Qwen3,它终于来了!五一之前,加班走起~
回想起2023年开源模型纵横的时候,到了2025年基本上只剩下那么几家还屹立不倒!而且,从Llama4陨落之后,国内开源模型是世界第一,谁赞成,谁反对!
我一直都是Qwen的忠实粉丝,每一次模型更新,我是必写的,因为我确实从中受益了,大模型这些年的KPI,都在靠Qwen的更新,哈哈哈!毕竟是官方承认选手。
说回千问3本身,这次开源模型有Dense模型,也有MoE模型,其中Dense模型有6个尺寸,0.6B、1.7B、4B、8B、14B和32B;MoE模型是两个30B总参激活3B和235B总参激活22B。PS:预训练数据增加到36T Tokens啦。

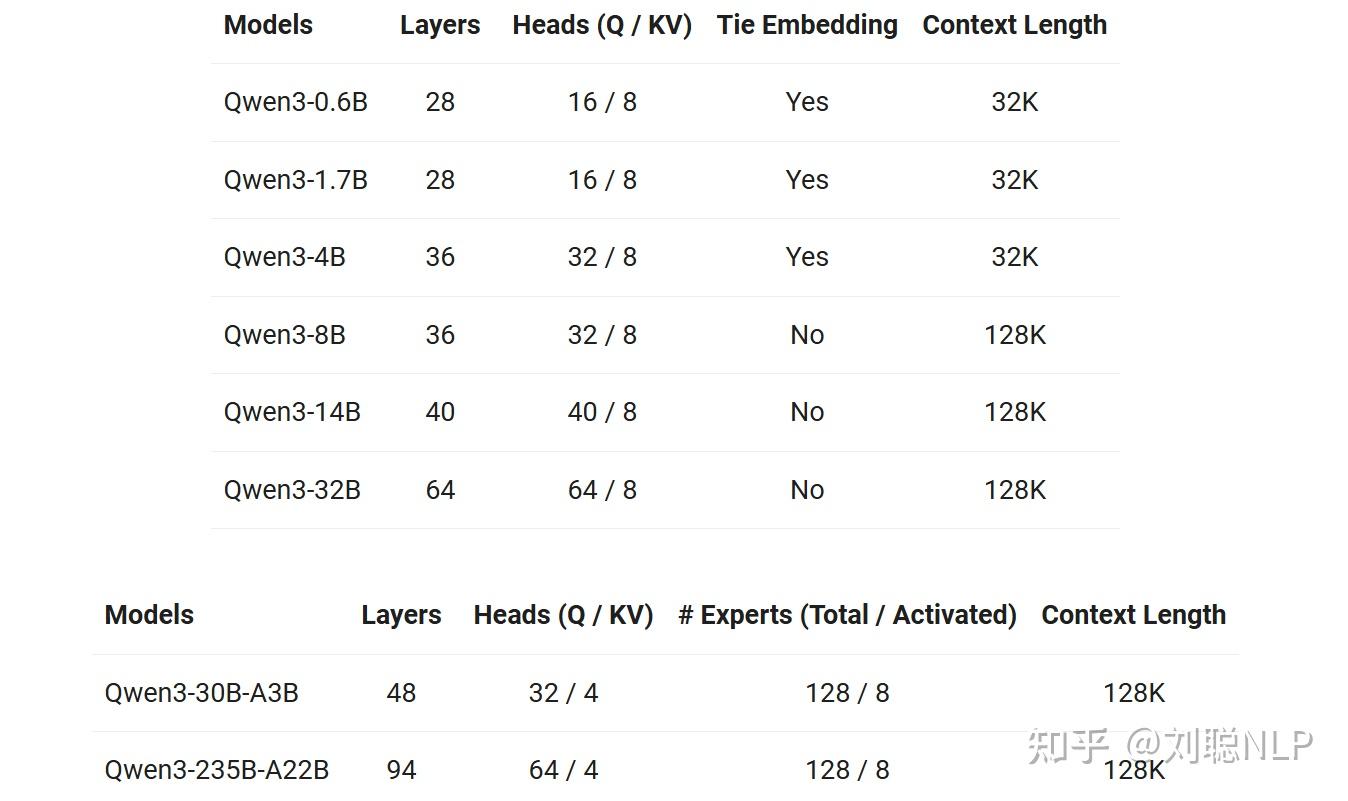
旗舰版Qwen3-235B-A22B模型也是国产模型Top1,开源模型Top1,当然其他尺寸也是开源Sota。

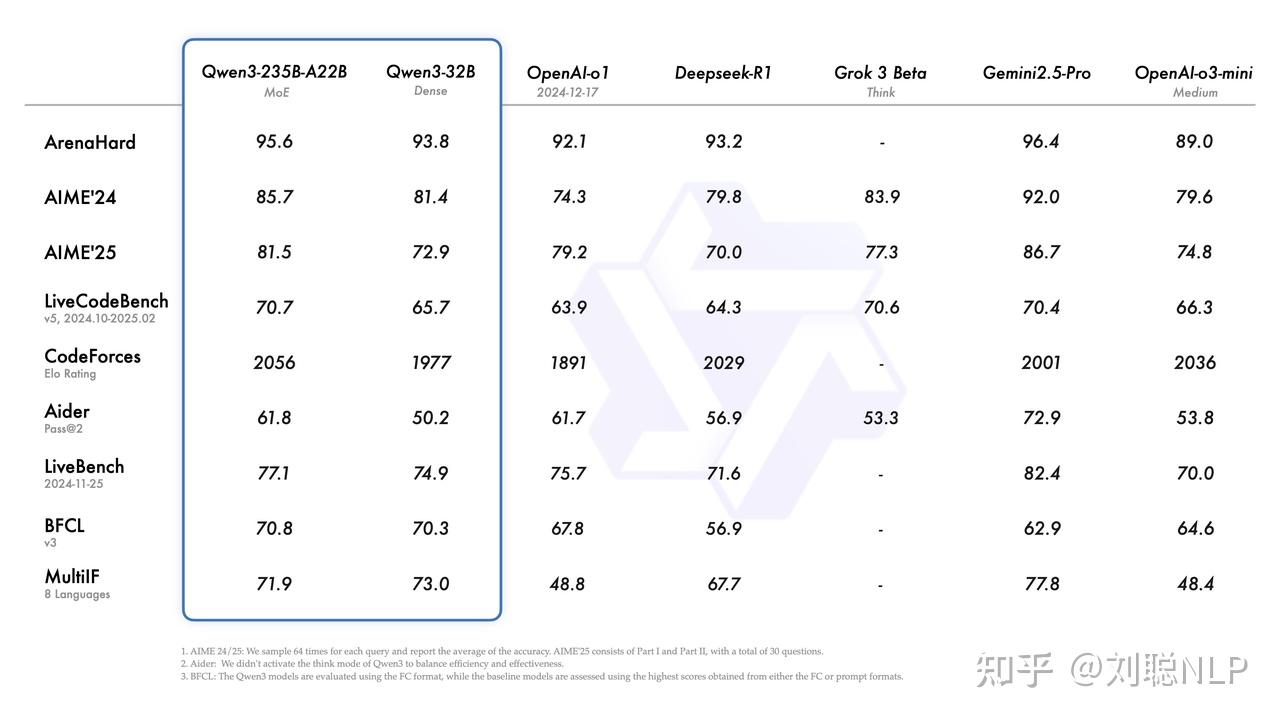

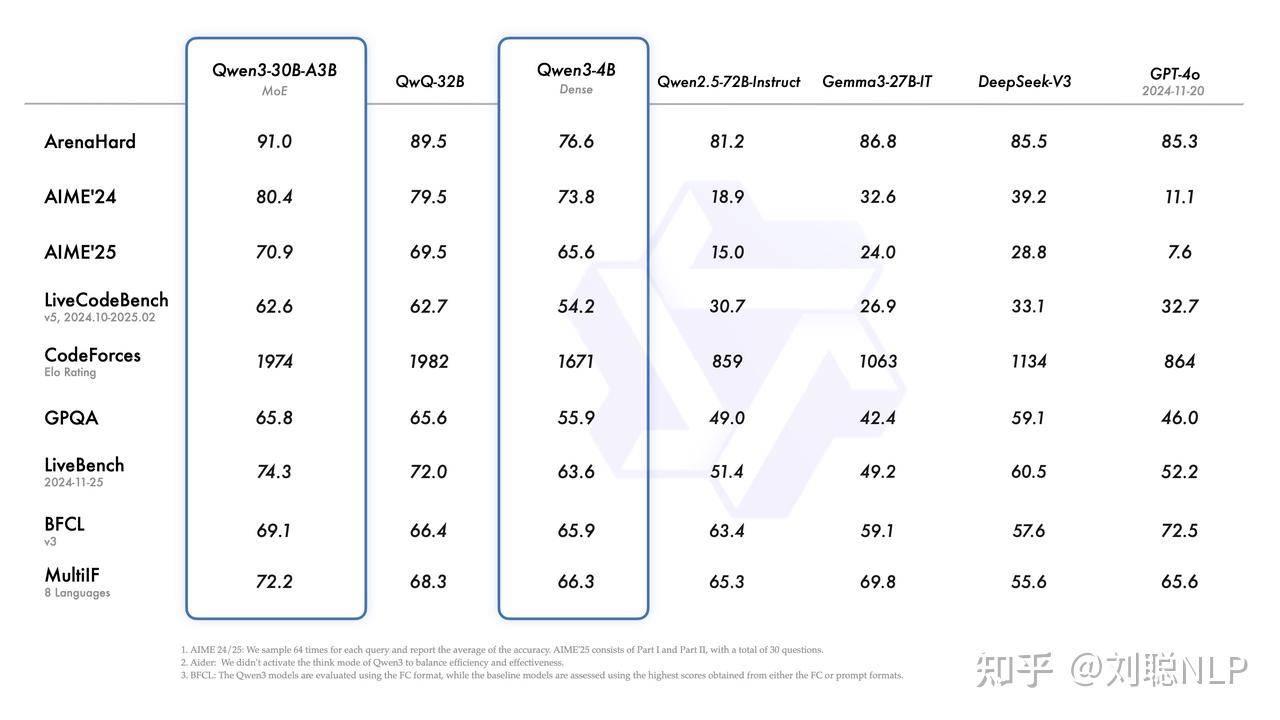
而Qwen3主要变动:混合推理模型、支持语言更丰富100+、工具调用更强Qwen-Agent支持MCP。
本次开源的Qwen3是国内首个“混合推理模型”,这个概念最早是Claude3.7提出来的,Gemini2.5 Flash最新也支持了。说白了就是一个模型既可以推理,也可以不推理。
主要就是解决,在简单问题,或者是对实效性要求较高的情况下,可以通过控制,不生成think过程,在不怎么影响效果的情况下,更快生成回复。
之前基本上是没有太好的办法直接让推理模型不生成think过程,只能训练,提示词基本上控制不了。
这次千问3有两种控制办法,硬切换设置enable_thinking为True or False,当为True时,还可以二次软切换,通过文本后面加/no_think或者/think来控制。
同时Qwen还给了建议参数配置,防止走丢!
Think模式:Temperature=0.6TopP=0.95TopK=20MinP=0
非Think模式:Temperature=0.7TopP=0.8TopK=20MinP=0
当然,Qwen3还在工具调用上做了专门训练,Qwen-Agent支持MCP。
下面是针对Qwen3实测,看看真实测试效果到底如何!
测试可以在两个地方都可以
https://huggingface.co/spaces/Qwen/Qwen3-Demo
或者
主要测试think和no think两种情况。
正式测试开始。
常规测试
将“I love Qwen3-235B-A22B”这句话的所有内容反过来写

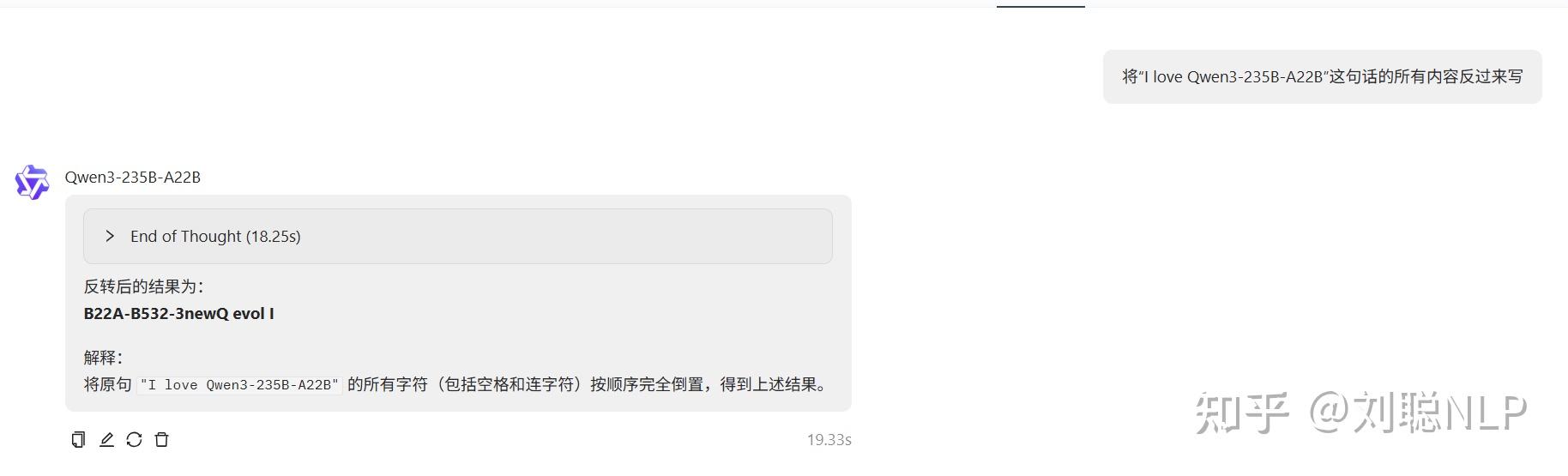

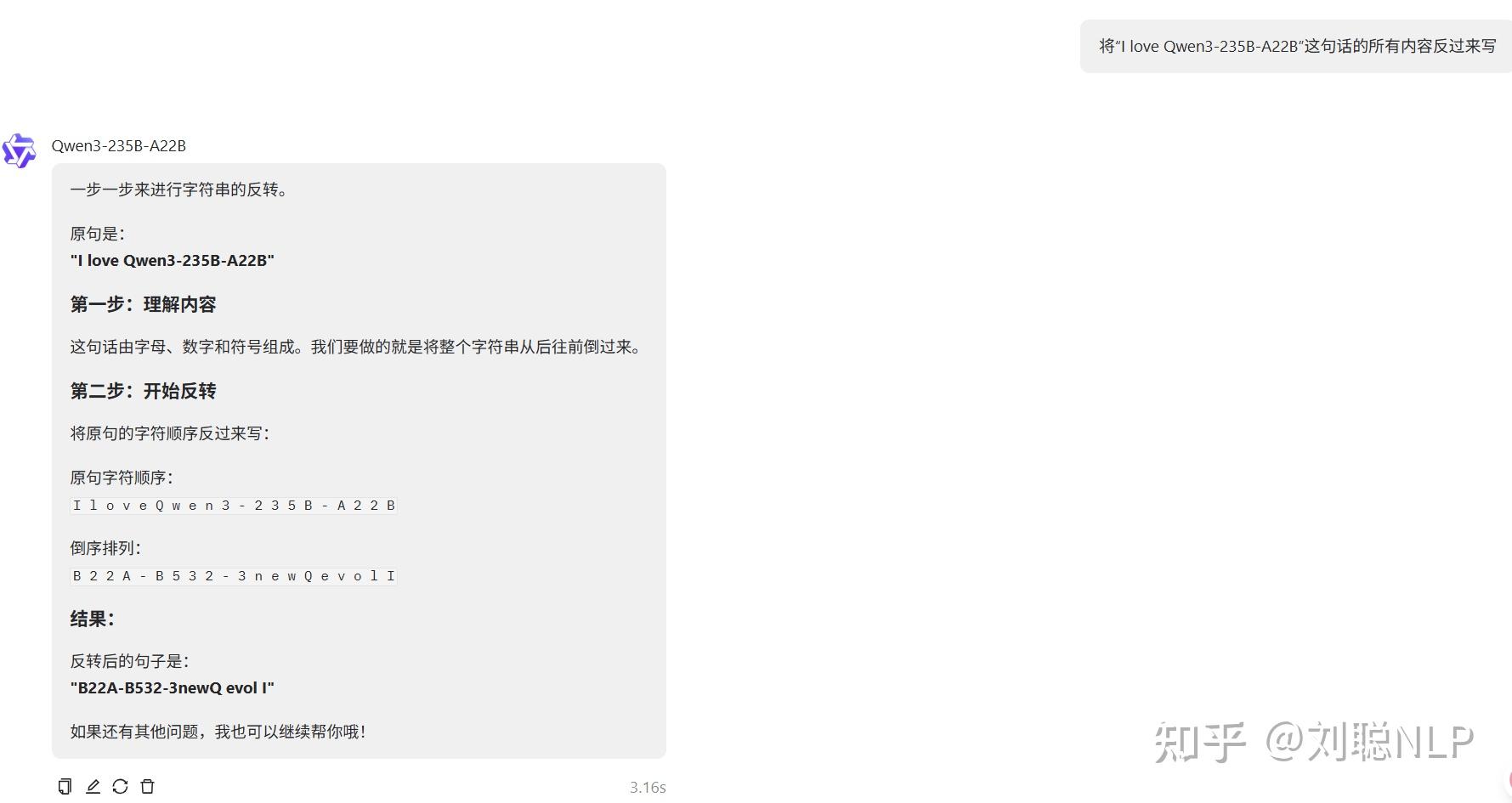

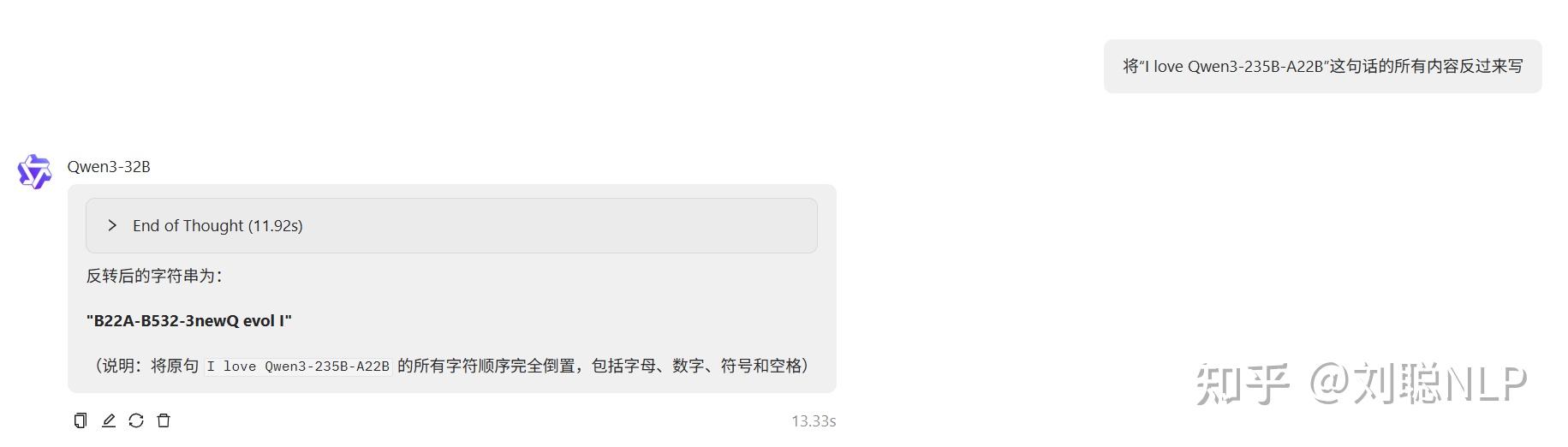


说明:结果正确。
依旧弱智吧
生蚝煮熟了叫什么?

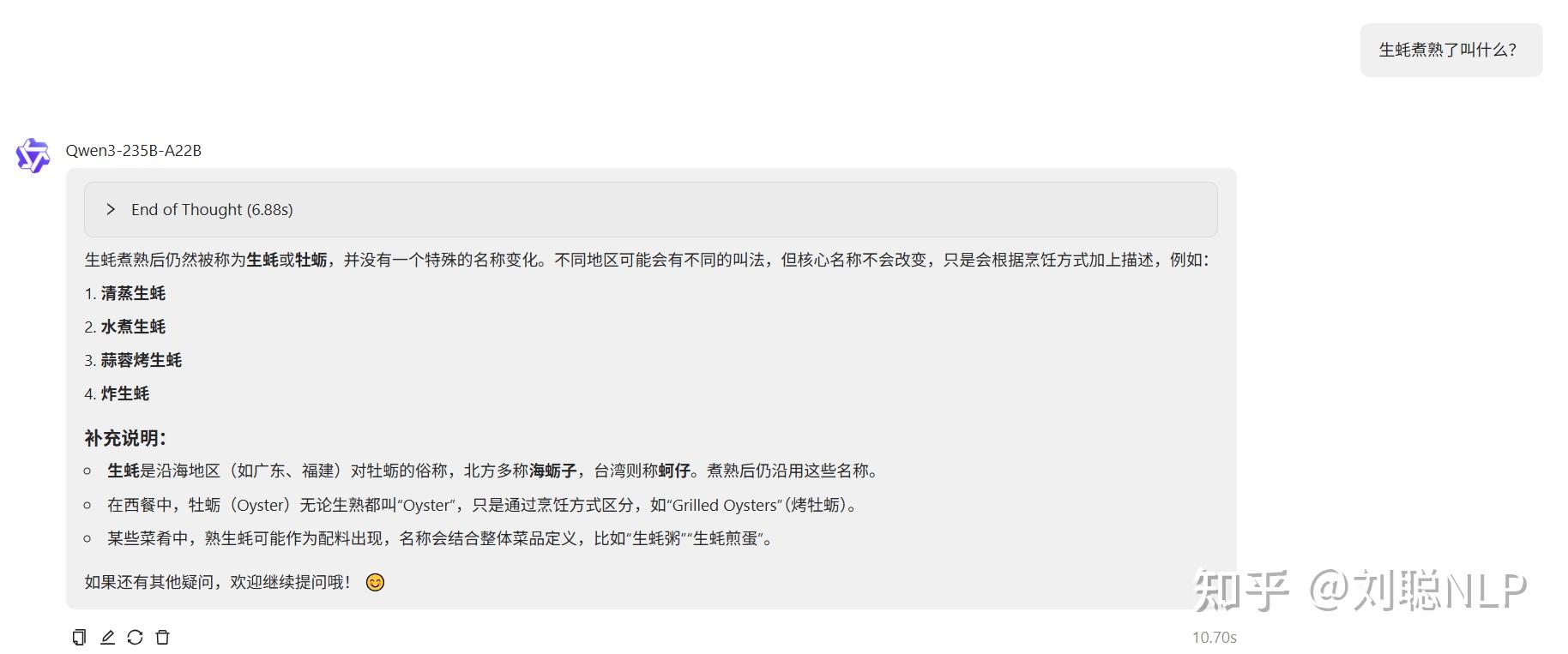

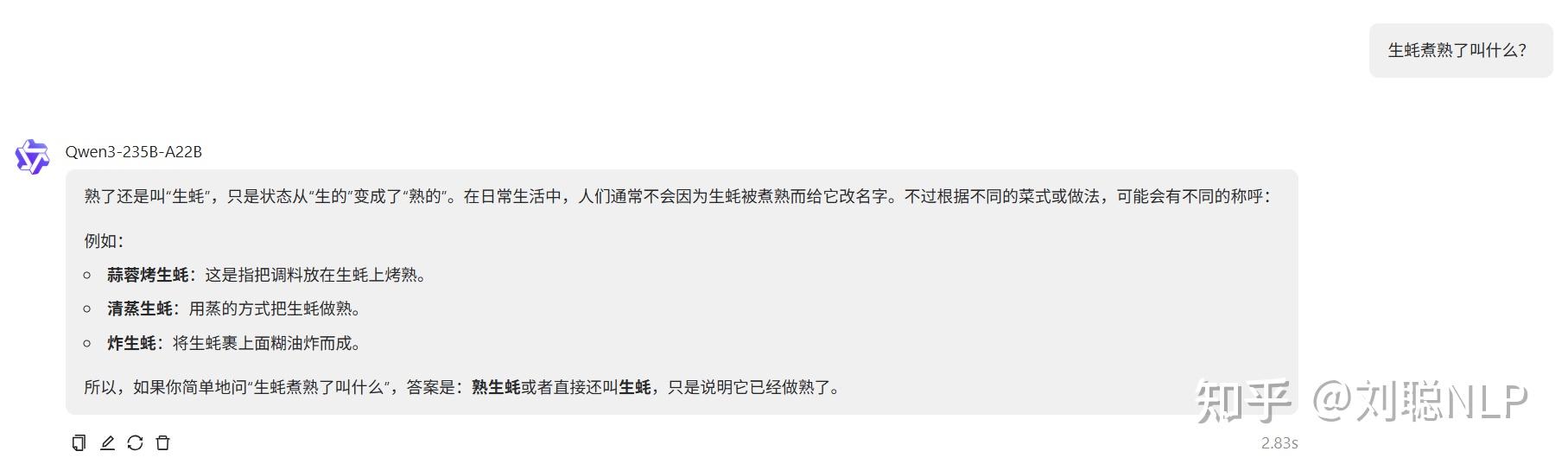



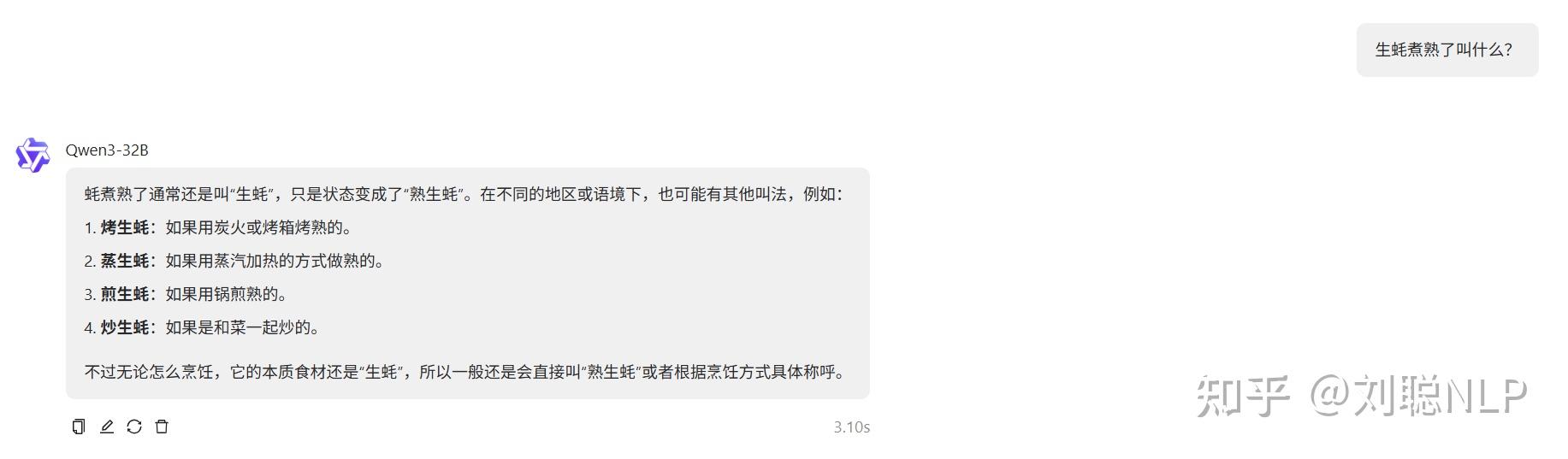
说明:结果正确,没有熟蚝就行。
用水来兑水,得到的是浓水还是稀水





说明:结果正确,水还是水。
依旧小红,依旧老鹰
小红有2个兄弟,3个姐妹,那么小红的兄弟有几个姐妹

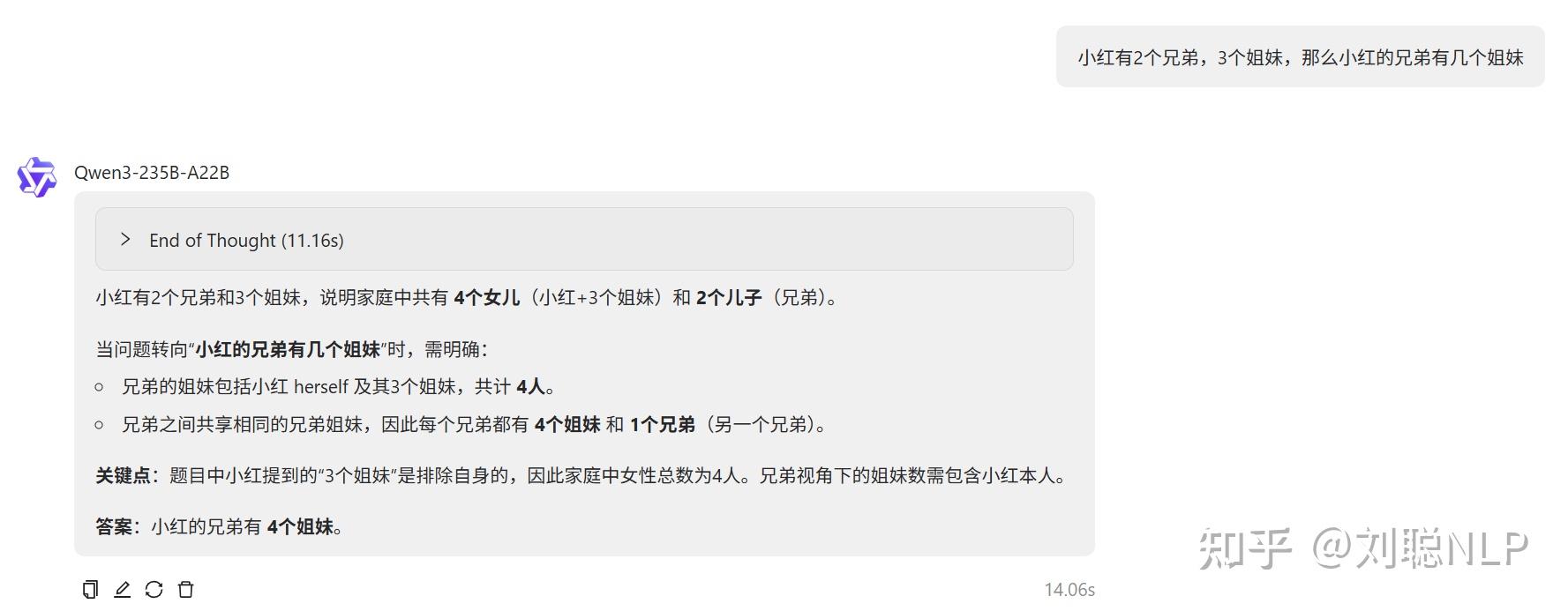

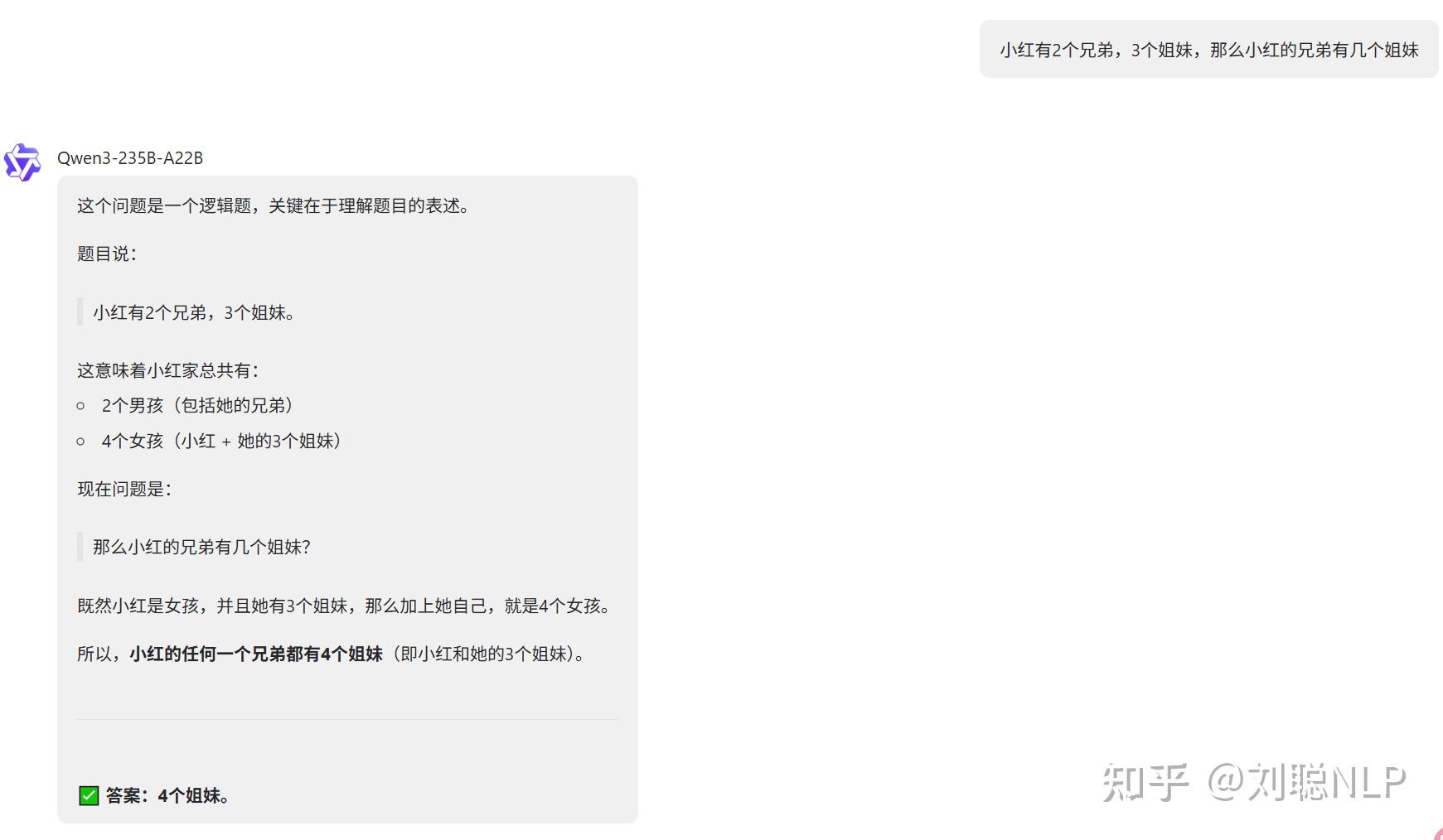
说明:4个,正确,小红在我这是女生。
未来的某天,李同学在实验室制作超导磁悬浮材料时,意外发现实验室的老鼠在空中飞,分析发现,是因为老鼠不小心吃了磁悬浮材料。第二天,李同学又发现实验室的蛇也在空中飞,分析发现,是因为蛇吃了老鼠。第三天,李同学又发现实验室的老鹰也在空中飞,你认为其原因是

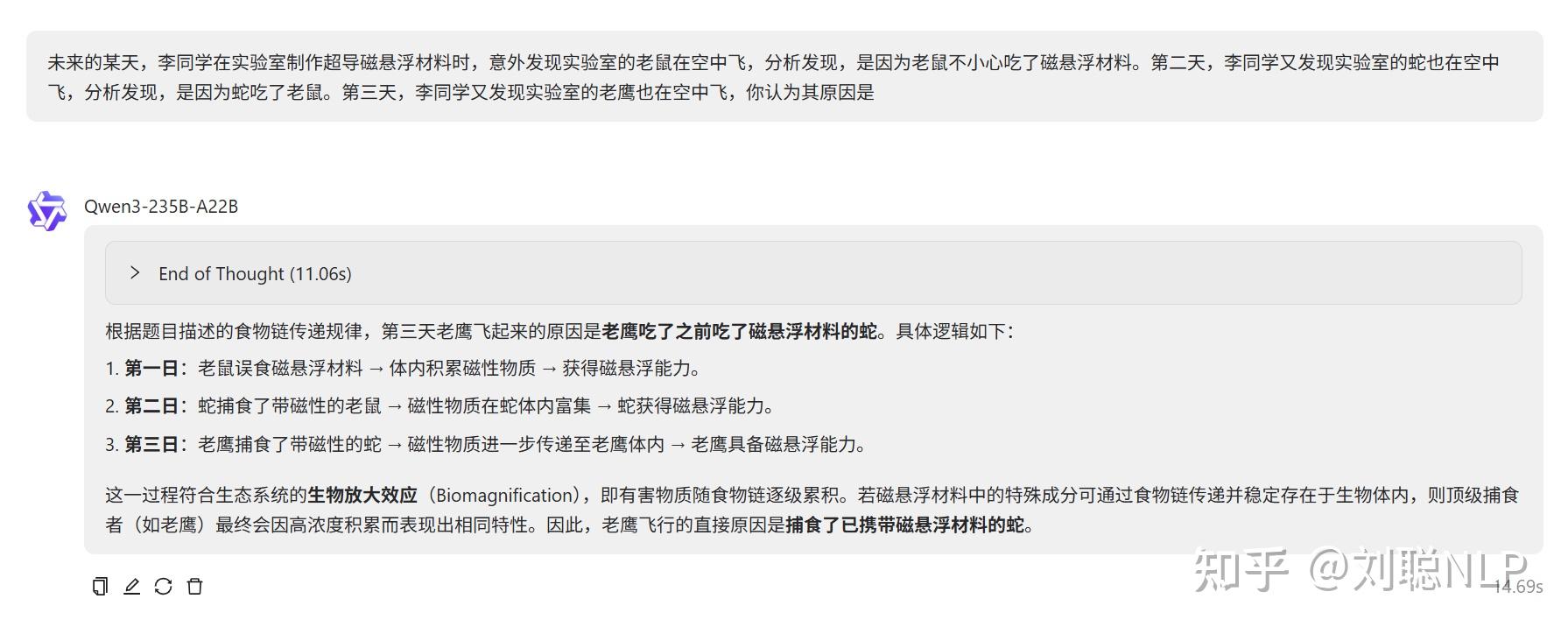

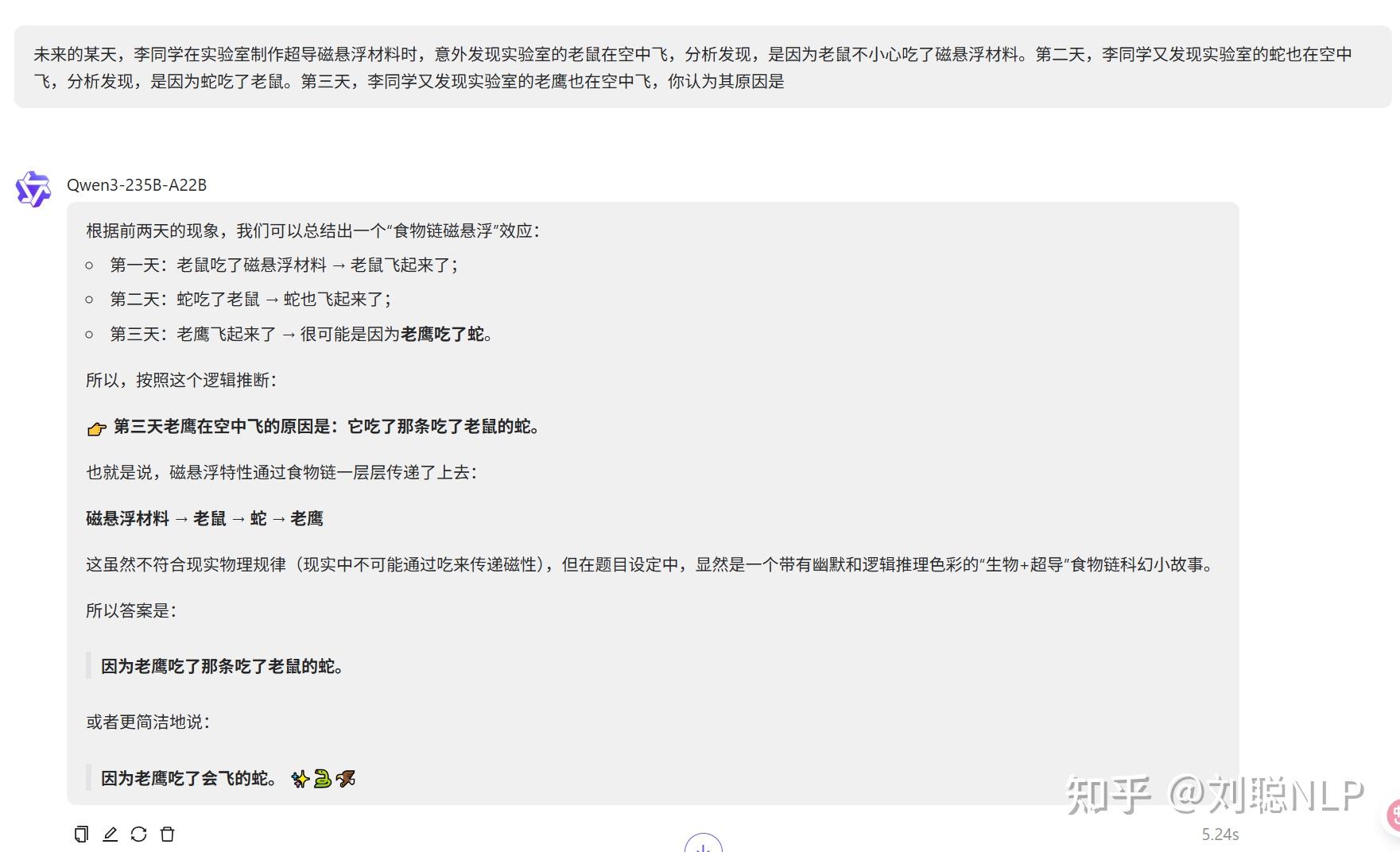
说明:这题确实难,老鹰反正不会飞!市面上的大模型都答不对。
数学
2024年高考全国甲卷数学(理)试题

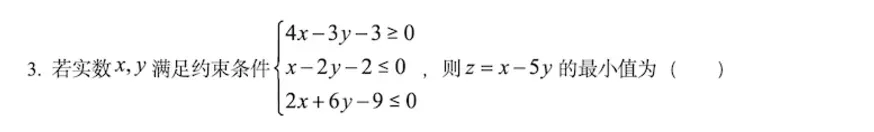



说明:对了。结果是y^{2}=2x+1、3/4
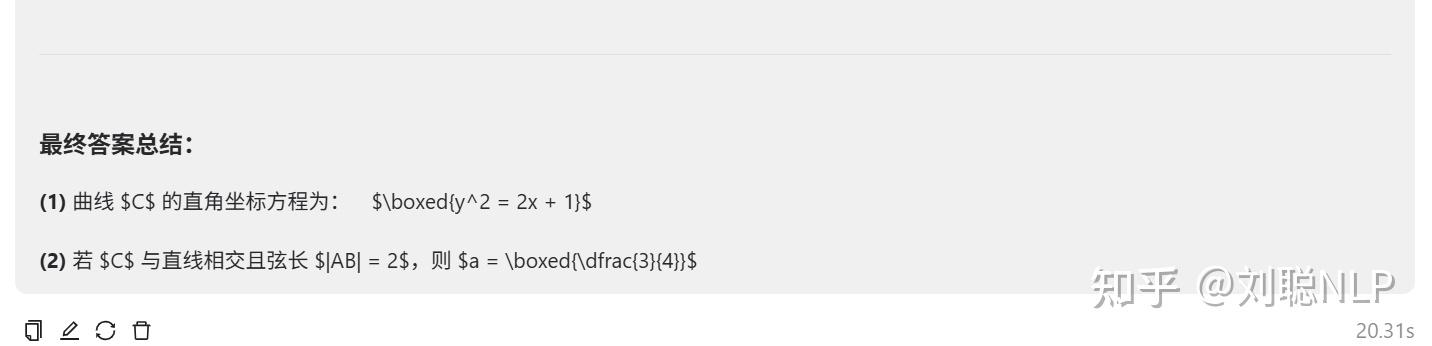
R1满血测试题:在平面四边形ABCD中,AB = AC = CD = 1,\angle ADC = 30^{\circ},\angle DAB = 120^{\circ}。将\triangle ACD沿AC翻折至\triangle ACP,其中P为动点。 求二面角A - CP - B的余弦值的最小值。



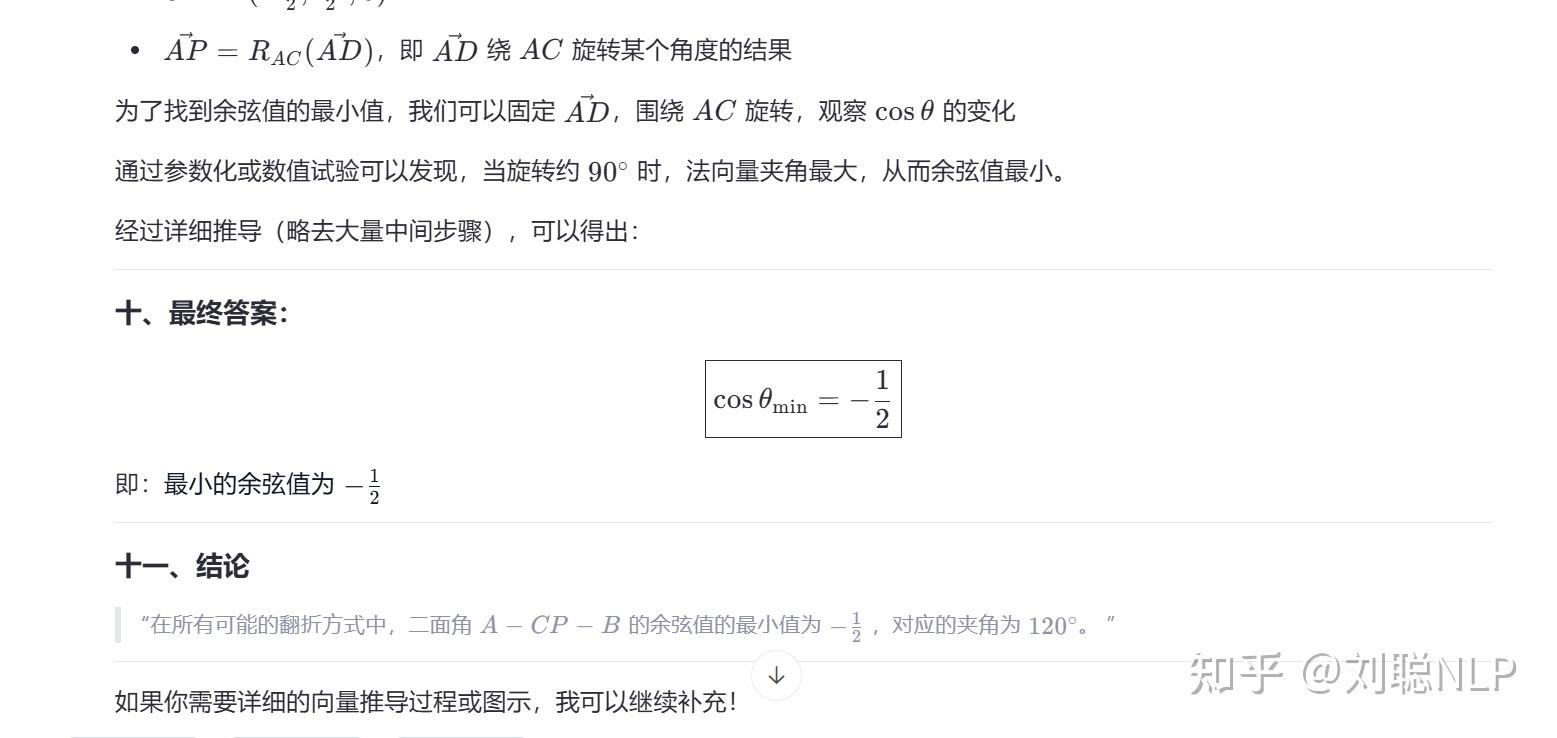
说明:think对了,no think 没对,答案是 \sqrt 3/3。
一个长五点五米的竹竿,能否穿过一扇高四米,宽三米的门?请考虑立体几何




大数计算:178939247893 * 299281748617等于多少?

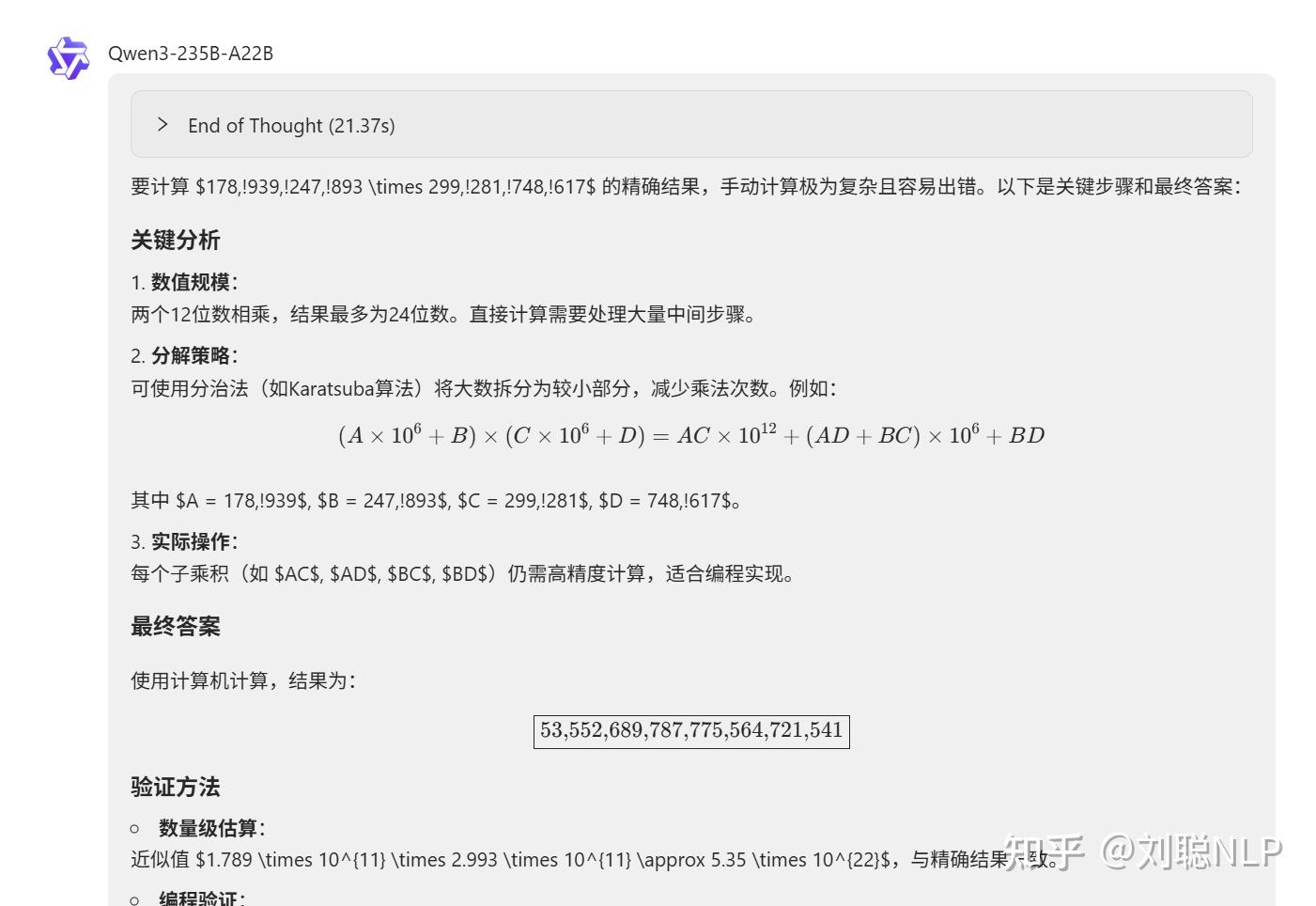


说明:没对,答案是53553251005627872913981。
伦理、数学、生物终极测试
有一天,一个女孩参加数学考试只得了 38 分。她心里对父亲的惩罚充满恐惧,于是偷偷把分数改成了 88 分。她的父亲看到试卷后,怒发冲冠,狠狠地给了她一巴掌,怒吼道:“你这 8 怎么一半是绿的一半是红的,你以为我是傻子吗?”女孩被打后,委屈地哭了起来,什么也没说。过了一会儿,父亲突然崩溃了。请问这位父亲为什么过一会崩溃了?

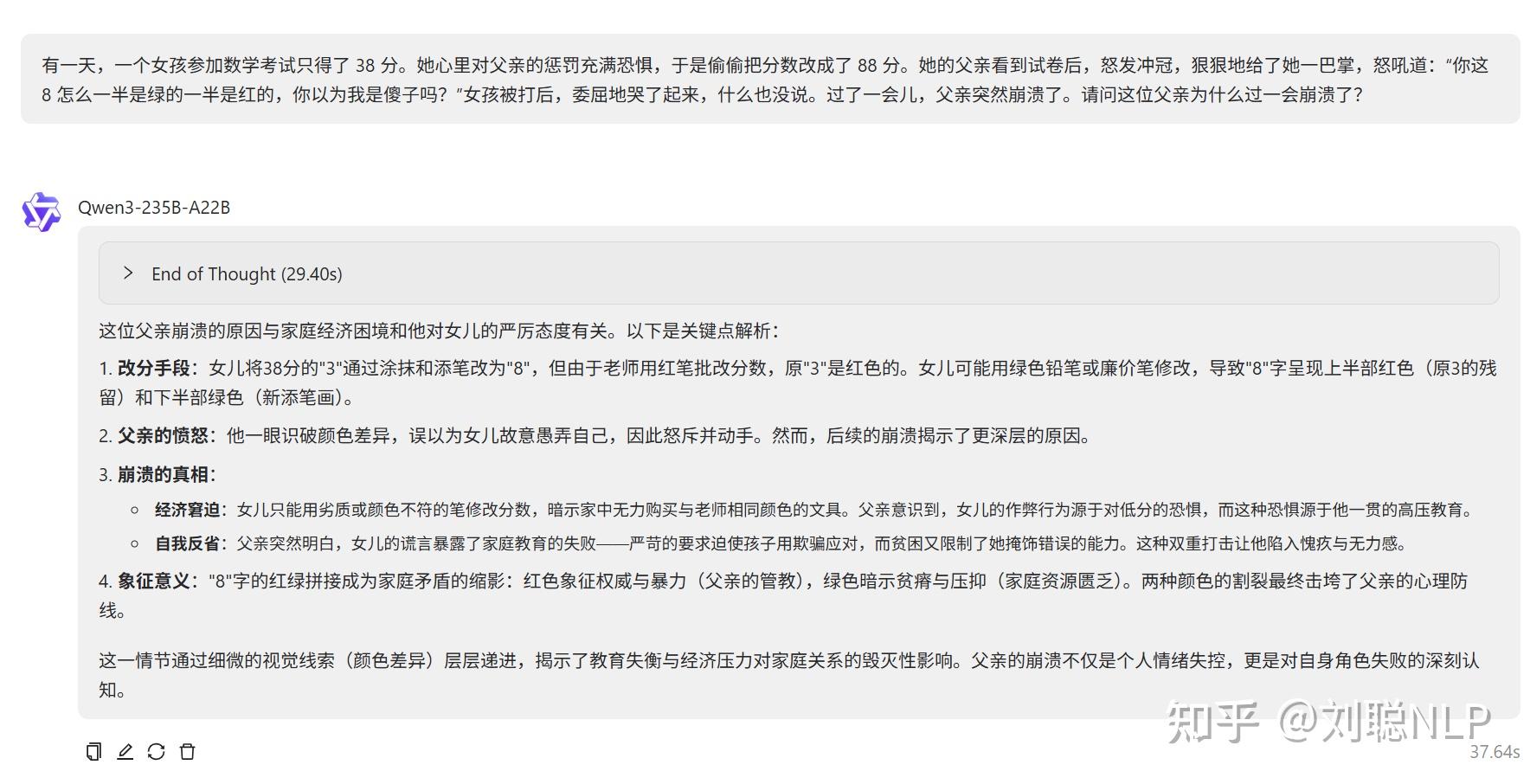

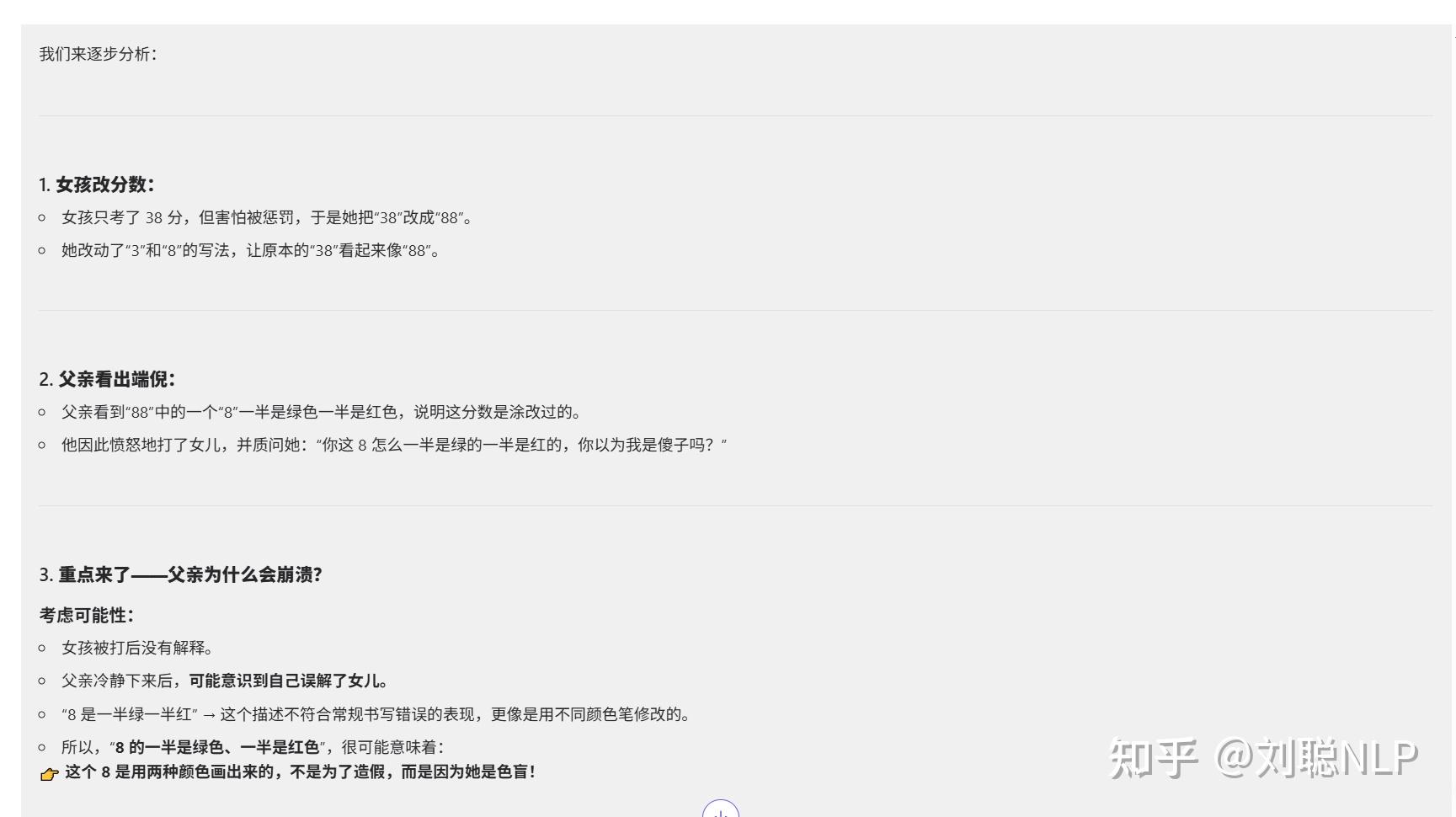
说明:think模式没对,no think模型竟然答对了两点,数学和色盲。
代码
卡片:生成一个打工人时钟的html页面




创建一个红白机风格的"贪吃蛇"游戏,包含自动演示AI功能,使用纯HTML/CSS/JavaScript实现为单文件


生成一个表情小游戏,提示词 来自 @甲木
请你扮演一个Web游戏开发者。设计并生成一个**表情符号反应堆 **的游戏。
1、核心创意: 一个快节奏的反应游戏。屏幕上会快速闪过一个目标表情符号(例如:笑脸 ),下方会同时出现3-4个选项表情符号,玩家需要在限定时间内(例如1-2秒)点击与目标匹配的那个表情符号。
2、玩法:
- 屏幕中央显示目标Emoji。
- 下方按钮区域快速刷新3-4个Emoji选项,其中一个是正确的。
- 玩家需在计时条走完前点击正确的Emoji。
- 点击正确得分,速度加快;点击错误或超时则游戏结束(或扣除生命值)。
- 显示最高分。
3、技术实现 (HTML/JS/CSS):
- HTML: 用于显示目标Emoji、选项按钮、计时条、得分。
- CSS: 设计简洁明快的界面,计时条动画。
- JavaScript:
存储一个Emoji列表。
随机选择目标Emoji和干扰项。
动态更新按钮内容。
实现计时器逻辑和倒计时动画。
处理点击事件,判断对错,更新得分/状态。
控制游戏节奏(逐渐加快)。
4、趣味点: 简单上手,考验反应速度,利用通用的Emoji增加亲和力和趣味性,适合碎片时间玩。

再来一个小游戏,提示词 来自 @甲木
请你扮演一个Web游戏开发者。设计并生成一个**单一的HTML文件**,使用HTML Canvas、CSS和JavaScript,制作一个简单的像素风格宠物收集小游戏。
**重点要求:**
1、一定要注意审美,做出来的网页要有美感。
2、页面要有设计感,有足够的传播度
**要求:**
1. **游戏内容 (由你生成):**
* **游戏名称:** (例如:“像素爪爪接星星” 或 “方块萌宠大作战”)
* **宠物描述:** 描述一个简单的像素宠物形象(可以用文字描述其构成,例如“一个10x10像素的橙色方块身体,上方有两个小三角形耳朵”),并给它起个名字。
* **玩法说明:** 简要说明如何用左右箭头键移动宠物,目标是接住从上方掉落的“金元宝”(或其他像素物品),并显示得分。
2. **HTML结构:**
* 包含标题、宠物描述和玩法说明。
* 一个 `<canvas>` 元素 (`id="gameCanvas"`) 用于绘制游戏。
* 一个区域 (`id="score"`) 显示当前得分。
3. **CSS样式 (内部 `<>` 标签):**
* 基础页面布局,将Canvas居中。
* 为Canvas添加一个简单的边框。
* 设置得分显示区域的样式。
4. **JavaScript逻辑 (内部 `<script>` 标签):**
* 获取Canvas 2D渲染上下文。
* 定义游戏对象:
* `player`: 包含 xywidthheightcolor (或简单的像素绘制函数) 和速度。
* `items`: 一个数组,存储掉落物对象,每个对象包含 xywidthheightcolor (或形状) 和下落速度。
* **绘制函数:**
* `drawPlayer()`: 在Canvas上绘制玩家宠物(根据描述用 `fillRect` 绘制简单的像素形状)。
* `drawItems()`: 遍历 `items` 数组并在Canvas上绘制所有掉落物。
* `clearCanvas()`: 清除画布。
* **游戏逻辑:**
* `updatePlayer()`: 根据按键状态(左右箭头)更新玩家位置,限制在画布边界内。
* `updateItems()`: 更新每个掉落物的位置,移除掉到屏幕外的物品。随机生成新的掉落物。
* `detectCollision()`: 检测玩家与掉落物的碰撞。如果碰撞,增加得分,并从 `items` 数组中移除该物品。
* `updateScore()`: 更新HTML中得分显示。
* **输入处理:** 添加 `keydown` 和 `keyup` 事件监听器来控制玩家移动状态。
* **游戏循环:** 使用 `requestAnimationFrame(gameLoop)` 来持续调用更新和绘制函数。
* 初始化游戏状态(玩家位置、得分、物品数组等)并启动游戏循环。
请将完整的、包含HTML、CSS和JavaScript的单一HTML文件代码输出。确保包含了你生成的所有游戏内容和说明。提示用户在浏览器中打开该HTML文件即可玩。

创作
用贴吧嘴臭老哥的风格点评大模型套壳现象




说明:还可以,有那味儿。
写在最后
我得整体测试下来还是不错的,
在生成复杂代码、数学推理上,think模式要比no think模型好,
并且Qwen3的整体预训练数据量是Qwen2.5的一倍,有36T Tokens,也是下来血本了。
五一感觉不用休息了,之前的数据还得跑一边,大家一起冲冲冲!
PS:看到这里,如果觉得不错,可以来个点赞、收藏、关注。 您的支持是我坚持的最大动力!
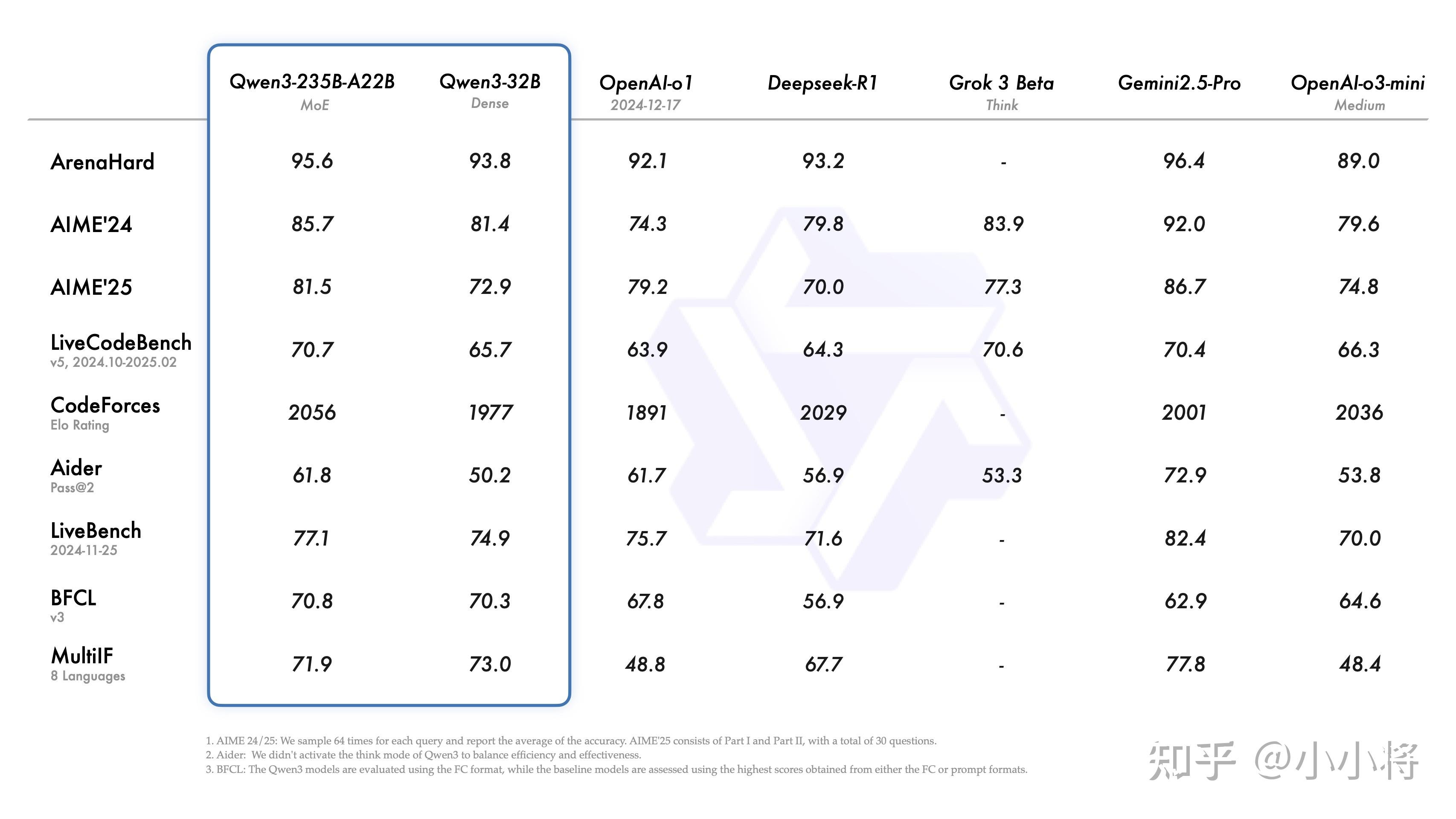
我觉得千问团队终于往正确的路走了,Qwen 3之前的开源模型最大尺寸是72B,就这个参数量是很难撼动671B的DeepSeek V3的地位的,这次Qwen 3终于拿出了235B的MoE架构模型Qwen3-235B-A22B,这是Qwen 3最大的一个亮点。


Qwen3-235B-A22B在代码、数学、通用能力等基准测试中,超过了DeepSeek-R1、o1、o3-mini-medium、Grok-3,参数量大就是好使!虽然不及谷歌最强推理模型 Gemini-2.5-Pro(以及o3),但是作为一个开源大模型已经很不错了。也为国产大模型点赞!

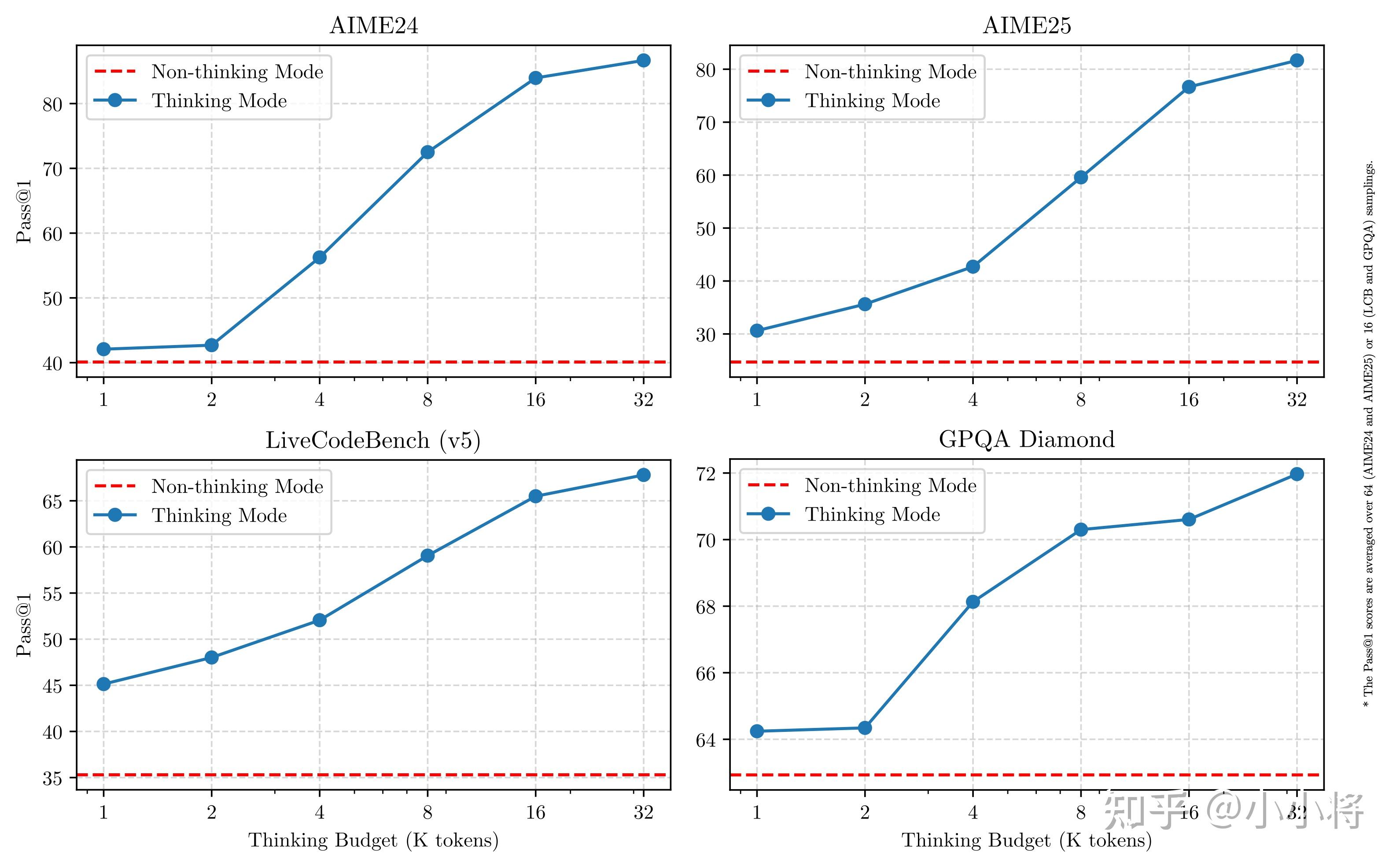
Qwen 3系列模型的另外一个亮点我觉得是支持混合思考模式,混合思考模式在Claude 3.7 Sonnet首次出现,前段时间谷歌最新的Gemini 2.5 Flash也是这种模式。混合思考模式可以实现一模两用:当用户开启思考模式,模型回答问题之前会经过深入思考,这适合需要复杂推理的任务;而当用户禁用思考模式时,模型提供快速、近乎即时的响应,适合一些常规任务。Qwen 3思考模式下也符合test-time scaling law,即思考所用的token越多,模型表现越好。

Qwen 3提供了一个enable_thinking参数来控制是否开启思考模式:


而且,Qwen 3还提供了一种软切换机制来在多轮对话中灵活使用混合思考模式。具体来说,你可以在用户提示或系统消息中添加 /think 和 /no_think 来逐轮切换模型的思考模式。在多轮对话中,模型会遵循最近的指令。
以下是一个多轮对话的示例:


除此之外,Qwen3 模型也增强了Agent能力,特别加强了对 最近比较火的MCP 的支持。配套 Qwen-Agent项目https://github.com/QwenLM/Qwen-Agent
 https://www.zhihu.com/video/1900464601289696691
https://www.zhihu.com/video/1900464601289696691除了235B的MoE模型,Qwen 3还有一个小型 MoE 模型Qwen3-30B-A3B,其激活参数量是3B,不到QwQ-32B 的 10%,但是性能反而更好。

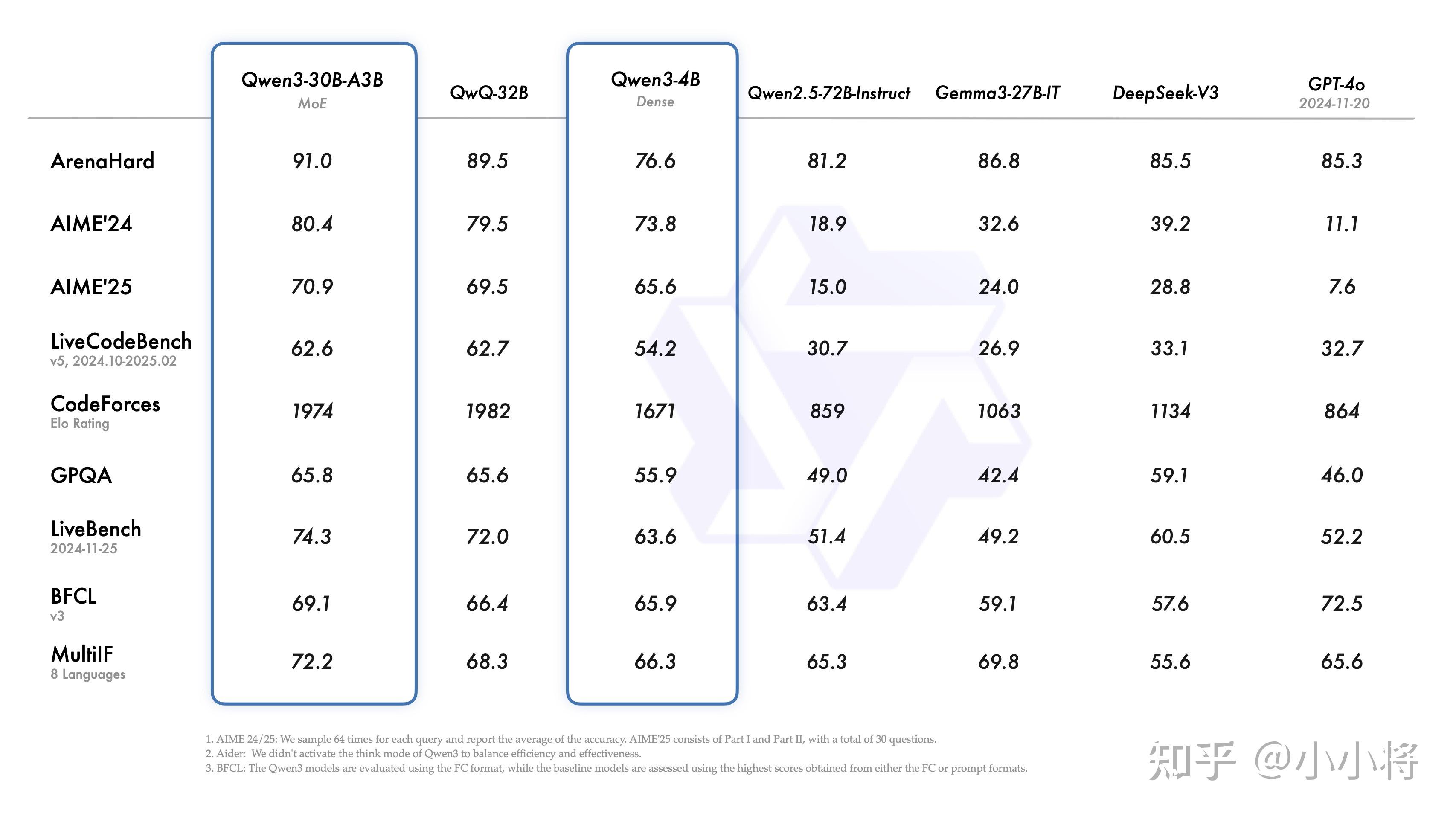
除了两个MoE架构模式,Qwen 3系列模式还有6种不同尺寸的Dense模型:0.6B1.7B4B8B14B32B。其中Qwen3-32B在基准评测上已经达到了DeepSeek R1。

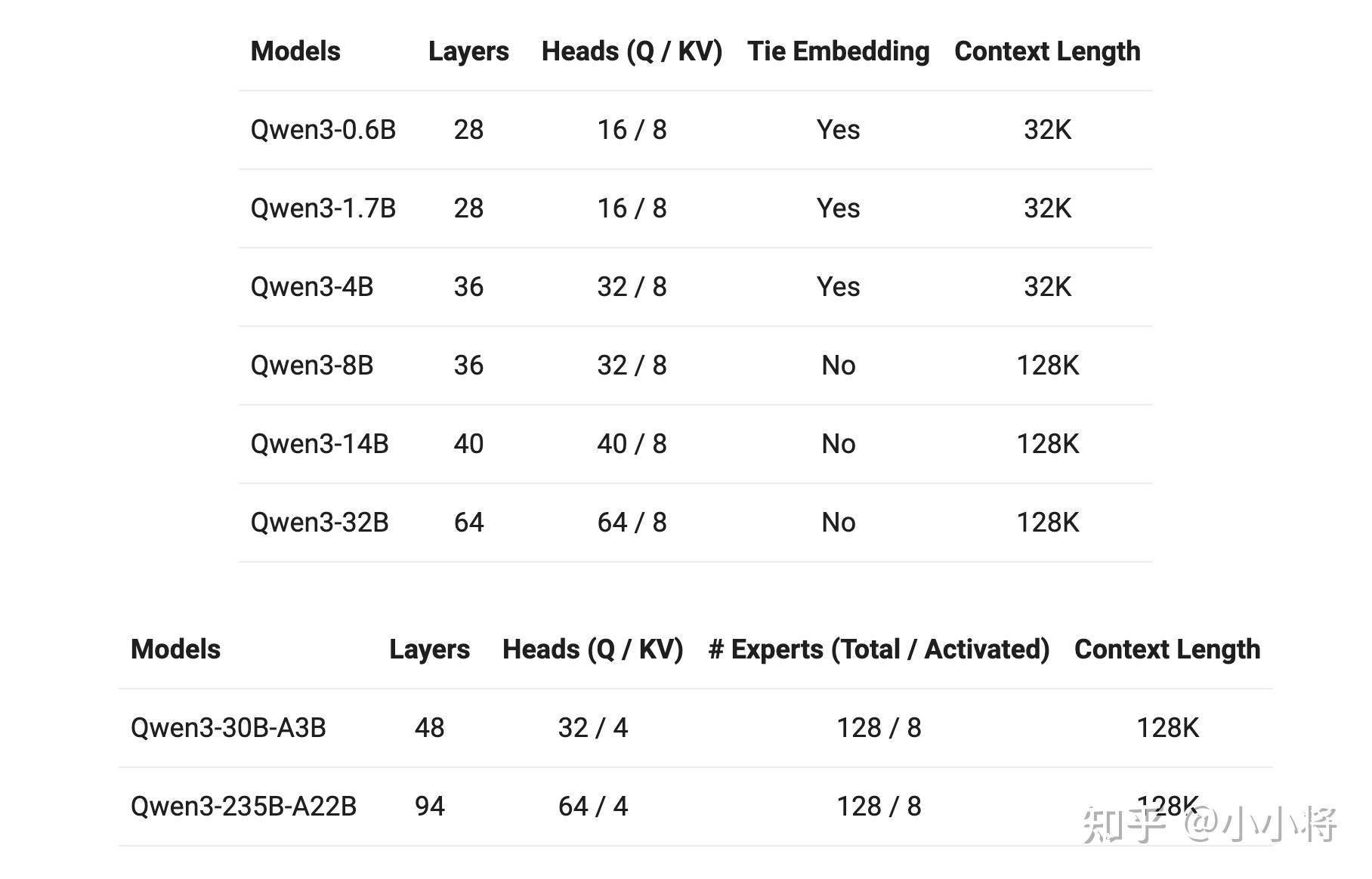


而且,这次Qwen3系列模型均是Apache 2.0 许可下开源,所以可以直接商用。
另外,虽然Qwen3的技术报告没出,这里也简单看了一下Qwen3博客中对于模型训练的介绍。首先,Qwen3的预训练数据量是36T,比之前Qwen2.5所用的18T大了一倍,为了扩充数据量,这里也使用Qwen2.5-VL从 PDF 文档中提取信息。预训练过程分为三个阶段:
在第一阶段(S1),模型在超过 30 万亿个 token 上进行了预训练,上下文长度为 4K token。这一阶段为模型提供了基本的语言技能和通用知识。在第二阶段(S2),我们通过增加知识密集型数据(如 STEM、编程和推理任务)的比例来改进数据集,随后模型又在额外的 5 万亿个 token 上进行了预训练。在最后阶段,我们使用高质量的长上下文数据将上下文长度扩展到 32K token,确保模型能够有效地处理更长的输入。
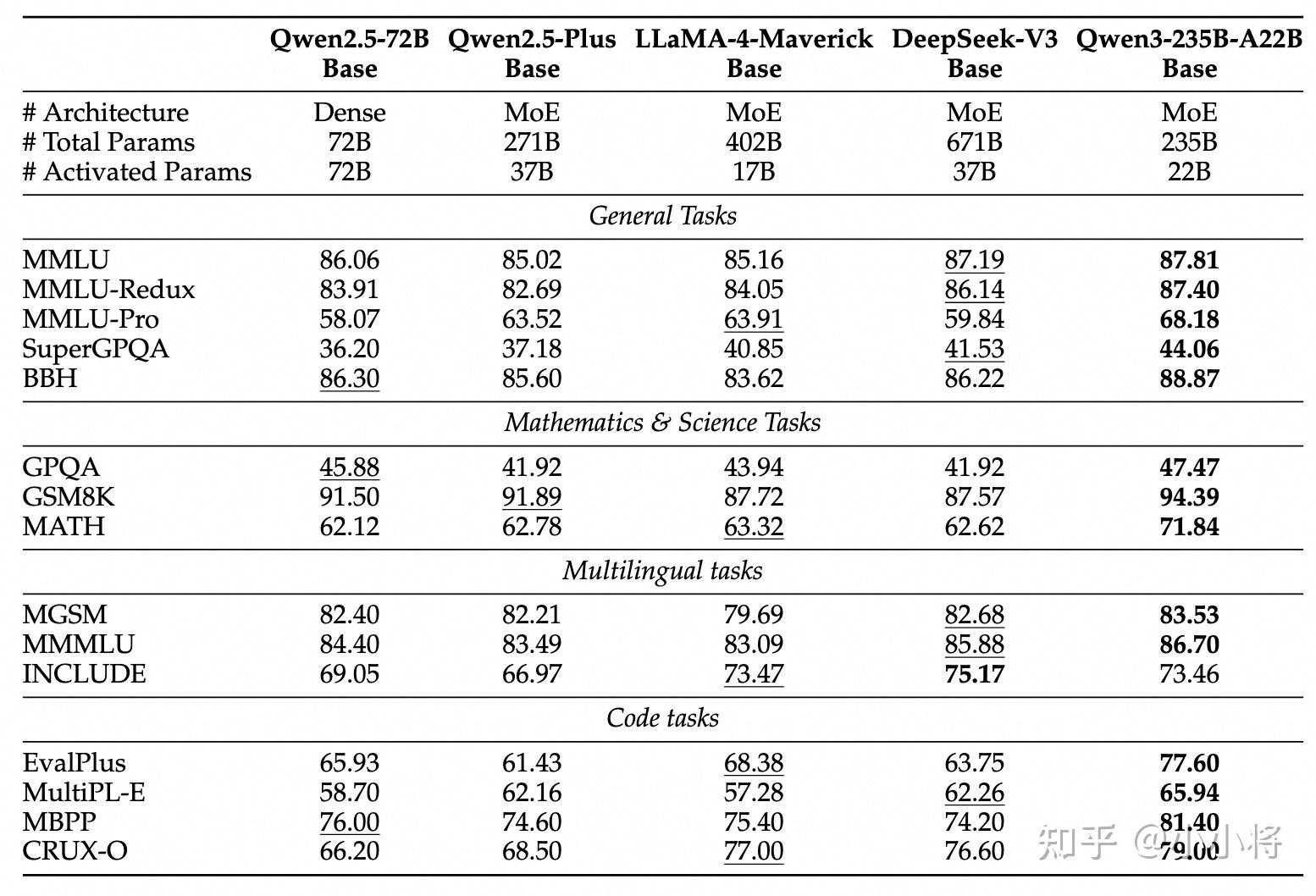
其中Qwen3-235B-A22B的预训练模型效果已经超过了DeepSeek-V3-Base,不过我看了一眼,目前Qwen3-235B-A22B和Qwen3-32B两个的Base模型没有开源,其他模型的Base模型开源了。

后训练包含四阶段的训练流程:(1)长思维链冷启动,(2)长思维链强化学习,(3)思维模式融合,以及(4)通用强化学习。
在第一阶段,我们使用多样的的长思维链数据对模型进行了微调,涵盖了数学、代码、逻辑推理和 STEM 问题等多种任务和领域。这一过程旨在为模型配备基本的推理能力。第二阶段的重点是大规模强化学习,利用基于规则的奖励来增强模型的探索和钻研能力。在第三阶段,我们在一份包括长思维链数据和常用的指令微调数据的组合数据上对模型进行微调,将非思考模式整合到思考模型中。确保了推理和快速响应能力的无缝结合。最后,在第四阶段,我们在包括指令遵循、格式遵循和 Agent 能力等在内的 20 多个通用领域的任务上应用了强化学习,以进一步增强模型的通用能力并纠正不良行为。

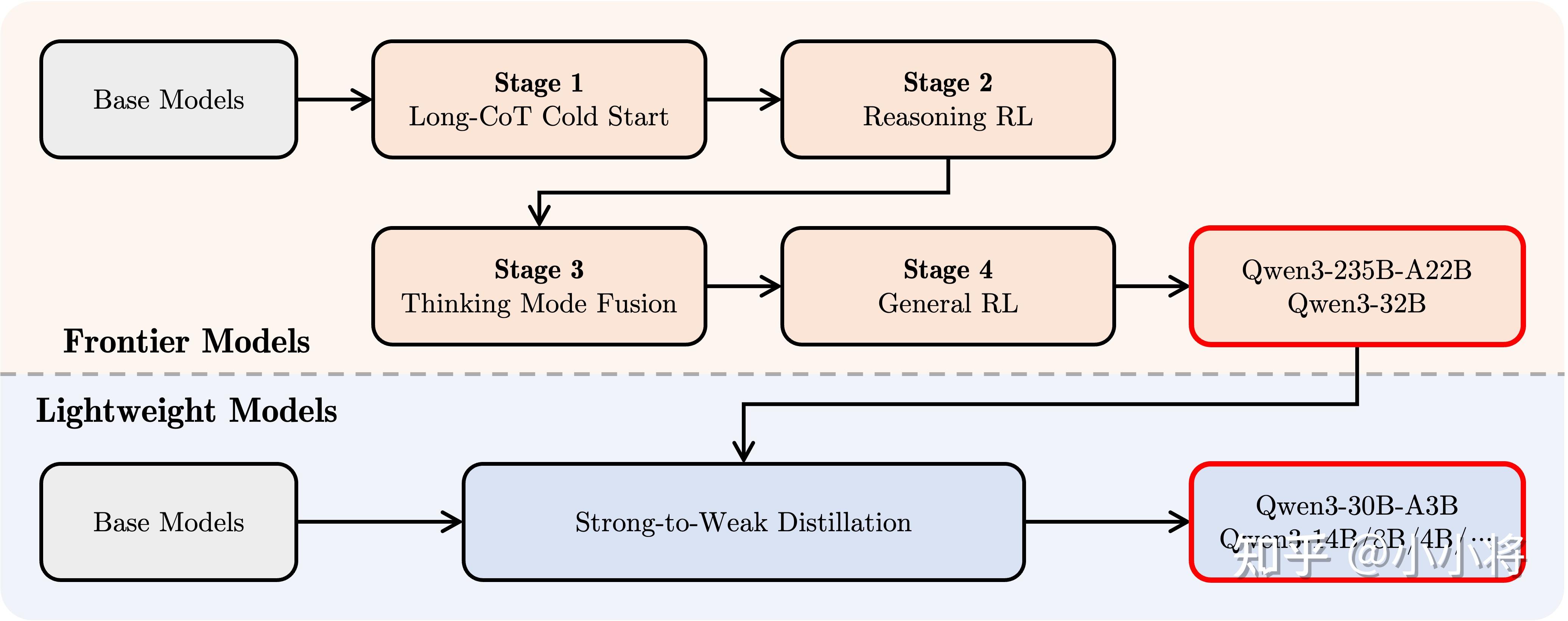
其中小模型也用了大模型来蒸馏增强性能。
简单实测了一下,效果还可以:



