾驶出租车就绪平台正在吸引更多新的汽车制造商合作伙伴,包括比亚迪、现代汽车、日产和吉利。
他还提到了与 Uber 的合作,将这些车辆部署到其网约车网络中。
除了汽车制造商,NVIDIA 还与工业软件巨头以及机器人领域的领导者,如 ABB、Universal Robots 和 KUKA 合作,集成其物理 AI 模型和仿真工具,从而在生产线上部署更智能的机器人。同时,NVIDIA 也在与 T-Mobile 等电信运营商合作,使基站逐步演进为边缘 AI 平台。
结语
在主题演讲的最后,黄仁勋迎来了一位惊喜嘉宾,来自迪士尼《冰雪奇缘》的雪宝。这个角色就像是从数字屏幕中走出,直接来到舞台上。
“女士们、先生们,雪宝,”黄仁勋说道,这个动画角色随即摇摇摆摆地走上舞台。这一演示由 NVIDIA 的物理 AI 堆栈、Newton 物理引擎和 NVIDIA Omniverse 支持的仿真模拟驱动。
“雪宝,你好吗?是我给你装载了电脑 — — Jetson。”黄仁勋开玩笑说。
当雪宝问这是什么时,黄仁勋回答说:“它就在你的肚子里。你是在 Omniverse 里学会走路的。”
该演示突出了黄仁勋的观点,所有展示内容,从人形机器人到动画角色都是仿真模拟的,而不是预先渲染的画面。
黄仁勋最后回顾了推理、AI 工厂、OpenClaw、物理 AI 和机器人技术主题。随后将舞台交给了一个音乐团体,唱歌的机器人、黄仁勋数字人和一只动画龙虾,他们表演了一首篝火歌曲。
“好了,祝大家 GTC 玩得开心,”黄仁勋说着从舞台左侧离开。雪宝则留在舞台上继续逗乐观众,最后通过舞台暗门慢慢沉入舞台下方。
工作站🔗
2026 年 3 月 16 日🔗
DGX Spark 与 DGX Station 搭配 NVIDIA NemoClaw,为自主智能体提供全栈平台

人工智能正在从基于提示的简单工具,转变为能够推理、规划和执行的智能、长期运行的系统。这些自主智能体不仅可以生成文本,还可以编写代码、调用工具、分析数据、模拟结果并持续改进。
要构建和运行具备超级计算智能的全天候智能体,开发者需要合适的基础设施。
将 NVIDIA DGX Spark 和 NVIDIA DGX Station 系统与全新 NVIDIA NemoClaw 开源栈搭配,为本地开发和部署自主长期运行的智能体,也就是 Claws,提供了终极平台。这些系统将 AI 工厂级的性能直接带到智能诞生之地——桌面端和企业内部。
使用 NemoClaw 保护代理式 AI 安全性
NVIDIA NemoClaw 是一个开源软件栈,可简化始终在线的 OpenClaw 助手的运行——既更安全,又只需单个命令即可完成。它会安装 NVIDIA OpenShell 运行时,该运行时是 NVIDIA Agent Toolkit 的一部分,后者是一个用于运行自主智能体的安全环境,同时也支持 NVIDIA Nemotron 等开源模型。
企业在专有工作流中部署自主智能体时,需要具备完善的治理、隔离和控制能力。OpenShell 定义了智能体如何访问数据、调用工具以及在策略边界内运行,为安全、全天候运行的 AI 系统提供了架构基础。
自进化智能体在自主完成任务的同时,需要专用计算资源来构建工具和软件。DGX Spark 和 DGX Station 是运行 NemoClaw 的理想环境,可用于在本地利用 OpenClaw 构建和验证智能体,随后再扩展至数据中心 AI 工厂。
DGX Spark:适用于企业团队的可扩展 AI
如果说 DGX Station 是功能强大的桌面 AI 系统,那么 DGX Spark 则为企业各职能的团队提供可扩展的 AI 基础设施。
DGX Spark 具有大容量本地内存、强劲性能以及与 NemoClaw 的集成,是开发和部署自主智能体的理想选择。
DGX Spark 现已支持将多达四台系统集群化为统一的配置,创建具有线性性能扩展的紧凑型“桌面数据中心”,而无需面对传统机架部署的复杂性。
即将为 DGX Spark 发布的软件版本预计将进一步增强编排和可管理性,实现更快的迭代和从原型到生产的更平滑过渡。
DGX Spark 支持最新 AI 模型,包括 NVIDIA Nemotron 3 和领先的开放模型,确保开发者能在现代化、持续演进的 AI 软件堆栈上进行构建。
各行各业的组织正在将 DGX Spark 从评估环境转向积极的企业部署。金融机构正在加速风险建模。医疗健康研究人员正在缩短研发周期。能源公司正不断优化运营。媒体和电信团队正在构建实时内容和通信工作流。
DGX Station:桌面上的数据中心级 AI
NVIDIA DGX Station 是功能强大的桌面超级计算机,已为长思考与自主思考的全新阶段做好了准备。
DGX Station 搭载 NVIDIA Grace Blackwell Ultra 台式机超级芯片,提供 748GB 的一致性内存和高达 20 petaflops 的 AI 计算性能。它通过 NVIDIA NVLink-C2C 将一个 72 核 NVIDIA Grace CPU 和 NVIDIA Blackwell Ultra GPU 连接起来,构建了一个专为前沿 AI 工作负载打造的统一高带宽架构。
它使开发者能够在桌面运行高达一万亿参数的开放模型,并开发具有长期思考能力的自主智能体。
DGX Station 可作为个人 AI 超级计算机或团队共享的按需计算节点。它支持隔离配置,非常适合受监管的行业和主权环境。本地开发的应用无需重新架构,即可无缝迁移到数据中心或云端的 NVIDIA Grace Blackwell Ultra 机架级系统。
行业领导者已经开始利用 DGX Station 来加速现实世界的创新,Snowflake 正在使用 DGX Station 在本地测试其开源 Arctic 训练框架;EPRI 正在使用和测试 DGX Station 以推进 AI 驱动的天气预报,从而提高电网可靠性;Medivis 正在将视觉语言模型与 DGX Station 集成到手术工作流中;成均馆大学正在使用该系统来加速蛋白质结构分析;微软研究院和康奈尔大学正在利用 DGX Station 大规模开展 AI 实践培训;Respo.Vision、WSP 和 1X 正在部署用于高级体育分析、合成数据训练、自主智能体和人形机器人的 AI。
统一架构:从桌面到 AI 工厂
DGX Station 和 DGX Spark 预配置 NVIDIA AI 软件堆栈,使开发者能够使用熟悉的工具,在本地开发和大型基础设施之间无缝切换。
开发者可以在 DGX Station 上运行和微调先进的模型,包括 OpenAI [gpt-oss-120b]、Google Gemma 3、Qwen3、Kimi K2.5、Mistral Large 3、DeepSeek V3.2 和 NVIDIA Nemotron,并利用来自各种熟悉工具和平台, 如 1x ,Aible AI,Anaconda、Docker、红帽、JetBrains、Docker、Ollama、llama.cpp、ComfyUI、LM Studio、Llm.c、Weights and Biases (由 CoreWeave 收购)、Odyssey、Roboflow、VLLM、SGLang、Unsloth、Learning Machine、Quali、Lightning AI 等。
通过将芯片、系统、网络和软件整合为统一的架构中,NVIDIA 使企业能够实现“一次构建,随处扩展”——从桌面 DGX Station 到多节点 DGX Spark 集群,再到完整的 AI 工厂,均能够部署。
如需了解有关 DGX Spark 的更多信息,敬请关注 NVIDIA GTC 大会。欢迎参加有关可扩展自主智能体和 AI 基础设施的会议,在展厅中观看支持 NemoClaw 的 AI 智能体和多节点 Spark 演示,或访问 nvidia.cn/dgx-spark 获取部署指南和测试版资源。
查看有关软件产品信息的通知。
2026 年 3 月 16 日🔗
2026 年 3 月 16 日🔗
NVIDIA RTX PRO Blackwell 服务器版将通用加速从数据中心扩展到边缘端

NVIDIA RTX PRO 4500 Blackwell 服务器版为全球广泛的企业数据中心和边缘计算平台带来了 GPU 加速能力,与传统 CPU 服务器相比,视觉 AI 应用性能提升 100 倍,向量数据库性能提升高达 50 倍,实现了惊人的性能飞跃。
面向企业数据中心的节能性能
对于希望优化性能、效率和成本的企业,RTX PRO 4500 Blackwell 在紧凑的 165 瓦单插槽规格中提供了突破性能力。第五代 Tensor Core、第四代 RTX 技术和完全集成的媒体管线使其成为数据处理、视觉 AI、小型语言模型 (SLM) 推理、视频处理和视觉计算的理想平台。
它还计划在即将发布的 vGPU 20.0 版本中支持虚拟工作站,以及用于基于硬件分区的 NVIDIA 多实例 GPU 技术。
其他亮点包括:
- SLM AI 推理方面,相比 NVIDIA L4 GPU,运行 NVIDIA Nemotron Nano 9B 模型性能提升高达 10 倍。
- NVIDIA cuDF 加速的 Apache Spark 在处理 10TB 数据时,相比 CPU,将查询性能提升至原来的 5 倍,总拥有成本改善 10 倍。
- 在视觉 AI 方面,相比 NVIDIA L4 GPU,结合 NVIDIA Metropolis 平台运行 NVIDIA Cosmos Reason 2 模型进行视频摘要生成时,其性能最高可提升 4 倍。
行业领导者的采用情况
IT 服务、生命科学和电信等多个领域的领导者正在采用 NVIDIA RTX PRO 4500 Blackwell GPU 来支持 AI 和视觉计算工作负载。
NTT DATA 正在加速客户从边缘位置捕获的视频中获取安全、AI 驱动的数据洞察。在生物技术领域,Pacific Biosciences 计划将 RTX PRO 4500 Blackwell 集成到其测序平台中,以推动基因组分析的突破。诺基亚将在其 AI-RAN 基站中部署 RTX PRO 4500 Blackwell,为边缘 AI 智能体创建一个连接数十亿台设备的分布式计算网络。
全面的生态系统支持
采用 RTX PRO 4500 Blackwell 的企业将受益于广泛的软件生态系统支持。其中包括来自博通、Canonical、红帽、Nutanix 和 SUSE 的 AI 基础设施软件来自 Databricks 和 Snowflake 的数据平台;如 Dataiku、DataRobot 和 Ray on Anyscale 等 AI 平台;Cisco AI Defense 等安全软件;以及 Ambient AI、BriefCam 和 Ipsotek (Eviden 旗下公司) 等视觉 AI 与分析解决方案。
搭载 RTX PRO 4500 Blackwell 服务器版 GPU 的 NVIDIA RTX PRO 服务器也作为更新的一部分,NVIDIA Enterprise AI Factory 的验证设计和 NVIDIA AI 数据平台,这是一款用于构建面向企业代理式 AI 的现代存储系统的可定制参考设计。
将 RTX PRO 4500 Blackwell 集成到其 AI 数据平台中的存储合作伙伴包括:Cloudian、DDN、戴尔科技、Everpure、Hammerspace、Hitachi Vantara、IBM、NetApp、Nutanix、VAST Data 和 WEKA。
查看有关软件产品信息的通知。
2026 年 3 月 16 日🔗
NVIDIA 合作伙伴推出基于 Blackwell 架构的全新 NVIDIA RTX PRO 工作站

在 GTC 大会上,NVIDIA 合作伙伴发布了新一代 AI 就绪型工作站,将 NVIDIA RTX PRO Blackwell GPU 与 Intel Xeon 600 工作站处理器相结合。这些全新设计可满足从日常 AI 探索到要求严苛的 3D 设计和仿真等各种工作流。
联想正在扩展其 ThinkPad P 系列移动工作站,包括 ThinkPad P14s i Gen 7、ThinkPad P16s Gen 5 AMD、ThinkPad P16s I Gen 5 和 ThinkPad P1 Gen 9,以及配备了功能强大的全新 ThinkStation P5 Gen 2 的 ThinkStation 系列,该机型可配置多达两个 RTX PRO Blackwell Max-Q 工作站版 GPU。
戴尔正在推出现代化的 Dell Pro Precision 产品组合,包括 Dell Pro Precision 5 和 7 系列移动工作站以及 Dell Pro Precision 9 T2、T4 和 T6 台式工作站。
惠普计划对 HP Z 台式工作站进行前瞻性设计,以支持未来各代 NVIDIA GPU。可在 3 月 24 日的 HP Imagine 大会上了解更多信息。
新一代工作站为企业更新设备提供了更大的灵活性,企业可以根据自己的需求,优先考虑移动性、桌面性能或最大扩展性。搭载最新驱动程序的 RTX PRO Blackwell GPU 可提供首日模型就绪能力,包括对 NVIDIA Nemotron 开放模型和关键社区模型的支持,以便团队可以立即开始试验和部署 AI 工作负载。
Ollama、SGLang 和 LM Studio 等软件供应商提供针对 RTX PRO 优化的模型和工具,使开发者和创作者能够使用熟悉的工作流直接在这些新工作站上运行高级 AI 工作负载。
借助 NVIDIA NemoClaw 在本地保护代理式 AI 工作流
随着 AI 从简单的提示转向代理式 AI(长期运行的推理、规划和行动系统),开发者需要安全的基础设施来构建全天候 AI 助手。这些新工作站为 NVIDIA NemoClaw 开源栈提供了理想的桌面环境,该软件栈正是专为安全开发和部署自主长期运行的智能体而设计的。
利用 RTX PRO Blackwell 工作站版以及 RTX PRO Blackwell Max-Q 工作站版 GPU 高达 4000 TOPS 的本地 AI 计算能力和 96GB 的 GPU 显存,NemoClaw 简化了 OpenClaw 助手的安全运行。作为 NVIDIA Agent Toolkit 的一部分,它安装了 NVIDIA OpenShell 运行时,这是一个用于运行自主智能体和 NVIDIA Nemotron 等开源模型的安全环境。这为企业提供了完全在本地处理复杂业务任务所需的治理、控制和隐私保护。
在 GTC 上,您可以在 NVIDIA 展台和合作伙伴展台 (戴尔 721、惠普 1931 和联想 431) 了解详情并观看这些 RTX PRO 工作站的实际运行情况。
研究与开源🔗
2026 年 3 月 16 日🔗
NVIDIA CEO 黄仁勋在 GTC 大会上集结 AI 开放模型先锋
Mistral、Perplexity、Cursor、Thinking Machines Lab 等公司的首席执行官与黄仁勋一起登上舞台,共同勾勒了开放前沿时代的未来。

NVIDIA 创始人兼首席执行官黄仁勋表示,今年,开放 AI 的投资回报问题不再是理论问题,答案已经开始显现。
黄仁勋在周三的 GTC 大会上邀请了 11 位开放模型生态系统领导者,不是为了辩论开放与闭源创新,而是为了探讨未来趋势。
这场时长 90 分钟的会议由 LangChain、Cursor、Reflection AI、Perplexity、Thinking Machines Lab、Mistral、OpenEvidence 和 Black Forest Labs 的首席执行官,以及 AI2 自然语言处理高级总监 Hanna Hajishirzi 和 AMP PBC 创始人 Anjney Midha 共同参与,会议分为两个连续的圆桌讨论。
黄仁勋一开场就提出了一个新的视角。
他对现场观众表示:“专有与开放不是对立的概念。可以既是专有,又是开放。”
第一场圆桌讨论重点关注开放模型生态系统的演变。参与者包括 LangChain 的 Harrison Chase、Perplexity 的 Aravind Srinivas、Cursor 的 Michael Truell、Reflection AI 的 Misha Laskin 以及 Thinking Machines Lab 的 Mira Murati。

Truell 认为,业界正在见证第三类公司的崛起,既不是纯粹的基础模型实验室,也不是纯粹的应用构建者,而是介于两者之间的公司:这类公司“在 API 层面充分利用市场提供的最佳资源,在模型前沿领域做出了卓越贡献,同时将所有这些都整合到垂直领域带来最佳产品”。
由此诞生了新型 AI 公司,将模型、系统和产品集成到单一堆栈中。
对话不断回到智能体话题上。
Srinivas 将 Perplexity 的愿景描述为构建“AI 能够完成的所有任务的编排系统”,其中模型是工具,而系统负责指挥。
他表示:“我们终于能够在模型之上进行抽象操作。这很令人兴奋。”
Laskin 将单一模型描述为“没有身体的大脑”。他认为,Open Claw 的发布为 AI 提供了与文件系统交互并执行自主工作所需的“肢体”。
Chase 指出转变正在悄然发生。他表示:“现在有一个新术语叫‘驾驭工程’ (Harness Engineering),指的是模型周边的整套体系:如何连接到系统、使用哪些子智能体以及何时调用哪些工具。”
Murati 又把对话拉回到了更长的弧线上。她表示:“我们正处于一个指数级的发展阶段,一切都被极度压缩了,而仅靠大型实验室是无法完成所有工作的。”
开放访问 (包括模型、基础设施和后训练) 以封闭模型世界无法实现的方式加速了研究。
黄仁勋不断重复一个简单的理念:AI 不是模型,而是系统。
他认为,编程仅仅只是个开始。
他说:“编程不仅仅是软件工程。它是对业务流程的描述和编码,几乎涵盖了所有工作。”

从系统到利害关系
第二场圆桌讨论汇聚了 Mistral 的 Arthur Mensch、OpenEvidence 的 Daniel Nadler、AI2 的 Hajishirzi、Black Forest Labs 的 Robin Rombach 和 AMP PBC 的 Midha。
此时,对话从系统转向了更深层的现实情况与行业影响。
对此,黄仁勋则开门见山地点明了核心议题。
他说:“过去三年来,所有问题都是关于 AI 的投资回报率。我认为现在……我们将看到真正商业价值爆发的拐点。”
Nadler 认为医疗领域是代理式系统的试验场。
多步骤、重复、可预测的工作流 (事先授权函、保险申诉) 正是智能体擅长的领域。
他表示:“你可以想象,当医生还在睡觉时,智能体会对保险拒保提出上诉,最终为患者争取到可能至关重要甚至可以挽救生命的治疗。”
Mensch 认为开放模型具有两大优势:管理和定制。
企业需要严格管理其智能体可以访问和执行的内容,并使其适配那些通用模型永远无法完全覆盖的现实业务系统。
Midha 从产业层面描述了其中的利害关系。
开放模型需要开放的基础设施:一个允许任何规模的公司进行扩展的计算网格。其含义很明确:可见且可控的系统比封闭的系统更值得信任。
Midha 表示:“归根结底,如果你想让这些智能体融入我们生活中最重要的部分,你就必须信任它们。而开放模型是建立系统信任的快速方式之一。”
换句话说,前沿不再由少数实验室定义,而是取决于在这些模型之上构建、部署和实际落地的应用。
观看完整会议并开始使用 NVIDIA Nemotron开放模型。
2026 年 3 月 19 日🔗
当 AI 遇见光速:NVIDIA Bill Dally 与 Google Jeff Dean 共话未来


在 GTC 会场,观众座无虚席,两位计算领域最具影响力的领导人物,NVIDIA 首席科学家 Bill Dally,以及 Google DeepMind 与 Google Research 首席科学家 Jeff Dean 登台对话。他们的工作深刻塑造了大规模机器学习的发展轨迹。
这场对话与其说是传统座谈,不如说是一场深度学习的“即兴演奏会”,两位深入探讨了 AI 模型的演进方向,以及为何硬件架构如今已与 AI 的进步密不可分。
Dean 开场时回顾了模型能力的快速跃迁,尤其在如“数学和编程”等具备“可验证奖励”的领域。曾经令模型束手无策的任务,如今已能可靠地执行;基于智能体的工作流甚至能在数小时乃至数天内几乎无需人工干预的情况下自主运行。他强调,这一转变正在重塑 AI 系统的本质,使其从被动响应提示的工具,转变为“在后台持续运作的智能体”。
对此,Dally 表示,这种演进将延迟问题推至聚光灯下。推理速度成为智能体在大规模环境中推理、规划与迭代的首要设计约束。他解释道,当前大部分延迟并非来自计算本身,而是源于通信。每一层之间的数据传递、每一次片外访问、每比特在导线上的移动,都会带来时间与能耗成本。NVIDIA 的应对策略是推动架构向 Dally 所称的“光速”设计迈进:最大限度减少路由成本、消除排队等待,并缩短数据必须传输的物理距离。
在讨论能效时,这一“不要移动数据”的原则被反复提及。一次乘加运算可能仅耗几飞焦耳(极小的能量单位),但从外部存储器读取数据的能耗却可能高出数千倍。Dally 介绍了利用 SRAM 的局部性并探索堆叠式 DRAM 技术,通过将计算单元紧邻内存部署,从根本上改善这一能耗失衡。其目标不仅是降低能耗,更是在相同功耗下实现更高性能。
讨论还延伸到利用 AI 设计运行 AI 的芯片。Dally 举例说,如今强化学习系统能够在一夜之间生成标准单元库,即预设计、预验证且完整表征的基础逻辑模块集合;而基于 NVIDIA 设计历史训练的内部大语言模型,正帮助初级工程师掌握数十年的架构知识。这些系统并非取代人类设计师,而是增强他们的能力,压缩开发周期,并拓展值得探索的创新空间。
展望未来,两位演讲者不约而同地聚焦于同一个关键词:协同设计。突破性的进展将来自机器学习研究人员与系统架构师之间的紧密反馈循环。正如 Dean 所言,有时你在硅片上加入一个小型实验性功能,就可能带来巨大回报,硬件性能可因此实现“10 到 20 倍”的提升。
本场对话最终回归人本价值。教育、医疗与科学发现被一致视为 AI 能产生深远积极影响的领域,尤其是当系统变得个性化、具备上下文理解并持续学习的情况下。Dean 表示,“我认为 AI 在医疗领域的应用将极具变革性”。
如果台上这两位行业领导者所畅想的未来成真,那将不只是更快的模型运行在更好的硬件上,而将开启一个一个智能、能效与规模协同演进的全新计算时代。
AI 研究者探讨推理、仿真与机器人领域的最新进展
另一场备受期待的圆桌讨论同样座无虚席,该环节由《Two Minute Papers》创作者 Károly Zsolnai-Fehér 主持,四位开创性 AI 研究者参与。
随后展开的是一场快节奏的巡览,展示了塑造下一代 AI 的突破性进展,从具备推理能力的语言模型,到生成式仿真,再到零样本机器人。


NVIDIA AI 研究高级总监 Yejin Choi 率先发言,她介绍了一种将强化学习直接注入预训练的新训练方法。模型不再只是简单预测下一个 Token,而是被鼓励自主思考,在生成答案前探索更多可能的推理路径。她表示,这标志着向“探索式学习时代”的转变,模型能够更早、更有效地学会推理。
NVIDIA 辅助驾驶研究高级总监 Marco Pavone 随后介绍了 NVIDIA Alpamayo 的最新进展,这个系列专为辅助驾驶开发的开源 AI 模型、仿真工具和数据集所打造。最新发布的 Alpamayo 1.5 推理型视觉-语言-动作模型新增了基于文本提示的导航引导功能和全新的后训练对齐工具,强化了模型推理与动作之间的联系,让开发者能够“根据自己的数据集定制模型”。
随后,讨论转向仿真领域。NVIDIA AI 研究副总裁、多伦多 AI 实验室负责人 Sanja Fidler 展示了神经重建与生成式仿真如何取代人工构建的环境。Fidler表示,“我们已进入生成式仿真的时代。”
其团队推出的全新 AlpaDreams 系统能够实时生成多摄像头、具备物理感知的场景,使开发者能够进行交互式测试策略。她表示:“AlpaDreams 本质上能实时对多个摄像头进行仿真,并对策略做出即时响应。”
最后,NVIDIA 高级机器人研究经理 Yashraj Narang 展示了神经仿真器(如 Neural Robot Dynamics)如何在完全仿真的环境中教授机器人复杂的物理技能,从齿轮组装到线缆布线,再直接迁移到现实世界。他表示,“我们可以在实时状态下并行运行数十万个这样的仿真环境。”
整场对话勾勒出 AI 的下一个前沿:会推理的模型、能生成世界的仿真器,以及先在想象中学习再在现实中行动的机器人。
观看完整会议并了解更多关于 NVIDIA 研究中心的信息。
2026 年 3 月 16 日🔗
CUDA 二十周年:致敬加速计算时代的奠基者
2006 年,一项大胆的并行计算构想悄然启程。如今,它已成为现代科学与 AI 发展的基础脉动。
NVIDIA 在 GTC 大会庆祝 CUDA 发明二十周年——这项成就凝聚了全球超过 600 万开发者在计算栈各层持续创新的成果。如今 CUDA 依然是连接首批编写内核的先驱与下一波部署万亿参数 AI 模型的建设者的跨时代的桥梁。
在 GTC,由 NVIDIA CUDA 架构师 Stephen Jones 主持的专题会议上,来自 Jump Trading、Meta Superintelligence Labs 和 NVIDIA 的研究人员与工程师共同回顾了 CUDA 二十年来的创新历程,探讨它如何帮助开发者攻克全球最复杂的难题,以及 NVIDIA DGX Spark 桌面 AI 超级计算机等系统将如何赋能下一代 CUDA 开发者。
参会嘉宾分享了关于 CUDA 的早期记忆。Meta Superintelligence Labs 软件工程师 Paulius Micikevicius 表示:“那时候没有人愿意使用 GPU,我们不得不去恳求别人考虑使用 GPU。”
当时,NVIDIA 现任资深杰出研究科学家兼高级研究总监、时任伊利诺伊大学厄巴纳-香槟分校教授 Wen-Mei Hwu,决定带领一群研究生在两个月内搭建一个由 200 块 GPU 组成的系统。
Hwu 表示:“几周后,200 块 GPU 主板、电源和所有配件都到了,但没有机箱。我们只好给每块主板做了木制框架……随后我们运行了 Green500 基准测试,拿到了第三名。那一刻我意识到 GPU 蕴藏着巨大的能效潜力。”
随着加速计算规模已转向机架级扩展系统和 AI 工厂,参会嘉宾认为,像 DGX Spark 这样的桌面 AI 系统将为原型设计和早期开发提供全新路径。
NVIDIA 杰出 DevTech 工程师 Kate Clark 表示:“关键在于你要具备进行初步探索的能力,并且有一台桌面计算机或者笔记本电脑这样的便携设备。我认为这一趋势在短期内不会改变,CUDA 将无处不在。”
2026 年 3 月 16 日🔗
NVIDIA cuDF 和 cuVS 获全球领先数据平台采用,助力现代企业数据处理
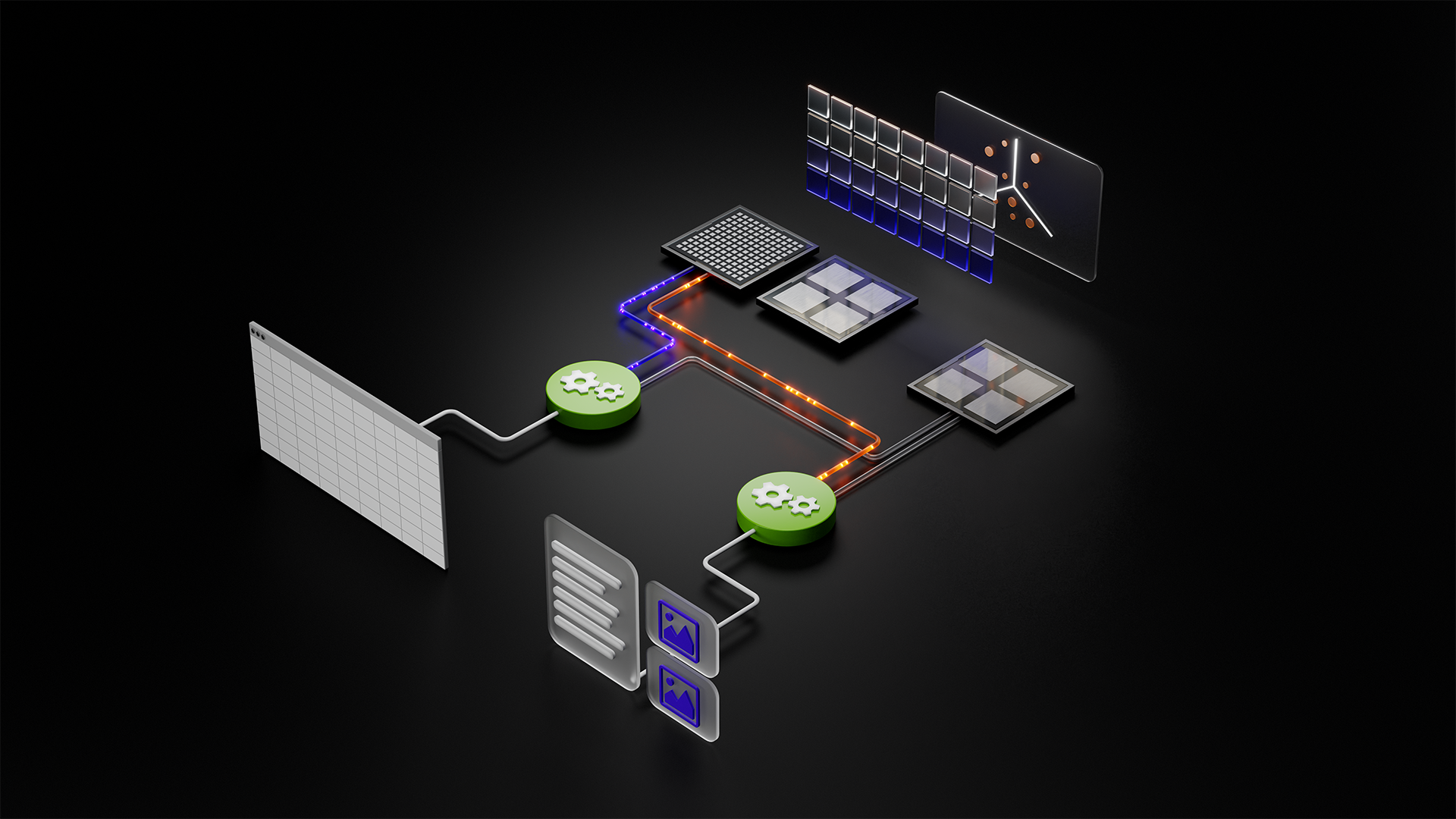
企业每年产生数百 ZB (Zettabyte) 的数据,并在争相将这些信息转化为洞察。NVIDIA cuDF 和 cuVS 作为基于 NVIDIA CUDA-X 构建的加速数据库,正在被各行业的数据平台所应用,带来至高 5 倍性能提升的同时,可降低结构化和非结构化数据处理成本。
这些库已与全球广泛使用的开源数据引擎集成 (开发者月度下载量超过 2 亿次),并在企业数据平台、数据库和数据湖中得到广泛应用。这有助于企业组织加速创新、开发更准确的模型,并在处理更多数据的同时有效控制成本。
针对结构化数据,NVIDIA cuDF 可加速 Apache Spark、Presto、DuckDB、Polars 和 Velox 等开源数据处理引擎。与仅使用 CPU 的部署方式相比,处理速度可提升高达 5 倍。
对于非结构化数据 (目前占企业数据总量的 80%,并且正迅速增长),NVIDIA cuVS 可加速 FAISS、Amazon OpenSearch Service 和 Milvus 等领先引擎,有助于智能体和应用在极短的时间内从海量文本、图像和视频中提取上下文、事实和建议。
为企业数据处理平台提供支持
谷歌云集成了 NVIDIA cuDF,以加速 Dataproc 中的 Apache Spark。此外 cuDF 可轻松在 Google Kubernetes Engine (GKE) 中使用,将大规模 ETL 任务的处理时间从数小时缩短至数秒,同时降低计算成本。
Snap 为超过 9.46 亿活跃用户服务,基于 GKE 的 NVIDIA cuDF 将日常数据处理成本降低了 76%,能够在 3 小时内分析 10 PB 数据,节省数百万美元。
Snap 首席信息官 Saral Jain 表示:“与 NVIDIA 和谷歌云的合作帮助我们更快地为全球超过 10 亿 Snapchat 用户提供创新服务。通过降低数据处理成本,并实现对 PB 级数据的跨规模实验,我们能够更快且更高效地提供 AI 驱动的体验。”
IBM watsonx.data 是一个混合型开放数据平台,包括像 Apache Spark 和 Presto 引擎这样的开源分析引擎,用于结构化数据处理,此外还包括基于 OpenSearch 的向量引擎。在与雀巢的 Order-to-Cash 市场早期实验中,结合 NVIDIA cuDF 加速的 watsonx.data 工作负载运行速度提升了五倍,同时节省了 83% 的成本。
雀巢首席信息和数字官 Chris Wright 表示:“对于一家为数十亿人服务的公司来说,数据是支撑我们全球运营决策的基石。通过与 IBM 和 NVIDIA 合作,我们开展了一项有针对性的概念验证,成功实现了在几分钟内刷新全球运营数据,同时节省成本。我们现在的重点是将这一能力转化为切实的业务影响,进一步提升制造和仓储等领域的决策速度,并将这些能力在整个企业范围内扩展。”
基于 NVIDIA 技术的 Dell AI Data Platform 提供加速数据引擎,使企业能够快速、安全地利用 AI 就绪型数据启动其 Dell AI Factory。该平台采用基于 Apache Spark 的处理引擎,并借助 NVIDIA cuDF 加速,实现高达 3 倍的性能提升,并配备 NVIDIA cuVS 加速的企业级向量数据库,在向量索引处理方面相较于 CPU 至高提升 12 倍吞吐量。
戴尔科技集团董事长兼首席执行官 Michael Dell 表示:“专为代理式 AI 打造的 Dell AI Data Platform 搭载 NVIDIA 技术,采用加速数据处理引擎,可在数小时内 (而非数天内) 将多模态数据转换为 AI 就绪数据。”
Oracle 宣布,Oracle Private AI Services Container 使用 NVIDIA cuVS 大幅加速 Oracle AI Database 中的向量索引创建,帮助企业利用最新信息加速 AI 决策。
Oracle 首席执行官 Clay Magouyrk 表示:“企业 AI 正从实验阶段转向生产阶段。Oracle AI Database 结合 NVIDIA 技术,可在数分钟内提供 AI 就绪数据,使得以前无法实现的应用成为现实。”
NVIDIA cuDF 和 cuVS 获得了领先企业数据平台的支持,包括 EDB Postgres AI、NetApp、Snowflake、Starburst 和 VAST Data,为 AI 驱动的数据处理的未来奠定基础。
云🔗
2026 年 3 月 16 日🔗
NVIDIA 与亚马逊云科技扩展代理式 AI 时代计算能力
NVIDIA 与亚马逊旗下的亚马逊云科技 (AWS) 宣布扩展合作关系,部署 NVIDIA AI 基础设施,以支持代理式 AI 时代各行各业不断增长的计算需求。AWS 将部署包括 LPU 和超过 100 万个 NVIDIA GPU 在内的 NVIDIA AI 基础设施。
这一合作使得 NVIDIA AI 基础设施在 AWS 的计算产品组合中得到大规模部署。扩展的基础设施覆盖整个 NVIDIA AI 计算堆栈,包括 NVIDIA Blackwell 以及 Rubin GPU 架构、适用于企业 AI 工作负载的 NVIDIA RTX PRO Blackwell 服务器版 GPU,以及适用于超低延迟推理的 NVIDIA Groq 3 LPU。AWS 和 NVIDIA 还在 Spectrum 网络和其他基础设施领域展开合作。
AWS 将在今年于全球云区域部署超过 100 万个 NVIDIA GPU。此次部署基于 NVIDIA 加速计算和 AWS 的全球云平台,将赋能 AWS AI 工厂作为统一的计算引擎运行,为训练和部署下一代 AI 系统提供无与伦比的效率、性能和安全性。
通过将 NVIDIA 的加速计算与 AWS 的先进云服务和基础设施技术相结合,两家公司旨在为企业、初创公司和研究机构提供构建和扩展代理式 AI 系统所需的基础设施,这些系统能够在复杂的工作流中自主推理、规划和行动。双方将共同推动全球 AI 基础设施在速度、规模和可靠性方面实现重大飞跃。
2026 年 3 月 16 日🔗
NVIDIA 与亚马逊云科技合作扩展 GPU 加速解决方案的应用
NVIDIA 和亚马逊云科技 (AWS) 扩展双方合作,增强在 AWS 平台上的由 NVIDIA 驱动的数据处理能力,并增加对 NVIDIA Nemotron 开放模型系列的支持。
自 2010 年以来,NVIDIA 和 AWS 一直共同合作,提供大规模、经济高效且灵活的 GPU 加速解决方案,涵盖基础设施、软件和服务,以全栈套件加速在生产环境中构建和部署 AI 的解决方案落地时间。
在 AWS 上借助 NVIDIA RTX PRO 加速数据处理
全新 NVIDIA RTX PRO Blackwell 服务器版 GPU 即将通过 Amazon EC2 的新型加速计算服务在 AWS 上推出,在云端提供 NVIDIA Blackwell 的性能。AWS 是首家宣布支持全新 NVIDIA RTX PRO 的云服务提供商。这些 Amazon EC2 实例与 Amazon EMR 配合使用,非常适合数据处理工作负载。全新 Amazon EC2 实例基于 AWS Nitro 系统构建,提供数据处理工作负载在生产环境中所需的更高安全性、稳定性和资源效率。
NVIDIA Nemotron 助力 Salesforce Agentforce
NVIDIA Nemotron Nano 3 模型现已作为 Amazon Bedrock 上的可用模型,面向 Salesforce Agentforce 开放,将 Agentforce 扩展至新的高吞吐量应用场景,例如批处理或高并发 B2C 应用。根据 Salesforce 的 CRM 智能体基准测试 (Agentic Benchmark for CRM),Nemotron 3 Nano 是用于总结和生成用例中性价比极高的模型。
适用于 NVIDIA Nemotron 模型的强化微调功能即将在 Amazon Bedrock 上推出
开发者很快就能在 Amazon Bedrock 上直接对 NVIDIA Nemotron 模型进行强化微调 (Reinforcement Fine-TuningRTF)。对于需要将模型行为调整到特定领域 (无论是法律、医疗、金融还是其他专业领域) 的团队来说,这一点非常重要。强化微调使开发者能够塑造模型的推理和响应方式,而不仅仅是模型所知道的内容。Nemotron Nano 3 将很快支持 RFT,为 AWS 客户提供这些功能。
查阅相关软件产品信息说明。
2026 年 3 月 16 日🔗
NVIDIA 开放模型与 Microsoft Foundry 和 Azure Local 相结合,助力代理式 AI、主权 AI 和物理 AI 系统的发展
在 GTC 大会上,微软宣布了其代理式和物理 AI 系统统一平台的更新,加速从实验到生产落地的进程。将 Microsoft Foundry 与 NVIDIA 开放模型和加速计算相结合,创建了统一的软件栈,在满足严格的数据主权要求的同时简化定制。
为了支持这些推理密集型工作负载,微软已快速将最新的 NVIDIA 加速计算平台集成到其液冷式 Azure 数据中心。这建立在微软大规模基础设施扩展的基础上——不到一年, 微软已在全球数据中心部署了数十万个液冷式 NVIDIA Grace Blackwell GPU。Azure 也是率先启用全新 NVIDIA Vera Rubin NVL72 机架级扩展系统的首个超大规模云服务提供商,并将在未来几个月内全球上线。
在 Microsoft Foundry 上使用 NVIDIA Nemotron 构建专业化的企业智能体
开发者现在可以在 Microsoft Foundry 中直接使用 NVIDIA Nemotron 开放模型构建和部署专用智能体。
在智能体平台层,Microsoft Foundry Agent Service 现已全面上线,可支持大规模构建、部署和运行 AI 智能体。新功能包括增强了智能体的可观测性和语音功能,使客户能够在以安全性和治理为核心的平台上,快速从实验验证转向生产部署。
借助由 NVIDIA Blackwell 和 Rubin 平台加速的 Azure 计算,团队可以在 Foundry 的模型即平台 (Model-as-a-Platform) 环境中轻松访问这些模型。该系列将扩展到最新的 Nemotron 3 模型推理、语音和视觉系列,包括 Nemotron 3 Super 以及 AI 安全护栏模型。Nemotron 模型还将在今年晚些时候作为托管应用编程接口 (API) 服务登陆 Azure。
微软安全 (Microsoft Security) 也正基于 NVIDIA Nemotron 和 NVIDIA NemoClaw 进行研发,以提高智能体的安全性、可靠性和效率。
微软安全 NEXT AI 团队副总裁 Alexander Stojanovic 表示:“在微软,信任和安全对于负责任地采用代理式 AI 至关重要。这就是为什么我们一直在与 NVIDIA 合作开展对抗性学习,包括 Nemotron 和 OpenShell,以便通过实时、自适应的运行时保护更好地确保行业和企业安全应用。早期结果显示,在发现和缓解基于 AI 的异常行为方面,其性能提升了 160 倍。”
在 Azure Local 上加速主权 AI
对于受到监督管理的行业和政府客户,Azure Local 正在扩展主权 AI 功能,以便客户在可控的环境中运行。Azure Local 目前支持 NVIDIA RTX PRO 6000 Blackwell 服务器版 GPU,即将支持 NVIDIA RTX PRO 4500 Blackwell 服务器版 GPU ,预计将于今年晚些时候支持 NVIDIA Rubin 平台。结合 Foundry Local 服务,客户可以在本地运行模型,同时保持对数据、推理和治理的完全管理。
助力 Azure 上的物理 AI
为了加速机器人和物理 AI 的发展,NVIDIA Blueprint 和开放基础模型,包括 NVIDIA Cosmos 世界模型和用于智能汽车开发的 NVIDIA Alpamayo 模型,现已上线 GitHub 和 Foundry。如需了解详情,请访问 NVIDIA GTC 发布的物理 AI 相关信息。
详细了解该战略合作,请访问微软官方博客。
2026 年 3 月 17 日🔗
Oracle 和 NVIDIA 借助 NVIDIA cuVS 携手加速向量搜索和企业数据处理
Oracle 和 NVIDIA 正在与客户合作,将 GPU 加速的向量索引构建应用于实际工作负载。Oracle Private AI Services Container 初期支持 CPU 执行,现旨在支持 NVIDIA GPU 和 NVIDIA cuVS 开源库,用于向量搜索和索引生成。本公告基于在 Oracle AI World 2025 大会上推出的 Oracle AI Database 26ai 和 Oracle Private AI Services Container 基础之上发布。
使用 Oracle AI Database 26ai 管理海量非结构化和多模态数据资产的企业,现在可以将向量索引的创建任务转移至 NVIDIA 加速计算平台,从而显著缩短索引构建时间。
强化医疗工作流
早期医疗创新企业 Biofy 和 Sofya 是首批在 Oracle 数据库上探索 GPU 加速索引的公司,旨在实现更快、更准确的 AI 驱动的临床和分析用例。
作为一家 AI 医疗健康公司,Sofya 提供实时医学转录和结构化临床文档处理,已处理超过 100 万次临床接诊记录。该公司提供了一个实时平台,能够在与患者互动期间生成临床记录,并根据循证医学协议提出医学建议。这要求能够对海量医学数据集进行即时的、可检索的访问。
每年大约有 150 万篇新的医学文章发布,Sofya 必须确保其 AI 建议与最新的临床证据保持高度一致。Sofya 使用了一个包含约 5 亿个向量、总量超过 3TB 的美国医疗库数据集,此类向量索引原本需要数天时间来构建。通过 Oracle Private AI Services Container 和 NVIDIA cuVS 进行 GPU 加速索引构建,能够助力 Sofya 大幅加速这一过程。
医疗科技公司 Biofy 使用 AI 快速识别细菌感染,预测抗生素耐药性,并在数小时内 (而非数天) 推荐有针对性的治疗方案。该公司使用基于 NVIDIA GPU 的 Oracle Cloud Infrastructure 来扩展训练和推理,将基因组向量存储在配有 AI 向量搜索 (AI Vector Search) 功能的 Oracle Autonomous Database 中,从而实现低延迟、高性价比的查询。通过微调的 Llama 模型,Biofy 持续生成合成 DNA 序列,以领先于不断进化的细菌,科学家无需不断运行昂贵的湿实验室实验。cuVS 赋能 Biofy 加速创建向量搜索索引。
如需了解 GTC 上 Oracle 和 NVIDIA 发布的最新消息,包括基于 Vera Rubin 的全新 OCI 超级集群,请访问 Oracle 博客。
2026 年 3 月 17 日🔗
NVIDIA 云合作伙伴将全球 AI 工厂规模翻倍,推动主权 AI 发展

AI 工厂的增长势头强劲。
GTC 主题演讲中提到,NVIDIA 云合作伙伴 (NVIDIA Cloud PartnersNCP) 的 AI 工厂规模同比翻了一倍,推动了美国、澳大利亚、德国、印度尼西亚、印度等国家/地区的主权 AI。
NCP 目前已在全球 AI 工厂中累计部署超过 100 万个 NVIDIA GPU,相当于超过 17 亿瓦的 AI 容量。
这种计算能力足以在短短几周内完成对数十亿蛋白质结构和药物化合物分子相互作用的研究,或者每天仿真数百亿英里的驾驶里程,以便在超现实的 3D 物理引擎中训练辅助驾驶汽车。
自去年 GTC 大会以来,NCP 部署量已增长了 2 倍 (当时 NCP 已累计部署了 40 万个 NVIDIA GPU,也就是 550 兆瓦的 AI 容量),表明企业组织正在以前所未有的规模生成智能。而作为 NCP 计划的一部分,这些合作伙伴都已具备支持未来 NVIDIA AI 基础设施的能力。
以下是正在部署基于云的 AI 工厂的一些关键的 NCP,这些工厂将 NVIDIA 加速计算、网络和优化的 AI 软件结合在一起:
- 金融科技初创企业创新中心 TechQuartier 正在与沙盒即服务提供商 NayaOne 合作,在德国创建主权超强沙盒 (Supercharged Sandbox) 平台。NayaOne 在 Sovereign AI Factory Frankfurt 上运行,其利用 NVIDIA AI Enterprise 软件,并由 NCP Polarise 提供支持。
- Zadara 和 DDN 宣布建立战略合作伙伴关系,基于 NVIDIA 参考架构为多租户主权云和 AI 工厂提供高性能 AI 基础设施。双方将共同助力服务提供商、电信公司和企业快速、安全、高效地部署 NVIDIA 驱动的 AI 基础设施,同时实现对合规性、成本、租户隔离和性能服务水平协议的调控。
- 作为马来西亚的 NCP,AI 实验室 YTL 正在其 ILMU 系列大语言模型中使用 Nemotron 3 技术和数据,这些模型基于本地上下文数据进行训练,并在马来西亚部署。
- 由德国联邦经济和能源部资助的德国研究联盟 SOOFI 正在训练新的主权 AI 模型,作为主权开源基础模型计划 (Sovereign Open Source Foundation Models initiative) 的一部分,旨在加强欧洲 AI 主权,并为全新且广泛使用的 AI 应用奠定基础。SOOFI 正在使用 NVIDIA Nemotron 3 Nano 和 Super 以及德国电信的工业 AI 云来构建其基础模型,以提供自主、安全和高性能的环境,用于构建可信且可扩展的 AI 模型。
了解更多关于 NCP 计划的信息。
医疗🔗
2026 年 3 月 16 日🔗
NVIDIA 发布面向医疗机器人的开放物理 AI 模型
包括 CMR Surgical 和强生医疗科技在内的外科手术机器人领先企业,以及 PeritasAI 和 Proximie 等外科手术物理 AI 平台开发者,均已率先采用 NVIDIA 在 GTC 2026 大会上发布的医疗专用物理 AI 工具。

多年来,医疗领域的 AI 主要局限于屏幕之上,负责分析医学影像并观测患者预后。如今,随着 NVIDIA 推出首个专门面向医疗机器人领域的物理 AI 平台,AI 正跨越屏幕走向现实世界。
CMR Surgical、强生医疗科技、Moon Surgical 和 Rob Surgical 等外科手术机器人领导企业与创新企业正在采用 NVIDIA 专为医疗领域打造的物理 AI 工具,以加速合成数据生成、机器人策略评估和数字孪生创建等工作流。
PeritasAI 正集成这些技术,构建用于外科手术操作的物理 AI 平台,并通过整合机器人与多智能体智能,实现实时感知、协同和行动。物理 AI 平台开发者 Proximie 致力于开发视觉语言模型,为外科手术团队提供支持。
以下这些在 GTC 2026 上发布的工具,提供了开发者所需的强大且开放的基础设施,使开发者可借助新一代医疗机器人,重塑医疗服务模式。具体工具包括:
- Open-H:全球最大的医疗机器人数据集,由 30 余家合作伙伴共同构建,充分展示了现实世界中实际手术的多样性和复杂性。该数据集包含超过 700 小时的手术视频,助力开发先进通用机器人系统。
- Cosmos-H:基于 NVIDIA Cosmos、包括 Cosmos-H-Surgical 在内的开放模型系列,用于大规模生成特定领域基于物理的合成数据。该系列包含三个模型,能够根据提示、参考图像或视频以及配套的机器人运动学,生成外科手术视频,使开发者可以通过逼真的仿真环境来扩展真实数据集,并通过预测外科手术环境的未来状态来评估机器人策略。
- GR00T-H:基于 NVIDIA Isaac GR00T N 的视觉语言动作(VLA)模型。它能够处理描述临床任务的文本命令,并生成对应的运动命令,或称为动作 Token。该模型基于 Open-H 数据集训练,可用于训练和评估在医疗环境中执行复杂物理动作的机器人。
- Rheo:面向 AI 医疗机器人的开发框架 Isaac for Healthcare 中提供的一项开发者蓝图,使开发者能够创建物理精确的医院仿真环境。通过对临床工作流、医疗设备交互、人类动作和医院物流进行仿真,Rheo 可用于大规模、安全地开发和测试自动化策略。

外科手术机器人、医学影像和医院自动化领域的领军企业已开始采用 NVIDIA 面向医疗机器人打造的物理 AI 技术:
- CMR Surgical 为 Open-H 贡献了近 500 小时的手术视频,用于预训练 GR00T-H,并使用 Cosmos-H 生成物理精确的合成外科手术数据,对其全新的机器人策略进行评估。
- 强生医疗科技借助基于 Cosmos 的基础模型以及 Isaac for Healthcare 中的解剖仿真,生成并增强泌尿外科平台 MONARCH 的后训练工作流数据。
- PeritasAI 使用 Isaac for Healthcare 和 Rheo 训练其人形机器人和 VLA 模型,旨在将具身智能带入外科手术环境,并通过实时态势感知、无菌配合及智能管理仪器、植入物及手术室工作流程,为外科手术团队提供支持。这项工作与光轮智能以及 Advent Health Hospitals 共同合作完成。
- Proximie 借助 Cosmos-H 训练多模态视觉语言模型,并将手术室图像与术中视频相结合。这些模型可驱动实时 AI 智能体,以在整个外科手术过程中提供手术洞察和编排。
其他采用 NVIDIA 医疗机器人技术的企业还包括 Moon Surgical 和 Rob Surgical。
Open-H、Cosmos-H 和 GR00T-H 已在 GitHub 及 Hugging Face 上线,供开发者进行后训练,并对特定外科手术场景进行适应。这些工具可与 NVIDIA Isaac for Healthcare 及 Rheo blueprint 配合使用,为外科手术机器人的训练和评估提供仿真管线支持。
阅读 NVIDIA 技术博客,了解更多关于 Rheo blueprint 的信息。
2026 年 3 月 16 日🔗
NVIDIA、Google DeepMind、EMBL 联合发布全球最大蛋白质复合物数据集,加速 AI 驱动的生物学研究与药物研发

NVIDIA、Google DeepMind、欧洲分子生物学实验室下属欧洲生物信息学研究所(EMBL-EBI)以及首尔大学 Steinegger 实验室,对 AlphaFold 蛋白质结构数据库进行了大规模扩展,为可搜索数据库新增了 170 万个高置信度预测的蛋白质复合物,并提供约 3000 万个额外预测结构供批量下载。
这一新增数据集是同类中规模最大的,使该数据库成为一个能够在前所未有规模下开展蛋白质相互作用建模的综合资源平台。
Google DeepMind 的 AlphaFold-Multimer 模型为数据库提供了 AI 预测生成的蛋白质结构。同时,通过在 OpenFold 推理流程中集成了包括 NVIDIA TensorRT 和 cuEquivariance 在内的 NVIDIA 计算库,推理速度相较传统方法提升超过 100 倍。
该数据库提供这些预先计算的蛋白质结构形式作为研究假设,从而加速新药靶点发现和疾病机制研究中的实验验证过程。这大幅降低了科研门槛,尤其有助于那些缺乏先进超级计算资源的低资源环境研究人员开展相关研究。
该项目优先聚焦参考蛋白质组,即代表物种分类多样性的蛋白集合,以及世界卫生组织重点关注的病原体名单,以推动传染病研究。
对于制药行业而言,这些预测结构可作为强有力的初始假设,大幅加速后续湿实验进程,节省宝贵的时间与资源。
2026 年 3 月 18 日🔗
NVIDIA Nemotron 开放模型、NeMo 库和 AI 数据飞轮驱动下一代数字健康智能体
NVIDIA Nemotron 系列开放模型和 NVIDIA NeMo 库正在为临床医生、研究人员和开发者提供开放权重和方法,使他们能够在自有的基础设施上构建和部署定制化的数字健康智能体。
随着高分辨率影像、纵向患者资料等多模态医疗数据量的激增,医疗行业正面临传统模型难以应对的规模性挑战。高效率、低延迟的 Nemotron 开放模型提供了处理海量数据所需的专用工具,使研究人员能够摆脱对昂贵的封闭系统依赖,同时降低延迟和运营成本。
借助 NeMo,开发者可以针对通用 AI 模型常常忽略的医学术语对模型进行微调。此类效率提升已经直接反映在成本层面。在近期一项研究中,Heidi Health 报告称,通过将临床文档处理迁移到 Nemotron Speech 模型,其延迟降低了 75%,运营成本降低了 64%。
医疗公司已率先采用 Nemotron 来驱动其智能体解决方案。Hippocratic AI 正在使用 NeMo 来训练适用于临床对话的大型领域自适应模型。Sword Health 使用 NeMo 强化学习 对其 AI 驱动的心理健康支持模型进行微调。IQVIA 正依托其领域专业知识、专有数据以及对安全、负责任 AI 的承诺,与 NVIDIA 合作开发面向生命科学的 AI 智能体。OpenEvidence 正在部署 Nemotron 来构建能够整合医学知识的智能体。Verily 计划集成 Nemotron,为其 AI 助手 Violet 提供支持,协助用户解读健康数据并理解症状。
通过将这些开放模型融入医疗服务体系,NVIDIA 正在为患者护理更个性化、数据更加安全,并且效率呈指数级提升的未来奠定基础。
NVIDIA 最新发布的《医疗与生命科学领域 AI 发展现状及趋势》调研显示,82% 的医疗行业领导者已将开源视为其战略的重要组成部分。通过采用开放模型、对其进行微调并在自有环境中运行,医疗机构可以实现数据主权:在保持对透明性和可复现性的控制的同时,仍能在复杂的智能体应用中保持领先的准确性。
了解更多关于 NVIDIA 在医疗和生命科学领域的 AI 解决方案。
2026 年 3 月 18 日🔗
NVIDIA BioNeMo 平台解锁突破性数据集,推动基因组疗法和虚拟细胞模型的发展
包括基因编辑、免疫疗法和 RNA 药物在内的突破性疗法,都需要快速、大规模的基因组分析。整合海量基因组数据和单细胞数据对于靶点发现和设计更安全的干预措施至关重要,而传统流程往往会将研究周期拉长至数月甚至数年。
NVIDIA BioNeMo 平台由 GPU 加速的工具、框架和 AI 模型组成,其中包括 NVIDIA Parabricks 和 NVIDIA CUDA-X Data Science (DS) 库,可大幅加速基因组学工作流。
在 GTC 大会上,NVIDIA 重点介绍了一批新兴医疗与生命科学企业,它们正在借助 BioNeMo 进行数据处理和模型开发,以解锁全新的疗法突破。
Basecamp Research 推出 Trillion Gene Atlas
Basecamp Research 联合 Anthropic、Ultima Genomics 和 PacBio ,并依托 NVIDIA AI 基础设施,推出 Trillion Gene Atlas (TGA)——这是一项旨在将人类对基因多样性的认知提升百倍的生物数据采集计划。
在 GTC 大会上,Basecamp Research 宣布将其 BaseData 数据集规模扩大 100 倍。该公司从全球数千个地点收集了数百万个新物种的全新基因组数据,其数据集规模已达到所有公共数据库总和的 10 倍。通过此次扩展,研究人员能够利用新一代生物基础模型,设计并开发新的治愈性治疗。
借助 TGA,Basecamp 计划使用 NVIDIA Parabricks 处理数千万亿级 DNA 碱基对,该工具可将数据处理速度提升 10 倍。这意味着原本需要耗时超过 20 年的分析,现在可能在不到两年内即可完成。
Tahoe 推动虚拟细胞模型迈向十亿级细胞规模
Tahoe Therapeutics 构建了全球最大的单体单细胞数据集 Tahoe-100M,用于打造新的虚拟细胞模型架构。这是一种由 AI 驱动的仿模拟系统,可模拟真实生物细胞复杂且动态的行为,从而无需进行大规模、高成本的湿实验室实验,即可实现治疗研发。
Tahoe-100M 包含超过 1 亿个细胞,涵盖 370 多种化合物和 50 种细胞系,将单细胞分析推进到只有通过 GPU 加速才能实现的规模。
Tahoe-100M 的训练流程完全运行在 NVIDIA Hopper GPU 上,并使用 NVIDIA cuVS 库。Tahoe 计划通过在 NVIDIA DGX 系统上运行并结合由 scverse 开发的 RAPIDS-singlecell 框架,将规模扩展至 10 亿细胞级别。
PerturbAI 推出活体内脑部扰动数据集
PerturbAI 与 NVIDIA 生物基础模型研究团队合作,发布了全球规模最大的体内 CRISPR 功能基因组图谱——包含近 800 万个全脑细胞的数据集,构建了目前在活体组织中规模最大的基因功能因果关系图谱之一。
该公司正在使用 NVIDIA CUDA-X DS 深入探索神经退行性疾病、精神疾病和代谢疾病背后的全新生物机制。借助 NVIDIA RTX GPU 加速工作流以及 RAPIDS-singlecell 在扰动分析方面的新功能,团队将分析时间从数天缩短至接近实时。
试用 NVIDIA 面向单细胞分析和基因组学的 Blueprint,并通过 GTC 会议“加速迈向计算生命科学与药物发现之路”,了解更多内容。
物理 AI🔗
2026 年 3 月 16 日🔗
NVIDIA IGX Thor 正式全面发售,将实时物理 AI 引入工业边缘

随着各行业从刚性自动化迈向物理 AI,业界需要全新一代的智能边缘计算设备,通过实时感知与推理,为复杂环境中的自主运行、安全关键型机器提供支持。
为满足这一需求,功能强大的工业级平台 NVIDIA IGX Thor 现已全面发售。该平台通过高速传感器处理、企业级可靠性以及功能安全能力,在边缘端实现实时物理 AI。
行业领导者借助 IGX Thor 扩展物理 AI 应用
NVIDIA IGX Thor 正在推动建筑、制造、物流、医疗与生命科学,甚至航天探索等领域的边缘应用发展。
卡特彼勒正在开发基于 IGX Thor 的驾驶舱对话式 AI 助手,以提升工作人员生产力和安全性。日立铁路利用 IGX Thor 在铁路网中部署先进的预测性维护和自主检测系统。
供应链解决方案公司凯傲集团正在结合 IGX Thor 与 NVIDIA Halos Outside-In 安全工作流,实现“由外向内”感知(outside-in perception)”。这意味着 AI 智能体能够通过部署在基础设施上的摄像头和动态虚拟安全围栏,增强自主机器人的功能安全机制。包括 SICK 在内的生态系统合作伙伴,正在为安全关键型应用提供传感器技术支持,以加速自主工业机器人的认证。
Agility Robotics 和 Hexagon Robotics 正在采用 IGX Thor,为其安全人形机器人提供实时 AI 推理和多模态传感器融合能力。
强生正在采用 IGX Thor,为其 Polyphonic 数字外科平台提供算力,将实时 AI 推理引入手术室。KARL STORZ 正利用 IGX Thor 开发新一代内窥镜和影像工具,以实现更精准的诊断。美敦力正在评估 IGX Thor。LEM Surgical 与 Horizon Surgical Systems 正在采用 IGX Thor,为手术机器人系统提供更高的精度与功能安全保障。
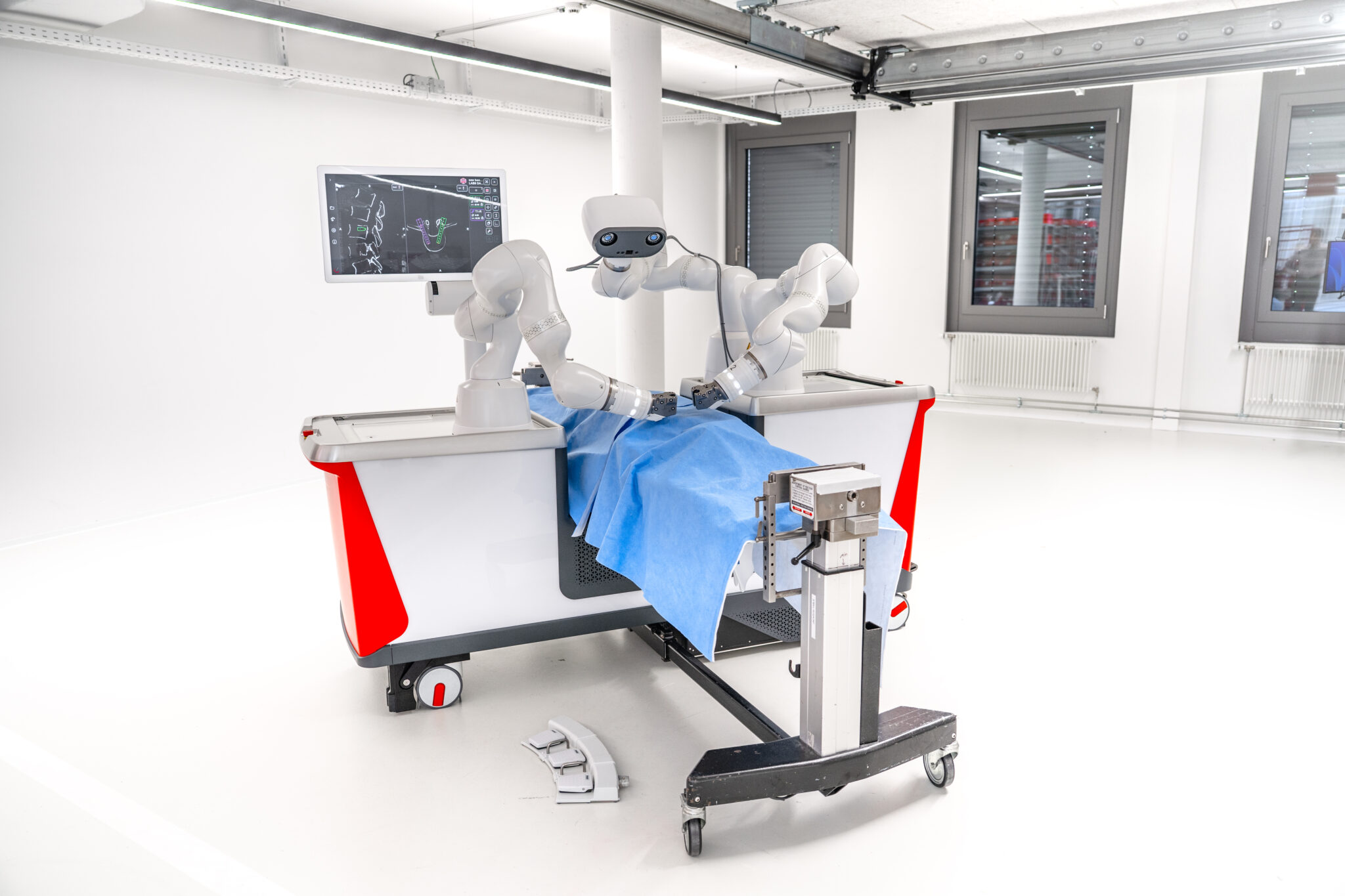
这些系统基于 NVIDIA Holoscan 平台构建,能够处理和编排包括视频、影像和设备遥测等在内的多模态传感器数据,从而实现新一代软件定义医疗设备和智能手术室所需的低延迟 AI 工作流。
Planet Labs 正在采用 IGX Thor,在轨道上将 TB 级多维卫星数据转化为可执行洞察,同时降低成本。CERN的研究人员正在使用 IGX Thor 运行先进的物理启发式 AI 模型,以高吞吐量处理海量数据流。

除了性能与安全性之外,工业 AI 还需要生产就绪的系统、多模态传感器以及可靠执行器。
Analog Devices、英飞凌、恩智浦半导体、意法半导体以及德州仪器正在将雷达设备、传感器和电机控制器集成到 NVIDIA Isaac Sim 框架中,并利用 NVIDIA Holoscan Sensor Bridge 加速下一代传感器与执行器的集成,从而打造更快、更安全、更智能的物理 AI 系统。
Leopard Imaging、D3 Embedded、Sensing 和 e-con Systems 已推出基于 Holoscan Sensor Bridge 的以太网摄像头模块,使传感器数据能够以低延迟直接流式传输至 GPU,用于实时 AI 处理。
Advantech、ASRockRack、NEXCOM、Connect Tech、Onyx、Inventec 和 Yuan 正在构建工业级和医疗级 IGX Thor 系统。这些系统可提供企业级性能、灵活的输入输出接口以及面向不同应用的定制化配置。
Barco、Cosmo 和 XRlabs 正在基于 IGX Thor 和 NVIDIA Holoscan 构建面向医疗科技行业可立即使用的医疗级边缘 AI 平台,使设备制造商能够借助 NVIDIA 的全栈加速计算与 AI 软件,加快开发并部署生产就绪型、通过医疗认证的临床解决方案。
IGX Thor 开发者套件现已通过全球分销合作伙伴发售。后续将推出具备功能安全的嵌入式系统 IGX T5000 模组以及面向高性能工作站的 IGX 7000 板卡套件。
欢迎观看 NVIDIA 创始人兼首席执行官黄仁勋的 GTC 主题演讲,并探索物理 AI、机器人与视觉 AI 相关会议。
2026 年 3 月 19 日🔗
机器人成群结队亮相 GTC
GTC 不仅是 AI 开发者与创新者的盛会,也成了各类机器人的秀场,人形机器人、机械臂,到四足机器人和自主移动机器人 (AMR) 纷纷现身会场。
得力助手:人形机器人
会展中心内,智元机器人的人形机器人热情迎接每一位 GTC 与会者。这款机器人通过 NVIDIA Isaac Sim 和 Isaac Lab 训练而成。

在展馆内,Agile Robots 的 Agile ONE 人形机器人展示了它灵活抓取和放置物品的能力。该公司借助 Isaac Sim 和 Isaac Lab,在仿真环境中对机器人进行训练。
Humanoid 展示了一款基于 NVIDIA Jetson Thor 打造的机器人。该机器人依托 Isaac Sim、Isaac Lab 和 NVIDIA Omniverse 库开发而成,能够根据与会者的需求,灵活递送相应物品。
与此同时,Hexagon Robotics 也把其 AEON 人形机器人带到了会场。这款机器人同样在 Isaac Sim 和 Isaac Lab 中完成训练,并在展台上现场演示了多种操作任务和遥操作能力。


机械臂大显身手
ABB 机器人带来了一台 DJ 机器人,它凭借娴熟的打碟技巧吸引众多观众驻足。目前,该公司正将 NVIDIA Omniverse 库直接集成到其 RobotStudio 编程与仿真套件中。
WORKR 展示了其机器人技术如何帮助陶瓷制造商 Fireclay Tile,实现繁重且重复的瓷砖分拣任务的自动化。该解决方案部署在 ABB 机器人的硬件上,其整套机器人流程基于 Isaac Sim 和 Omniverse 开发而成。
优傲机器人发布了搭载 Scale AI 软件的 UR AI Trainer。该系统支持人类操作员以“Leader-Follower”模式引导机器人完成任务,并且过程中同步记录运动、受力与视觉数据,用于训练视觉-语言-动作 (VLA) 模型。此外,该公司同样使用 Isaac Sim 和 Omniverse 在仿真环境中训练其机器人。

四足机器人和自主移动机器人亮相展会
FieldAI 展示了其 Field 基础模型如何赋能四足机器人在现实环境中实现自主导航与地图构建。该系统基于 NVIDIA Omniverse NuRec 库和 NVIDIA Cosmos 世界模型等 NVIDIA 技术打造。
展区内,观众纷纷驻足围观 Sentigent Technology 推出的小型机器人 Rovar X3。这款可室内外使用的陪伴机器人在 Isaac Lab 中完成训练,并运行于 NVIDIA Jetson 平台。
整个 GTC 展区内,来自 Serve Robotics 的十余台自主移动机器人随处可见:它们不仅在 SAP 中心主论坛开始前为与会者配送餐食,还在活动期间载着各类周边礼品,供参会人员自由领取。这些 Serve 机器人在 Isaac Sim 中进行仿真开发,并由 NVIDIA Jetson Orin 提供算力支持。


量子计算🔗
2026 年 3 月 20 日🔗
NVIDIA NVQLink 推动量子计算迎来转折点
在 GTC 上,NVIDIA 通过名为 cudaq-realtime 的全新应用程序接口 (API) 正式公开 NVQLink,并展示了多项推动量子纠错领域最新进展的演示成果。
NVQLink 于去年十月在华盛顿特区 NVIDIA GTC 大会上首次发布,其在量子处理器与 GPU 超级计算之间实现的低延迟、高吞吐量连接能力现已面向量子计算社区开放。戴尔推出的相关产品也标志着生态系统正在快速采纳这一项技术。
cudaq-realtime API 现已集成于 NVIDIA CUDA-Q 软件平台,为基于 GPU 加速的超级计算与量子处理器之间提供了开源、即插即用的集成解决方案。借助 cudaq-realtime,量子领域率先采用该技术的用户已成功实现了对量子硬件的紧密实时控制,并部署了混合量子 – 经典应用。
包括 Pacific Northwest National Laboratory 和 Lawrence Berkeley National Laboratory 在内的顶尖美国国家实验室,以及 QPU 制造商 Quantinuum 和 Infleqtion,量子软件提供商 Q-CTRL 等机构,均已采用 NVQLink。在某些应用中,相较于以往的方案,其在解码和校准延迟方面实现了数量级的降低。
此外,NVQLink 已开始在商业系统中部署。QPU 制造商 Anyon Computing 与量子系统提供商 SDT 在韩国一座商业数据中心联合发布了一套基于 NVQLink 的量子-GPU 系统,这标志着加速量子超级计算系统正迈向生产级应用阶段。
2026 年 3 月 16 日🔗
NVIDIA 推出 cuEST,加速半导体设计中的量子化学计算

本周,NVIDIA 发布了 NVIDIA cuEST。这是一款全新的 NVIDIA CUDA-X 库,可将电子结构计算迁移到 GPU 上执行。应用材料公司、三星、新思科技和 TSMC 已率先采用。
如今,一个先进芯片会包含超过 500 亿个晶体管。在工程设计芯片时,需要思考一个原子尺度上的基础物理问题:电子如何键合、如何迁移,以及它们如何在仅有数个原子厚度的薄膜中相互作用。
NVIDIA 工业与计算工程总经理 Tim Costa 表示:“随着半导体微缩逼近材料的物理极限,行业亟需大幅提升计算性能,以对新一代芯片设计中的量子力学过程进行仿真。借助 NVIDIA cuEST,行业领导者能够突破量子计算瓶颈,将高保真化学建模直接应用于生产流程,从而加速半导体创新。”
行业影响
- Applied Materials:应用材料公司使用 cuEST 加速的密度泛函理论(DFT)来建模复杂结构、预测材料特性并研究反应路径。
- 三星:三星将 cuEST 集成到其原本已基于 GPU 加速的内部流程中,使关键量子化学工作负载的端到端性能最高再提升 5 倍。
- 新思科技:借助 cuEST 和 QuantumATK,新思科技扩展了其功能,支持基于高斯型基组的 DFT,使半导体工作流程中的仿真速度提升最高可达 30 倍。
- TSMC:TSMC 使用 cuEST 的加速量子化学能力,推进下一代硅基设计工艺的发展。
从实验室走向晶圆厂
原子尺度建模最常用的方法是密度泛函理论。DFT 在精度与可扩展性之间取得了良好平衡,但其计算成本较高,限制了其在工业中的广泛应用,导致大多数应用仍停留在科研阶段。借助 cuEST,NVIDIA 使高精度量子化学在工业规模和实际生产流程中变得可行。
在过去,行业主要依赖 CPU 集群来运行这些仿真,对包括栅极介电材料和互连金属在内的候选材料进行评估,通常需要以批处理方式运行数小时甚至数天。
cuEST 提供了优化例程,使 GPU 能够加速基于高斯基组的 DFT 计算中的核心矩阵运算,包括重叠积分、动能、核吸引、库仑以及交换关联。它还支持从标准广义梯度近似到杂化泛函等多种泛函近似方法,使工程师能够在计算成本与精度之间进行权衡。
NVIDIA 对 cuEST 的目标是:将高保真材料建模从实验室带到晶圆厂。
欢迎在 GTC 上参观 NVIDIA 展台和 Synopsys 展台以了解更多 cuEST 信息,通过专题会议:“下一代发现:面向科学的代理式 AI、AI 驱动仿真与 GPU 加速化学”,进一步探索。
媒体和娱乐🔗
2026 年 3 月 17 日🔗
NVIDIA 发布面向媒体工作流的 AI 技术

在 GTC 2026上,NVIDIA 宣布了多项强大的新技术,旨在变革直播媒体和后期制作工作流。
这些新技术包括 NVIDIA Holoscan for Media 的全新内容本地化功能、NVIDIA Content-Localization Blueprint以及 NVIDIA AI for Media 和一套用于音频、视频和增强现实功能的软件开发工具包和 NVIDIA NIM 微服务——这些工具能够助力专业媒体人士更高效、更灵活地创建、编辑和分发内容。
在全球范围内实现内容本地化
Holoscan for Media 作为用于实时 AI 媒体管线的平台,现已支持可扩展的内容本地化功能。
这些功能以 NVIDIA AI for Media 技术及合作伙伴 AI 技术的集合形式提供,能够在 NVIDIA 加速计算基础设施上将视频、音频和图形翻译为多种语言,使直播媒体、新闻和体育公司能够从昂贵的手动多制作模式,转向基于软件驱动的大规模本地化模式。
NVIDIA 的合作伙伴 AI Media、Camb.AI、Chyron、Onemeta-Verbum 和 Panjaya 已加入不断扩展的 Holoscan for Media 生态系统。该生态支持 AI 字幕生成、图形翻译、配音以及本地化语音服务,可根据特定市场、地区、人群或文化背景调整音频内容,从而为当地用户提供自然、真实且具有吸引力的内容。
结合视频超分辨率和唇同步技术,此次更新可支持行业大规模向全球观众提供高质量的本地化内容。
此外,全新的 NVIDIA Content-Localization Blueprint 可以将音频、视频和图形适配更多语言和地区。
使用 AI 推动影视级制作
NVIDIA AI for Media 提供了一整套先进的音频和视频处理 AI 技术,通过 SDK、NVIDIA NIM 微服务以及生产就绪型参考蓝图形式提供。这些能力经过设计,可无缝集成到各种媒体应用中,涵盖从实时视频管线到高性能后期制作工作流等场景。NVIDIA AI for Media 为加速新一代 AI 增强型媒体体验的规模化发展,提供所需的基础构建模块。
在 GTC 2026 上,AI for Media 推出了多项全新性能优化,包括 NVIDIA Studio Voice、Active Speaker Detection(主动说话人检测)以及 Video Super Resolution(视频超分辨率),现可通过 AI for Media SDK 获取。
加速 AI 在体育领域的应用
在 GTC 2026 上,联想与 NVIDIA 宣布达成多年合作,旨在加速企业级 AI 在全球体育行业的应用。
此次合作将提供覆盖体育智能、体育运营以及体育媒体与内容的 AI 驱动的解决方案,以提升粉丝参与度,并推动性能提升、营收增长和运营效率优化。
通过将联想的端到端 AI 专业知识、Hybrid AI Advantage 解决方案以及 xIQ 编排层与 NVIDIA 全栈 AI 平台(涵盖加速基础设施、企业级软件和 AI 模型)相结合,双方在为体育场景提供前沿技术的同时,也积极拓展并联动更广泛的行业合作伙伴生态。
关注 GTC,了解更多 NVIDIA 在实时媒体工作流方面的技术。
请参阅有关软件产品信息的说明。
零售🔗
2026 年 3 月 17 日🔗
分子焕新:欧莱雅借助 NVIDIA ALCHEMI 将美妆研发速度提升 100 倍
美妆行业的未来,正由深厚的科学积累、创意灵感与代码共同谱写。欧莱雅正与 NVIDIA 深化合作,将 NVIDIA ALCHEMI(化学与材料创新 AI 实验室)引入价值数十亿美元的护肤领域。
过去,新型防晒产品的研发依赖于耗时数年的精密实验室配方开发,海量待实测的配方组合极大限制了研发进程。如今,欧莱雅正在简化其流程。
借助运行在 NVIDIA 加速计算平台上的 ALCHEMI,欧莱雅能够通过计算机模拟,更快速且更精准地预测配方性能。
相较于传统模拟方法,公司的研究人员如今能够将筛选具有防晒效果分子组合的速度提高 100 倍,大幅提升效率。结果表明,AI 有助于缩短研发周期、降低成本,从而加速整个化学与材料科学领域的研究、配方筛选和产品开发进程。
配方研发是欧莱雅科研体系的核心。公司每年在护肤、护发、彩妆和香水等产品领域推出超过 3400 个全新配方,年度研发投入超过 13 亿欧元。通过部署 NVIDIA ALCHEMI,欧莱雅的科研团队得以探索此前因计算复杂度过高而难以涉足的庞大化学空间。
这一技术的价值不仅局限于美妆领域。通过优化配方,欧莱雅能够更充分发挥有效成分在皮肤防护与抗衰老方面的效果。
除了防晒产品或新型香氛等复杂配方外,NVIDIA ALCHEMI 还可用于优化从半导体材料到油漆与涂料等多种产品的配方。
关注欧莱雅在 GTC 的分享,了解更多信息。
2026 年 3 月 17 日🔗
NVIDIA 推出零售智能体商业蓝图
在线购物的未来正在向智能体商业演进,由 AI 智能体协助消费者完成从商品发现、下单、支付到售后服务的全流程体验。
在 GTC 上,NVIDIA 发布了面向零售智能体商业的 NVIDIA Blueprint (NVIDIA Blueprint for Retail Agentic Commerce)。这是一套开源、生产就绪的参考架构,通过实现商家与主流生成式 AI 平台之间的代理到代理 (A2A) 通信,帮助零售商参与到新兴的智能体商业生态中。
这意味着,消费者在使用借助 ChatGPT 或 Gemini 时,可以在商家统一控制下完成包括安全支付、实时促销以及个性化推荐的完整购物流程。
一套代码,支持两大标准
该蓝图完整实现了 OpenAI 的智能体商业协议 (ACP),同时支持 Google 的通用商业协议 (UCP),使零售商能够通过单一部署同时兼容两大主流智能体商业标准。零售商及合作伙伴只需一条命令即可部署完整技术栈,并快速开展应用开发。
OpenAI 的 ACP 及其应用软件开发工具包 (SDK) 支持商家将购物体验直接嵌入 ChatGPT。OpenAI 作为全新 NVIDIA 蓝图开发的合作伙伴之一,提供了技术支持与指导,确保 ACP 的实现符合真实业务场景需求。
蓝图的核心能力
该蓝图基于 NVIDIA NeMo Agent Toolkit 构建,并由 NVIDIA Nemotron 开放模型驱动,内置四类核心智能体:
- 促销定价:支持动态、实时生成优惠策略
- 智能体式基于检索增强生成 (RAG) 的推荐系统:结合商家库存,提供上下文相关的商品推荐
- 语义搜索:实现基于用户意图的商品发现
- 多语言售后沟通:支持自动化、本地化的客户沟通
此外,蓝图还整合了委托支付系统,确保交易全流程在安全、可控的前提下完成。
构建在信任之上
智能体商业的核心在于信任与互操作性。在每一笔交易中,无论是商家、支付服务商,还是智能体开发者,都需要信任底层协议体系。
通过共同构建这一蓝图,NVIDIA 与 OpenAI 正在打造一个值得零售商信赖的智能体商业基础设施。同时,通过支持 Google 的 UCP,该蓝图进一步扩展至多智能体生态,实现跨平台协同。
如需了解更多关于该蓝图的信息,可访问 NVIDIA Blueprint 以及 GitHub。您还可以前往在 GTC 大会现场的合作伙伴展台——思科 (1421 展位,由 AIBLE 展示)、Arrow (3101 展位) 和 Infosys (239 展位) 体验该蓝图的实际应用。
金融🔗
2026 年 3 月 17 日🔗
Jump Trading 将成为首批采用 NVIDIA Rubin 平台的交易公司之一
Jump Trading 将成为金融服务领域首批采用 NVIDIA Rubin 平台的交易公司之一,以加速由 AI 驱动的资本市场研究和金融建模。
对 Jump 来说,成功的一个关键因素是“研究速度”——即能够探索多种深度学习方法、快速调整模型以适应不断变化的市场环境,并在全球市场中扩展交易规模。金融市场产生着全球最动态、最复杂的数据集。以美国最大市值股票为例,其日均交易所消息量超过 1000 万条,峰值速率超过每秒 20 万条。
为满足这些极高的要求,NVIDIA Vera Rubin 机架级扩展系统提供了超级计算机级别的计算密度、更高的内存带宽以及显著提升的能效,从而在提升性能的同时降低 Token 成本。
推动流动性和价格发现,离不开持续不断的研究,以及即时扩展新策略的能力。借助 NVIDIA 加速计算,Jump 能够大幅提升研究速度,并通过快速迭代复杂模型架构,借助 AI 适应不断变化的市场环境。
2026 年 3 月 17 日🔗
Hudson River Trading 借助 NVIDIA AI 工厂加速算法交易
全球领先的量化交易企业 Hudson River Trading (HRT) 正通过基于 NVIDIA Blackwell 架构和 NVIDIA Spectrum-X 以太网网络构建的 AI 工厂,大幅提升在投资研究与算法交易领域的性能。
该 AI 工厂将 HRT 研究人员与海量算力连接起来,简化了从数据摄取、模型训练、模拟到部署的工作流。依托这一定制化解决方案,HRT AI Labs 的工程师正在开发能够深入理解复杂市场微观结构的模型,提供更快、更智能的洞察,大幅提升交易决策的信心。相比 NVIDIA Hopper 架构,Blackwell 使 HRT 的研究迭代速度提升了 1.6 倍,从而能够:
- 通过高精度的价格预测与发现,实现投资回报最大化;
- 利用合成市场数据,安全地回测策略,显著降低研究成本与准备时间;
- 借助电子市场数字孪生,以微秒级保真度模拟全球市场,评估新的交易策略。
为高效支撑这一目标,HRT 将计算密集型模型训练部署在其位于 Lefdal Mine 数据中心的 AI 工厂内,并将其作为研究与训练中心之一。
Lefdal Mine 位于峡湾附近,完全由可再生水电与风能供能。其冷却系统通过虹吸现象抽取冰冷的海水进行散热,使 PUE 保持在 1.15 或更低。由于设施建于大山深处,物理安全性极高,且其冷却架构的设计极具前瞻性,可支持任意机架密度。
观看以下视频,了解 AI 工厂如何重塑金融服务,并深入探访 Lefdal AI 工厂内部:
观看由 HRT 主持的 GTC 专题演讲《现代资源负责型 AI 工厂蓝图》,了解更多信息。
2026 年 3 月 17 日🔗
从孤岛数据到互联智能:金融领导企业采用 NVIDIA 驱动的交易基础模型
包括 Mastercard、Revolut 和 Adyen 在内的全球金融服务领导者正积极采用由 NVIDIA 驱动的交易基础模型,以解码用户行为背后的复杂“语言”,优化全球商业流程,并更有效地防范金融犯罪。
Mastercard 正结合 NVIDIA NeMo AutoModel、NVIDIA 加速计算与 Databricks 平台,开发其专有的交易基础模型。这是首批专注于支付领域的基础模型之一,旨在洞察全球商业交易中的细微差异。该模型基于数亿笔交易数据进行训练,目前已展现出超越先进机器学习技术的潜力。
Revolut 构建了一个采用掩码预测的交易基础模型,以实现自我学习和下一交易项的精准预测。公司采用包括 NVIDIA Hopper GPU、cuDF 库以及 NVIDIA Nemotron 开放模型系列在内的 NVIDIA 全栈 AI 技术,显著提升系统性能,实现欺诈检测精度提高 20%,更准确的信用风险预测,以及交叉销售准确率提升 9.6%。
Adyen 已大规模部署交易基础模型,处理的支付额达 1 万亿美元,实现了从孤岛模型向统一系统的转型。借助强化学习,Adyen 能够对整个支付收单生命周期进行同步优化。依托 NVIDIA 加速计算平台,其基础模型推理速度提升了 195 倍。这使得在满足严苛延迟要求的同时,最大化商户转化率,并有效降低风险与运营成本。
欢迎深入了解更多关于 Mastercard 与 Databricks 的合作,并参加由 Revolut 和 Adyen 主持的 GTC 相关会议。