我会使用尽量少的数学符号描述梯度,着重于意义而非计算。一个直观的例子,在机器学习领域有个术语叫「梯度下降」,你可以想象在群山之中,某个山的半山腰有只小兔子打算使用梯度下降的思路去往这片群山最深的山谷里找水喝。
我们用变化率来描述下山时各个方向的山路有多陡峭,往下的的路越陡峭变化率越大。山路险远,小兔子下山的过程中每个方向山路的陡峭程度都不一样:
- 东边是万丈深渊,往东边的变化率就一百颗星;
- 南边是下缓坡,往南方向的变化率小一些,三颗星;
- 西边是另一座山头要往上爬的,那么往西的变化率是负的十颗星;
- 北边是一个平地,变化率几乎为零,一颗星。
虽然东南西北各个方向都有变化率,但梯度下降的思想就是通过梯度最快的收敛,而梯度就是这几个方向中变化率最大的方向和值(为什么最大后面会说明),注意梯度同时描述了两个值,方向和大小,是个向量。放在这里,梯度就是东边和一百颗星。
然后梯度下降的思想就指导着我们的小兔子向东走,于是它轻轻一跃,移动了大约一万丈,没什么比直接跳下去更快能喝到水的了 = =。
梯度下降过程就是小兔子找水喝的过程。
机器学习领域,我们有一个步长(记为,发音 gamma 通常取值在 0 - 1 之间)是人为设定的值,它与梯度(记为
,发音 grad)相乘,就可以描述小兔子每蹦跶一下该往某个方向跳以及一下跳了多远了。
上边的说明可以用来感性的感受一下梯度是啥,和梯度下降是想要干嘛。
数学的视角描述梯度
一元函数
刚才的例子也说了变化率描述山路的陡峭程度,放在函数里,描述函数变化率的东东就是函数的导数。在一元函数里,我们的函数就是从左到右的一根线,方向已经固定了,没有东南西北可言,所以对于一元函数而言,函数 在
点处的梯度,等于该函数的导数在
点处的值,即
,记为
。说白了就是方向上没得选,于是梯度直接等于导数。
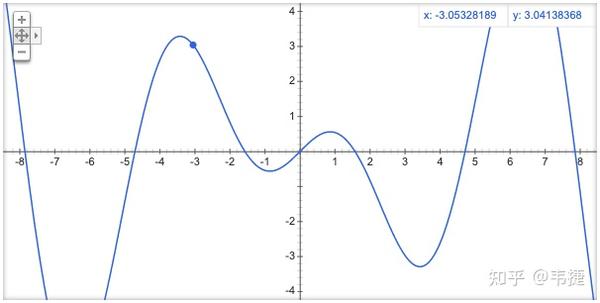
如果我们要在一元函数中梯度下降不断的执行直到收敛就差不多好了
在这里是赋值运算符,
,
就是我们小兔子在的位置
多元函数
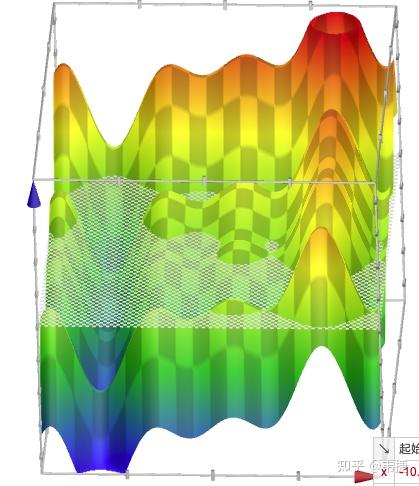
在一元函数里,因为只有一个方向,所以直接使用导数就可以描述变化率了。而在多元函数里,就像在一开始的例子中,我们的小兔子是可以往东南西北甚至更多的方向蹦跶的,是个 3D 游戏。而每个方向山路的陡峭程度不一样,于是就需要引入方向导数的概念。方向导数描述了函数图像在指定方向上的陡峭程度,也可以说成函数图像在指定方向上的变化率,是个数值。根据之前小兔子的例子,我们很容易猜出来,此时的梯度(又叫梯度向量)就是所有方向中变化率最大的方向和值,它同时描述了值和方向,是个向量。
在梯度下降指导我们在各个可能的方向中,每次都选择变化率最大的方向,即梯度指向的方向前进,这样做就能较快速的找到函数的局部或全局最优解。
如果存粹想要了解梯度干嘛用,看到这里就可以了。
数学符号预警!
接下来用数学语言解释一下为什么梯度就是所有方向中变化率最大的那个向量,然后在观赏下所有教程中都会甩出来的经典梯度公式。
单位向量,梯度,方向导数
单位向量:单位向量是长度或者模为 1 的向量,在这里用来描述方向导数的方向,记作 ,它各个分量的平方和再开根号的值是 1。例如:单位向量
那么它的模(记作
),有
。
梯度: 函数 的梯度,记作
,是由求
在对求各个参数求偏导而得到的向量,即:
, 其中
是多元函数
的参数,将点
带入
中能得到函数
在
点的梯度,记做
。
方向导数:函数 在点
处的朝着方向
的方向导数,记作(
)。是梯度和单位向量
的点积,即
,是个数值,用来描述函数
在点
处的朝着方向
的变化率。
梯度和方向导数的关系
根据上面对方向导数的描述,我们使用高中的向量相乘的知识,能得到梯度和方向导数有如下关系:
![D_{\textbf{u}P} f = \nabla f|_{P} \bullet \textbf{u} = \left| \nabla f|_{P} \right| \left| \textbf{u} \right| cos\theta = \left| \nabla f|_{P} \right| cos\theta]()
这里的是
和梯度之间的夹角,单位向量的模等于 1
上面的公式看上去虽然比较丑,但揭示的东西显而易见:
- 当
等于 1 时也就是方向导数的方向
和梯度的夹角为 0 时,有
,此时该方向导数的值最大,我们得出了最经典的结论「函数
在
处沿着其梯度的方向增加最快」,这就是梯度下降中指导我们收敛的规律。
- 当
等于 -1 时也就是
与梯度的夹角为
时,有
,我们得出结论「函数
在
处沿着其梯度相反的方向减少最快」。
- 当
等于 0 时也就是
与梯度垂直时,有
,我们得出「函数
在
处沿着其梯度垂直方向上的变化率为 0」。
常见梯度公式 ![\nabla f = \frac{\partial f}{\partial x}\textbf{i} + \frac{\partial f}{\partial y}\textbf{j}]() 的由来
的由来
接下来我们看一下很多教程中都会甩出来的梯度公式 的前世今生。
有二元函数 ,
根据梯度的定义,那么它的梯度是
向量标准化后 ,这里
,就得到了这个公式。
本文到此为止结束。
才怪。
不想知道为啥方向导数等于梯度和方向向量的点乘的小伙伴,读到这里就好,本文结束,睡个好觉。
更多的数学符号预警!
梯度 ![\nabla f|_{p}]() 的定义以及方向导数
的定义以及方向导数 ![D_{\textbf{up}} f]() 的定义及公式
的定义及公式 ![D_{\textbf{up}} f = \nabla f|_{p} \bullet \textbf{u}]() 的由来
的由来
方向导数 ![D_{\textbf{up}} f]() 的定义式
的定义式
上边直接将方向导数描述为梯度和方向向量的点乘,实际上一开始并非如此,方向导数有自己的定义式,从定义式到上边的点乘公式的过程,在很多高数教材里面给出了很刺激的推导,这里介绍其中一种。
回忆一下一元函数 在
处的导数的定义:
高中时候的经典公式,相信大家已经对它很熟了。
再看看多元函数 在点
处沿着方向
的方向导数的定义:
这里有单位向量 表示方向,我们忽略向量和点符号的不同,将点
表示为
,最后将
类比一元导数公式中的
,简化一下上面公式的写法,就成了:
现在是不是变得跟一元导数公式大同小异了呢,把一元变成了多元,然后加入了方向向量对变化的方向进行了描述。记住这个定义式,我们最后推导的时候会用到。
局部线性与梯度
一元函数局部线性
回到一元函数 ,我们的一元函数如果是过点
和点
的直线,那么导数就是这个直线的斜率,通过两点式我们有:
但如果我们的 不是直线,
也是函数
在
处的切线的斜率, 于是之前推导出来的
,就成了切线方程,既然是切线那么我们引入一个误差记作
(
发音 epsilon 表示一个很小很小很小的数),令切线方程加上这个误差就是我们函数的实际值,有:
,
同时我们也能想象,切线离切点越近的地方,误差值的值就会越小,即 。
多元函数局部线性
在多元函数中我们也能使用类似的近似表达,定义点 ,
并且误差
那么我们有:
你看中间 里的内容,是不是很眼熟,你猜得没错,中间的内容就叫梯度。
我们一会儿会用到这个公式,来做最后的推导。这里的梯度 和一元函数中的
一脉相承,在一元函数里,梯度就是切线的斜率,现在理解为什么之前要说一元函数里导数的值就是梯度的值了吗,二元函数中梯度就成了切面的“斜率”,三元函数中呢,切体吗哎哟。
![D_{\textbf{up}} f = \nabla f|_{p} \bullet \textbf{u}]() 的由来
的由来
(刚才的多元函数微分近似)
(将
改写成
,即将向量表示为单位向量乘以某个数的形式)
当 时
(根据方向导数的定义式代换)
本文讨论的函数都是连续可导的,或者在某些区间内连续可导的。
以上数学知识绝大部分来自《托马斯微积分》,是本非常适合自学的高数教材,想了解更多推荐购买,但是更关键的知识来自《数学分析新讲》--我们永远想念张筑生教授。