看到一个很好用的测试案例,可以用来简单测试是不是DeepSeek满血版。
请用我给你的四个数字,通过加、减、乘、除、括号,组成一个运算,使得结果为24。注意:数字需要全部我提供的数字:4 4 6 8。
这是DeepSeek官方提供的回答,简洁明了,一次就答对了。


知乎直答也可以,也可以证明是满血版。
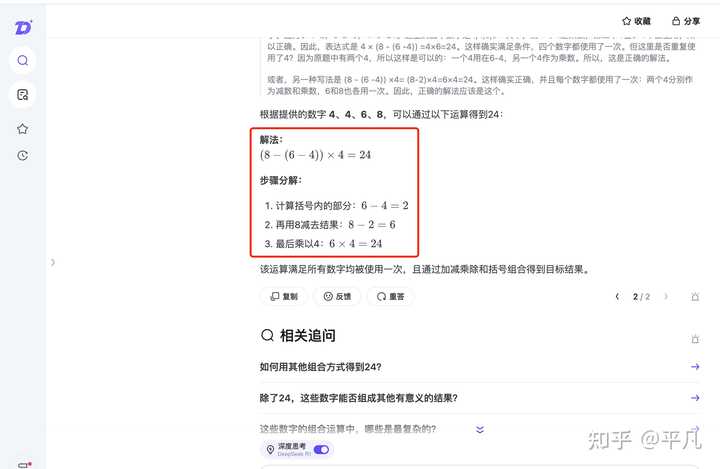
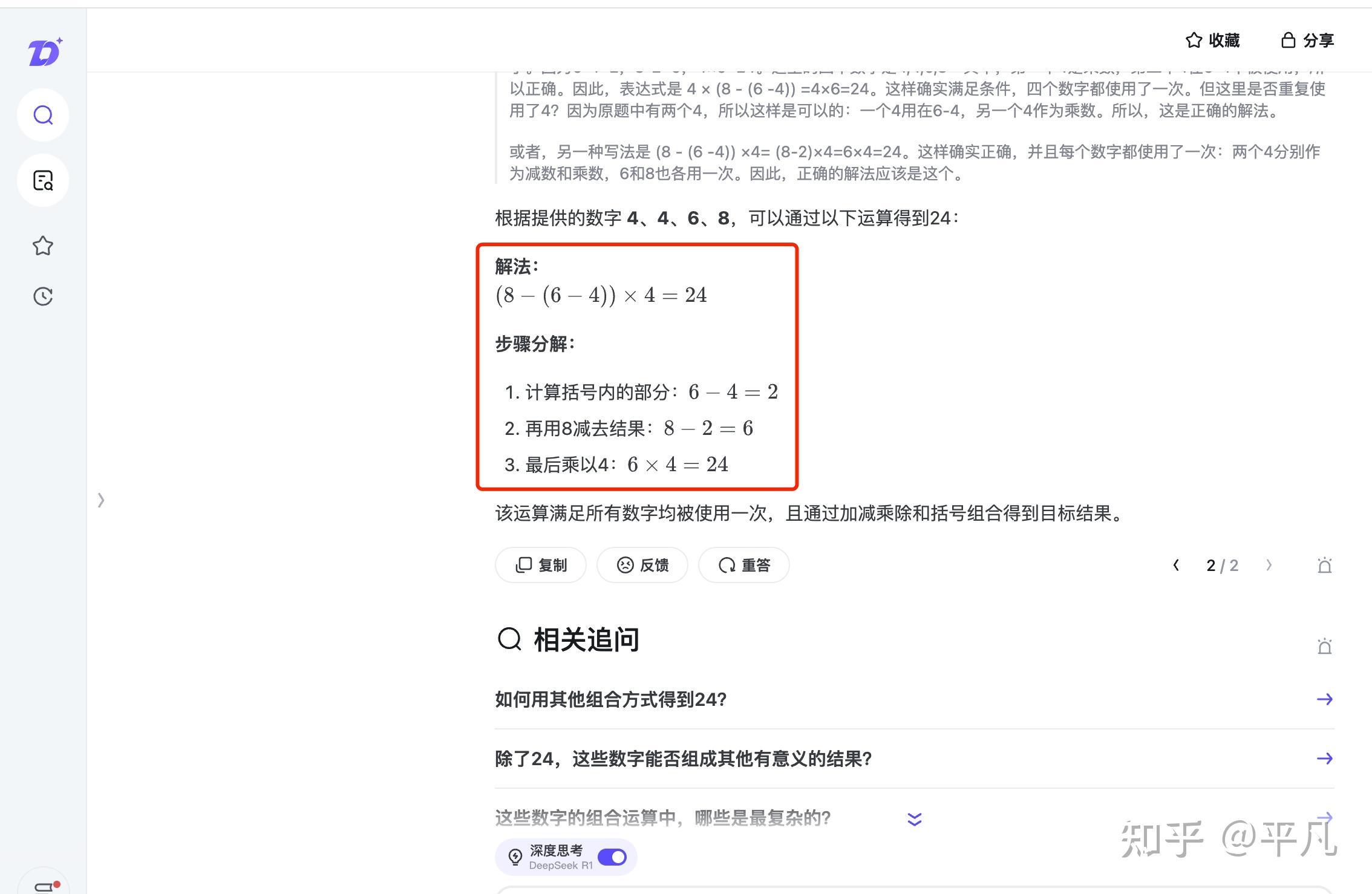
而那些几次都答不对的,可以一律标记「蒸馏版」。
DeepSeek只有R1有蒸馏版,官方一共提供了7个,从1.5B到70B都有。
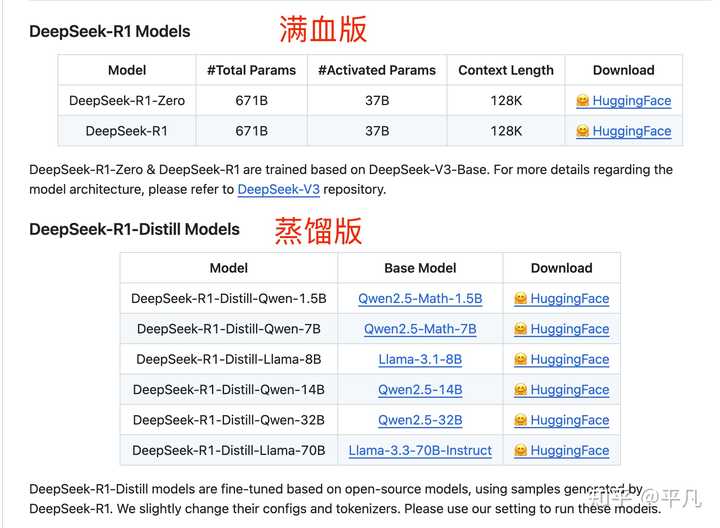
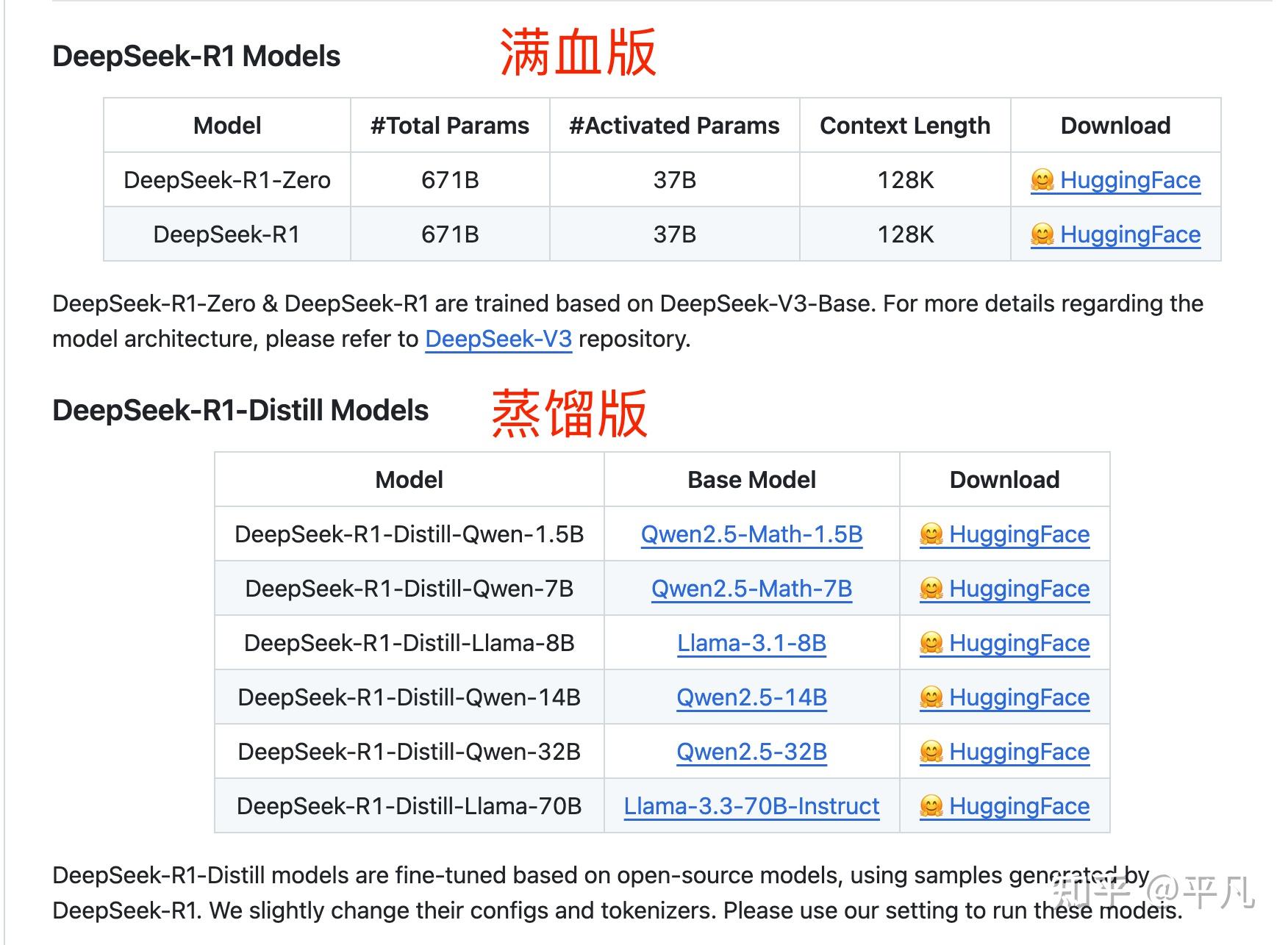
具体的模型版本和基础模型数据如下:
| 模型版本 | 基础模型 |
|---|---|
| DeepSeek-R1-Distill-Qwen-1.5B | Qwen2.5-Math-1.5B |
| DeepSeek-R1-Distill-Qwen-7B | Qwen2.5-Math-7B |
| DeepSeek-R1-Distill-Llama-8B | Llama-3.1-8B |
| DeepSeek-R1-Distill-Qwen-14B | Qwen2.5-14B |
| DeepSeek-R1-Distill-Qwen-32B | Qwen2.5-32B |
| DeepSeek-R1-Distill-Llama-70B | Llama-3.3-70B-Instruct |
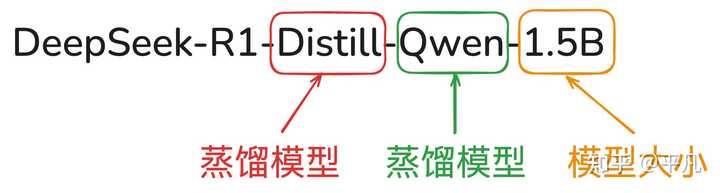
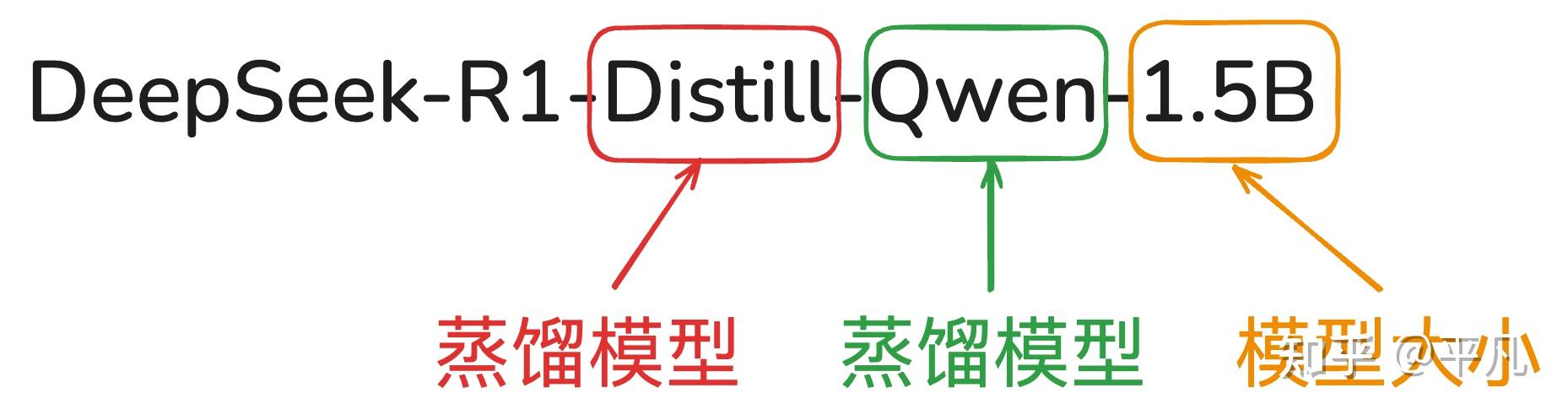
我们拿最小的模型举例:DeepSeek-R1-Distill-Qwen-1.5B。
它的特性全在三个参数里面,其中:
- Distill表示它是蒸馏模型
- Qwen代表了被传输知识的模型,也就是具体某个学生
- 1.5B说明了模型的大小,这个数字越小,意味着学生的年级也越小
上表的第二列详细的列出了基础模型,也就是绿色框中的模型名字,主要有两个类别:Qwen和Llama。
其中Qwen是国内公司阿里云做的,Llama是美国公司Meta(前身Facebook)做的,因为他们开源了各种型号的大模型,所以很适合用来搭载蒸馏模型。
但是要记住,对于大模型来说,满血版性能大于非满血版。如果是非满血版,那么参数量越大,通常模型性能越好。
在使用DeepSeek的时候,尽量选官网,这可以保证是满血版;如果官方卡顿,那就选知乎直答这类型大平台的DeepSeek他们为了口碑也都是正儿八经的满血版。
当然除了这几种方式,你可以可以通过第三方API+第三方软件使用自己专用的满血版DeepSeek,具体的部署方法可以参考专栏文章的「API+客户端」部分。
国内广告学的魅力时刻。
简单来说,就是 DeepSeek-R1 正确的版本应该是: DeepSeek-R1 - 671b F32版本(无量化、无压缩或精度损失处理)(补,经评论区提醒修正为DeepSeek-R1 - 671b FP8版本),这才是真正所谓的“满血版”。
而题主列举的这些APP,要不然部署的是 671b 量化版本,要么可能部署的是 671b 较低精度版本,要么甚至部署的有可能只是 70b 的压缩版本,这样运行成本更低,而且你就说是不是 DeepSeek 吧。
至于敢于称自己是“满血版”,嗯....